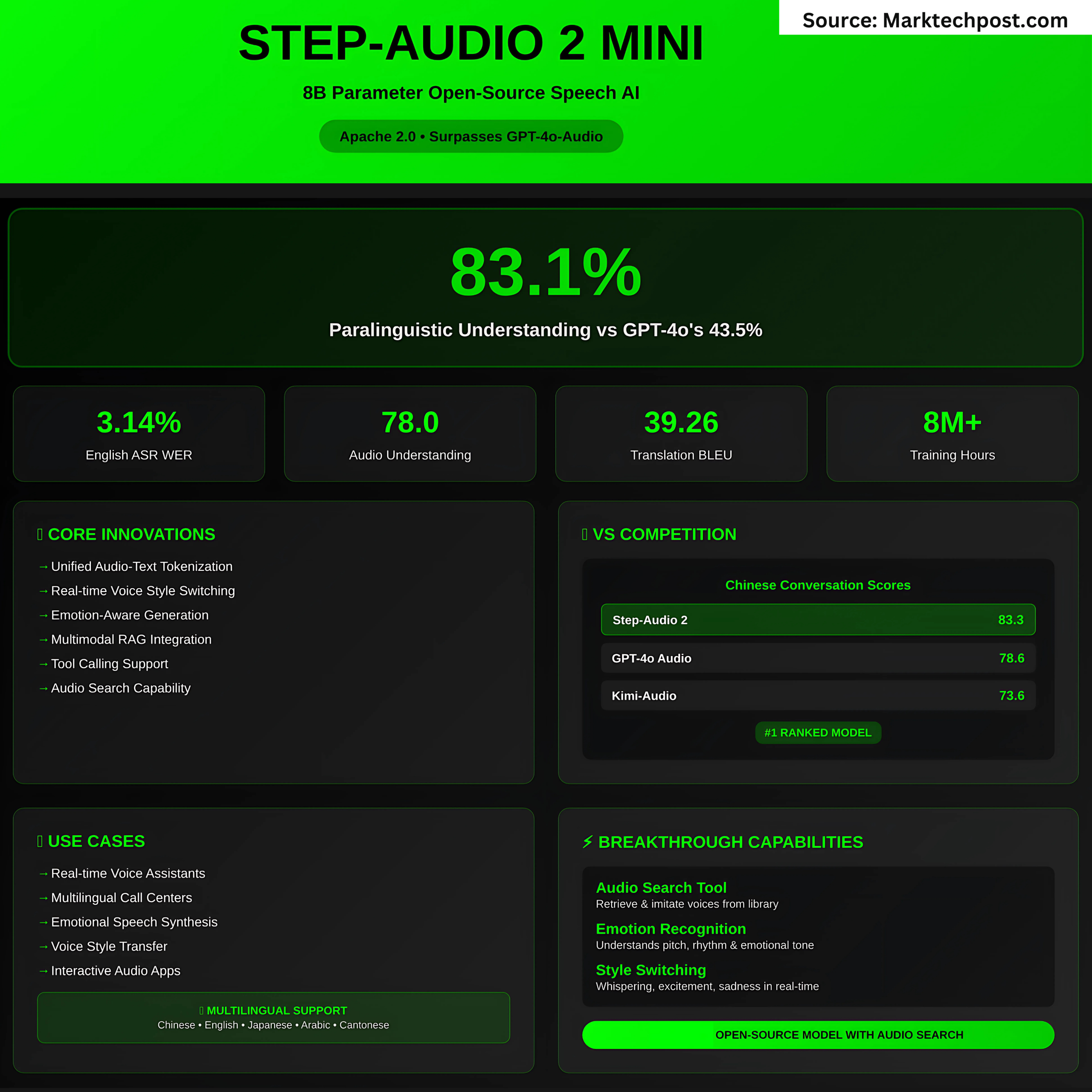
The StepFun AI staff has launched Step-Audio 2 Mini, an 8B parameter speech-to-speech massive audio language mannequin (LALM) that delivers expressive, grounded, and real-time audio interplay. Launched below the Apache 2.0 license, this open-source mannequin achieves state-of-the-art efficiency throughout speech recognition, audio understanding, and speech dialog benchmarks—surpassing business methods comparable to GPT-4o-Audio.
Key Options
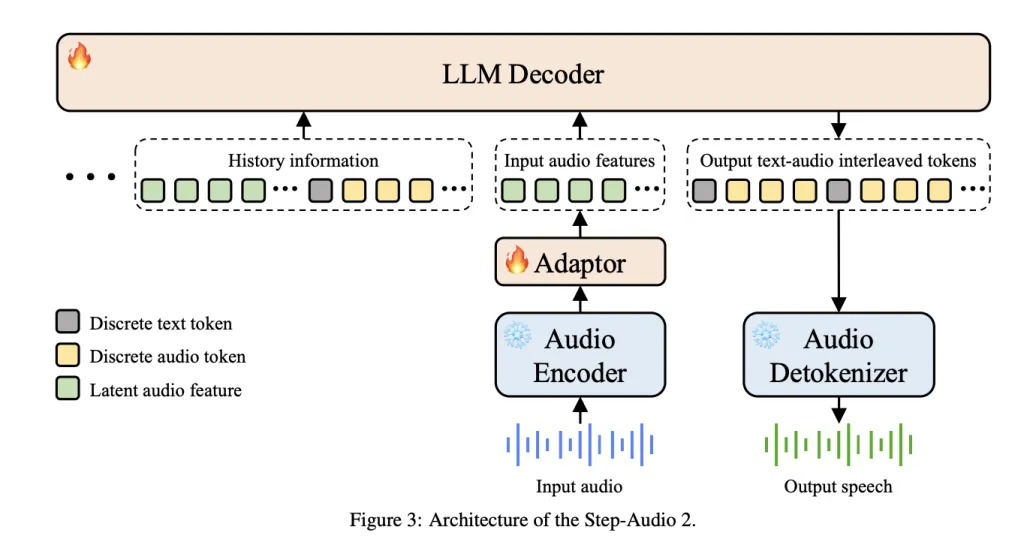
1. Unified Audio–Textual content Tokenization
Not like cascaded ASR+LLM+TTS pipelines, Step-Audio 2 integrates Multimodal Discrete Token Modeling, the place textual content and audio tokens share a single modeling stream.
This permits:
- Seamless reasoning throughout textual content and audio.
- On-the-fly voice model switching throughout inference.
- Consistency in semantic, prosodic, and emotional outputs.
2. Expressive and Emotion-Conscious Technology
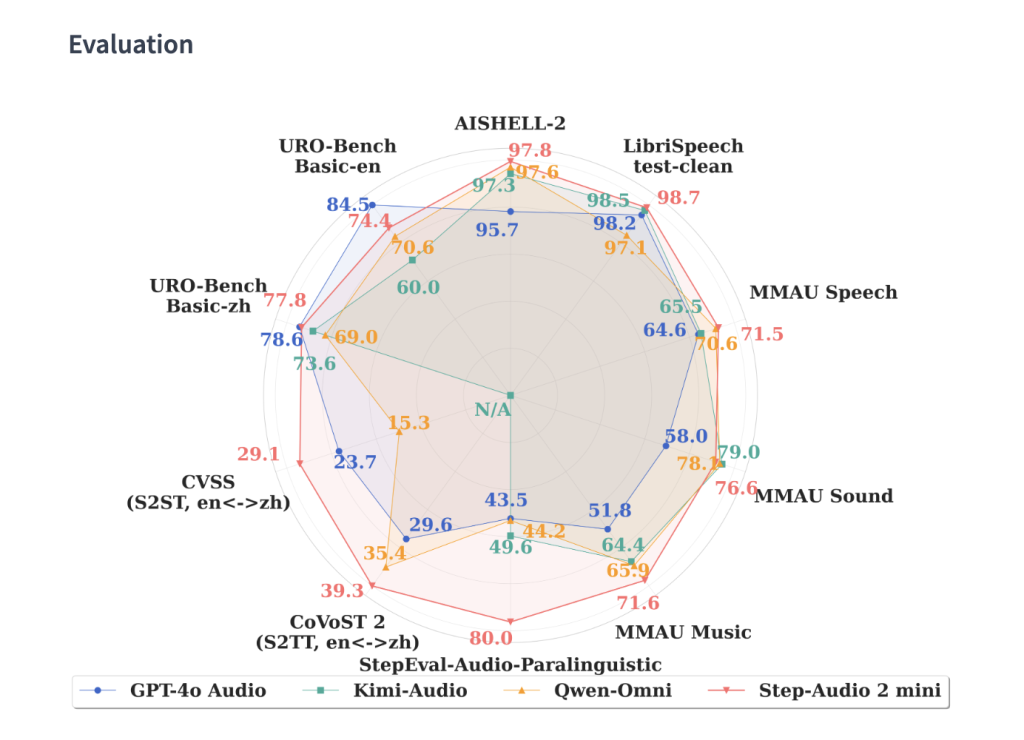
The mannequin doesn’t simply transcribe speech—it interprets paralinguistic options like pitch, rhythm, emotion, timbre, and magnificence. This permits conversations with real looking emotional tones comparable to whispering, disappointment, or pleasure. Benchmarks on StepEval-Audio-Paralinguistic present Step-Audio 2 reaching 83.1% accuracy, far past GPT-4o Audio (43.5%) and Qwen-Omni (44.2%).
3. Retrieval-Augmented Speech Technology
Step-Audio 2 incorporates multimodal RAG (Retrieval-Augmented Technology):
- Net search integration for factual grounding.
- Audio search—a novel functionality that retrieves actual voices from a big library and fuses them into responses, enabling voice timbre/model imitation at inference time.
4. Instrument Calling and Multimodal Reasoning
The system extends past speech synthesis by supporting device invocation. Benchmarks present that Step-Audio 2 matches textual LLMs in device choice and parameter accuracy, whereas uniquely excelling at audio search device calls—a functionality unavailable in text-only LLMs.
Coaching and Information Scale
- Textual content + Audio Corpus: 1.356T tokens
- Audio Hours: 8M+ actual and artificial hours
- Speaker Range: ~50K voices throughout languages and dialects
- Pretraining Pipeline: multi-stage curriculum protecting ASR, TTS, speech-to-speech translation, and emotion-labeled conversational synthesis.
This huge-scale coaching permits Step-Audio 2 Mini to retain sturdy textual content reasoning (through its Qwen2-Audio and CosyVoice basis) whereas mastering fine-grained audio modeling.
Efficiency Benchmarks
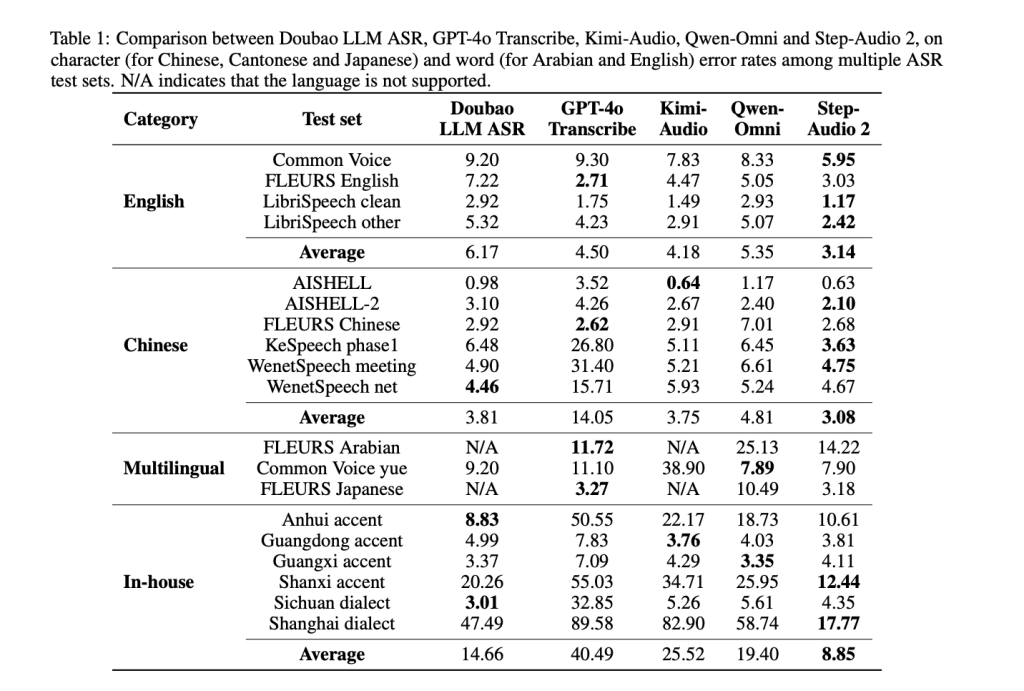
Automated Speech Recognition (ASR)
- English: Common WER 3.14% (beats GPT-4o Transcribe at a mean 4.5%).
- Chinese language: Common CER 3.08% (considerably decrease than GPT-4o and Qwen-Omni).
- Sturdy throughout dialects and accents.
Audio Understanding (MMAU Benchmark)
- Step-Audio 2: 78.0 common, outperforming Omni-R1 (77.0) and Audio Flamingo 3 (73.1).
- Strongest in sound and speech reasoning duties.
Speech Translation
- CoVoST 2 (S2TT): BLEU 39.26 (highest amongst open and closed fashions).
- CVSS (S2ST): BLEU 30.87, forward of GPT-4o (23.68).
Conversational Benchmarks (URO-Bench)
- Chinese language Conversations: Finest total at 83.3 (fundamental) and 68.2 (professional).
- English Conversations: Aggressive with GPT-4o (83.9 vs. 84.5), far forward of different open fashions.
Conclusion
Step-Audio 2 Mini makes superior, multimodal speech intelligence accessible to the builders and analysis group. By combining Qwen2-Audio’s reasoning capability with CosyVoice’s tokenization pipeline, and augmenting with retrieval-based grounding, StepFun has delivered probably the most succesful open audio LLMs.
Try the PAPER and MODEL on HUGGING FACE. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Publication.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.











{kind=link}