Most textual content to video fashions generate a single clip from a immediate after which cease. They don’t preserve an inside world state that persists as actions arrive over time. PAN, a brand new mannequin from MBZUAI’s Institute of Basis Fashions, is designed to fill that hole by performing as a normal world mannequin that predicts future world states as video, conditioned on historical past and pure language actions.
From video generator to interactive world simulator
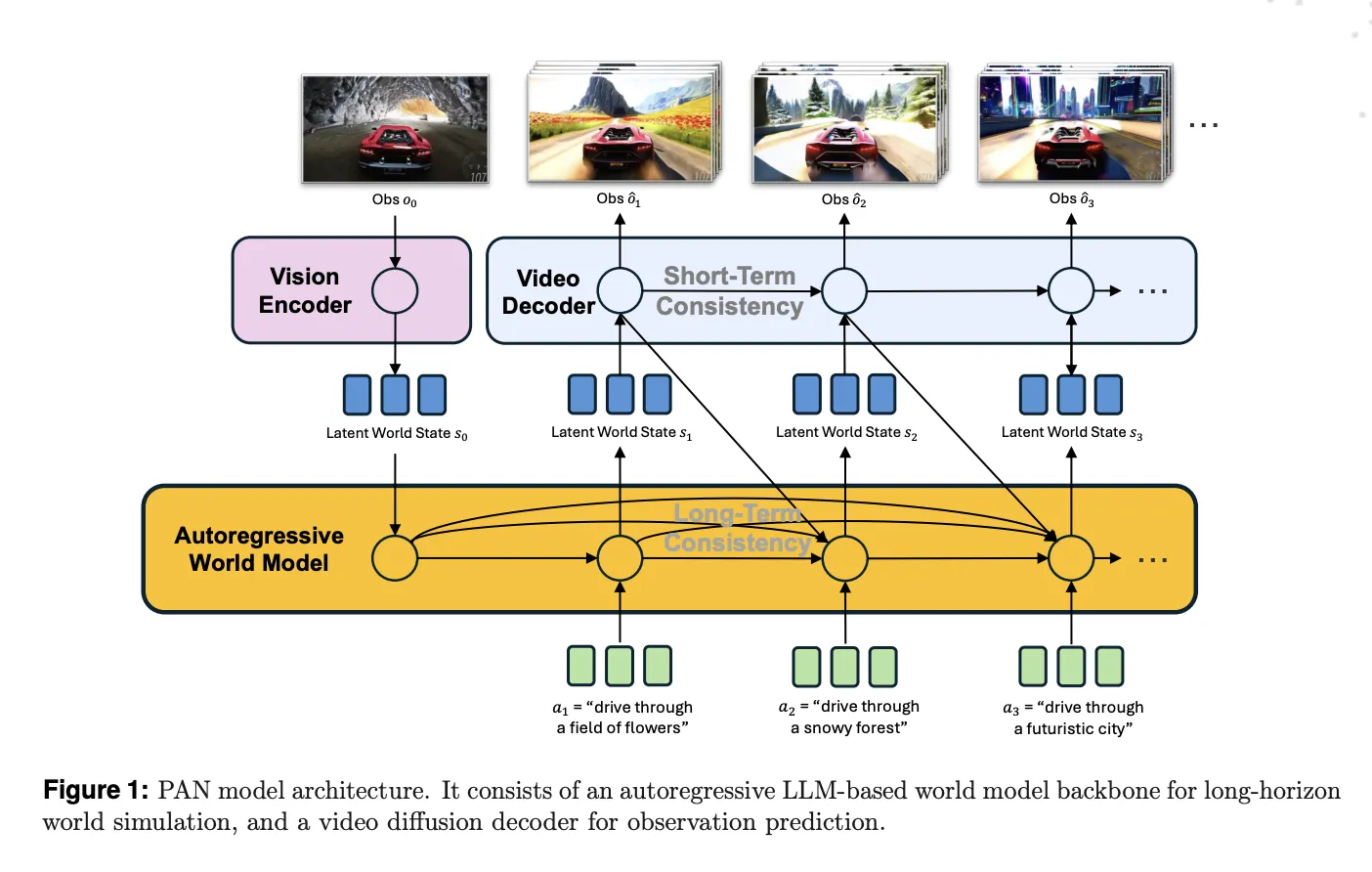
PAN is outlined as a normal, interactable, lengthy horizon world mannequin. It maintains an inside latent state that represents the present world, then updates that state when it receives a pure language motion corresponding to ‘flip left and velocity up’ or ‘transfer the robotic arm to the purple block.’ The mannequin then decodes the up to date state into a brief video phase that reveals the consequence of that motion. This cycle repeats, so the identical world state evolves throughout many steps.
This design permits PAN to assist open area, motion conditioned simulation. It might probably roll out counterfactual futures for various motion sequences. An exterior agent can question PAN as a simulator, evaluate predicted futures, and select actions based mostly on these predictions.
GLP structure, separating what occurs from the way it seems to be
The bottom of PAN is the Generative Latent Prediction, GLP, structure. GLP separates world dynamics from visible rendering. First, a imaginative and prescient encoder maps pictures or video frames right into a latent world state. Second, an autoregressive latent dynamics spine based mostly on a big language mannequin predicts the following latent state, conditioned on historical past and the present motion. Third, a video diffusion decoder reconstructs the corresponding video phase from that latent state.
In PAN, the imaginative and prescient encoder and spine are constructed on Qwen2.5-VL-7B-Instruct. The imaginative and prescient tower tokenizes frames into patches and produces structured embeddings. The language spine runs over a historical past of world states and actions, plus discovered question tokens, and outputs the latent illustration of the following world state. These latents dwell within the shared multimodal area of the VLM, which helps floor the dynamics in each textual content and imaginative and prescient.
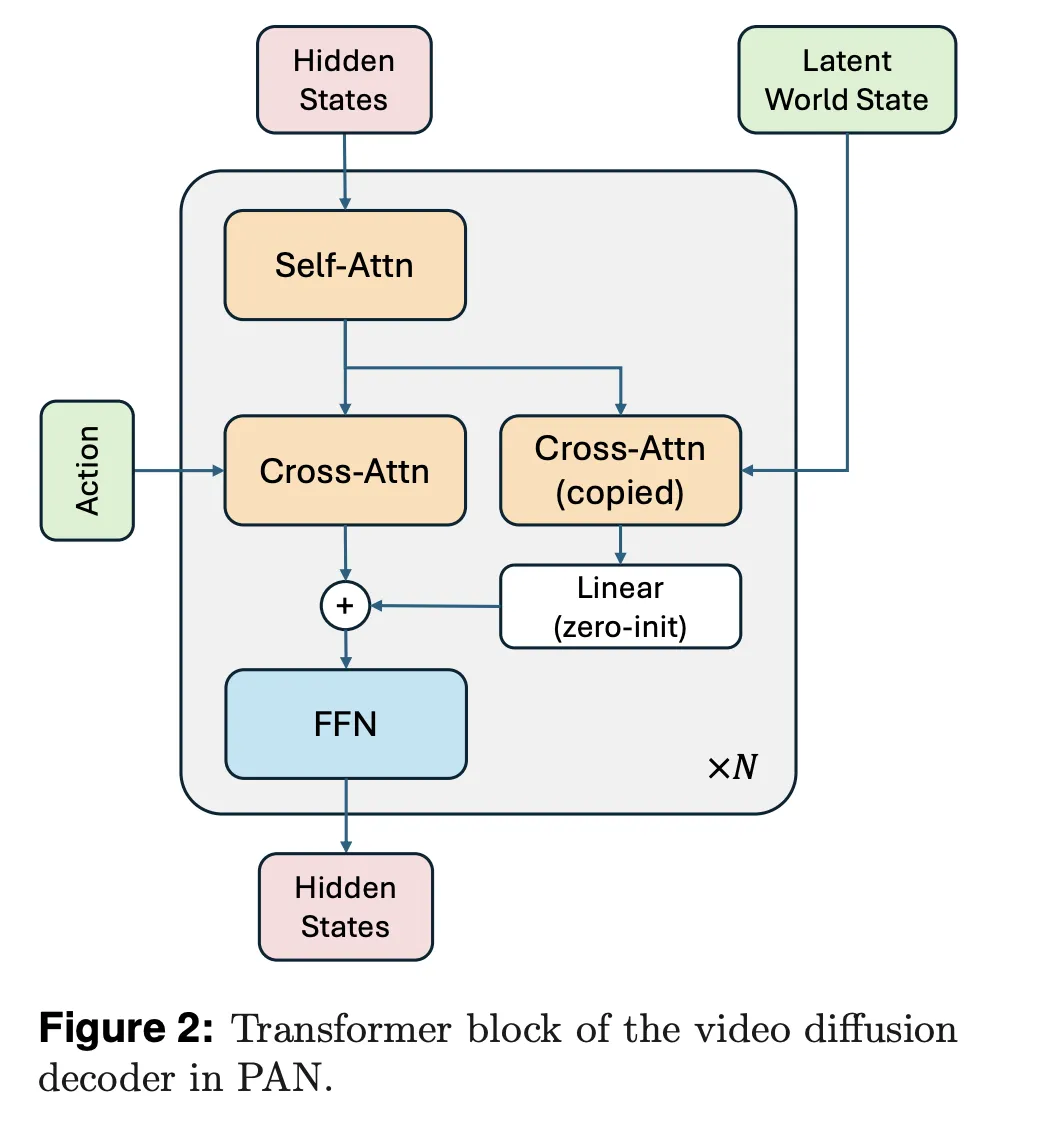
The video diffusion decoder is customized from Wan2.1-T2V-14B, a diffusion transformer for top constancy video era. The analysis workforce trains this decoder with a move matching goal, utilizing one thousand denoising steps and a Rectified Circulate formulation. The decoder circumstances on each the expected latent world state and the present pure language motion, with a devoted cross consideration stream for the world state and one other for the motion textual content.
Causal Swin DPM and sliding window diffusion
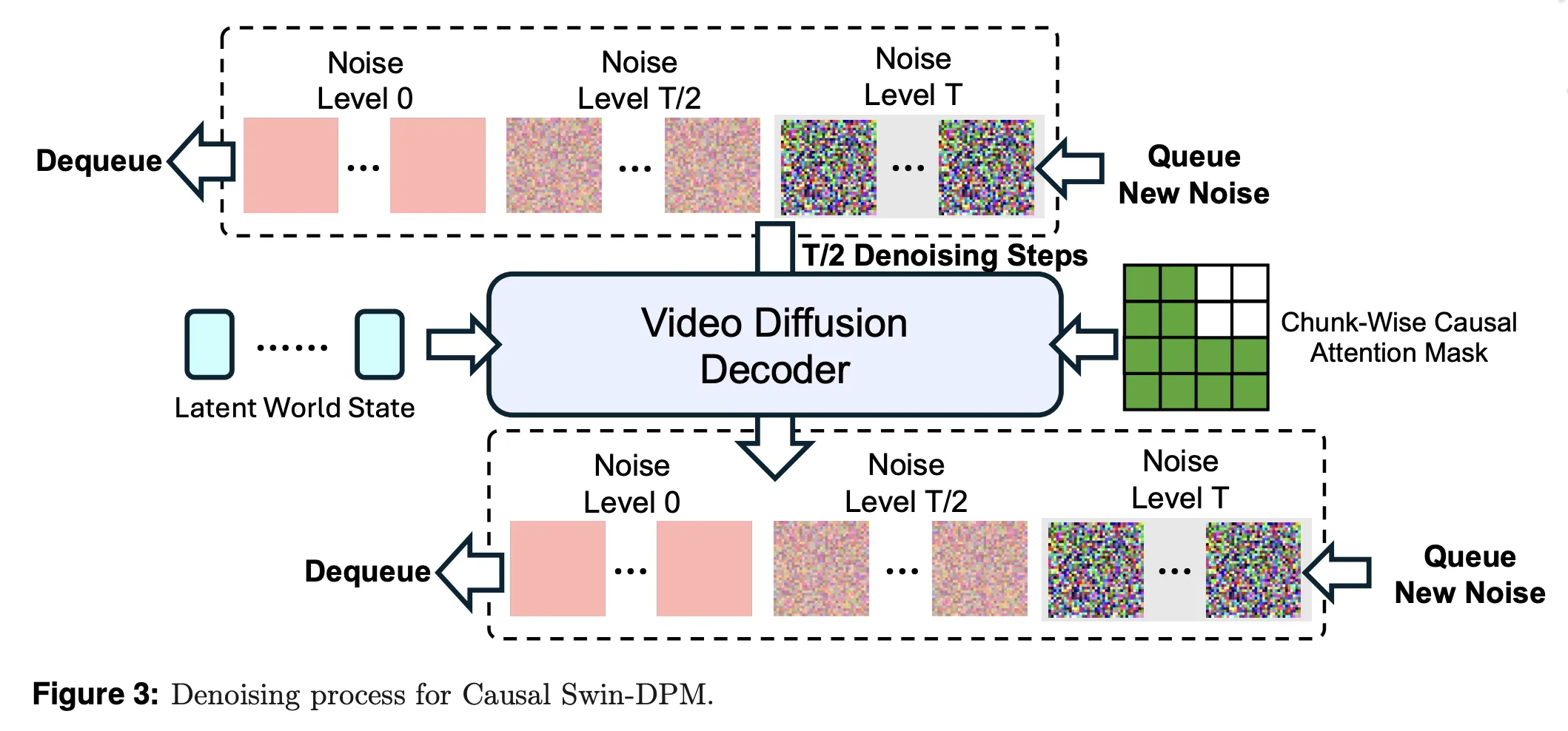
Naively chaining single shot video fashions by conditioning solely on the final body results in native discontinuities and speedy high quality degradation over lengthy rollouts. PAN addresses this with Causal Swin DPM, which augments the Shift Window Denoising Course of Mannequin with chunk clever causal consideration.
The decoder operates on a sliding temporal window that holds two chunks of video frames at completely different noise ranges. Throughout denoising, one chunk strikes from excessive noise to scrub frames after which leaves the window. A brand new noisy chunk enters on the different finish. Chunk clever causal consideration ensures that the later chunk can solely attend to the sooner one, to not unseen future actions. This retains transitions between chunks easy and reduces error accumulation over lengthy horizons.
PAN additionally provides managed noise to the conditioning body, quite than utilizing a wonderfully sharp body. This suppresses incidental pixel particulars that don’t matter for dynamics and encourages the mannequin to deal with secure construction corresponding to objects and format.
Coaching stack and knowledge development
PAN is skilled in two phases. Within the first stage, the analysis workforce adapts Wan2.1 T2V 14B into the Causal Swin DPM structure. They prepare the decoder in BFloat16 with AdamW, a cosine schedule, gradient clipping, FlashAttention3 and FlexAttention kernels, and a hybrid sharded knowledge parallel scheme throughout 960 NVIDIA H200 GPUs.
Within the second stage, they combine the frozen Qwen2.5 VL 7B Instruct spine with the video diffusion decoder underneath the GLP goal. The imaginative and prescient language mannequin stays frozen. The mannequin learns question embeddings and the decoder in order that predicted latents and reconstructed movies keep constant. This joint coaching additionally makes use of sequence parallelism and Ulysses model consideration sharding to deal with lengthy context sequences. Early stopping ends coaching after 1 epoch as soon as validation converges, though the schedule permits 5 epochs.
Coaching knowledge comes from broadly used publicly accessible video sources that cowl on a regular basis actions, human object interactions, pure environments, and multi agent eventualities. Lengthy type movies are segmented into coherent clips utilizing shot boundary detection. A filtering pipeline removes static or overly dynamic clips, low aesthetic high quality, heavy textual content overlays, and display screen recordings utilizing rule based mostly metrics, pretrained detectors, and a customized VLM filter. The analysis workforce then re-captions clips with dense, temporally grounded descriptions that emphasize movement and causal occasions.
Benchmarks, motion constancy, lengthy horizon stability, planning
The analysis workforce evaluates the mannequin alongside three axes, motion simulation constancy, lengthy horizon forecast, and simulative reasoning and planning, in opposition to each open supply and business video turbines and world fashions. Baselines embody WAN 2.1 and a pair of.2, Cosmos 1 and a pair of, V JEPA 2, and business techniques corresponding to KLING, MiniMax Hailuo, and Gen 3.
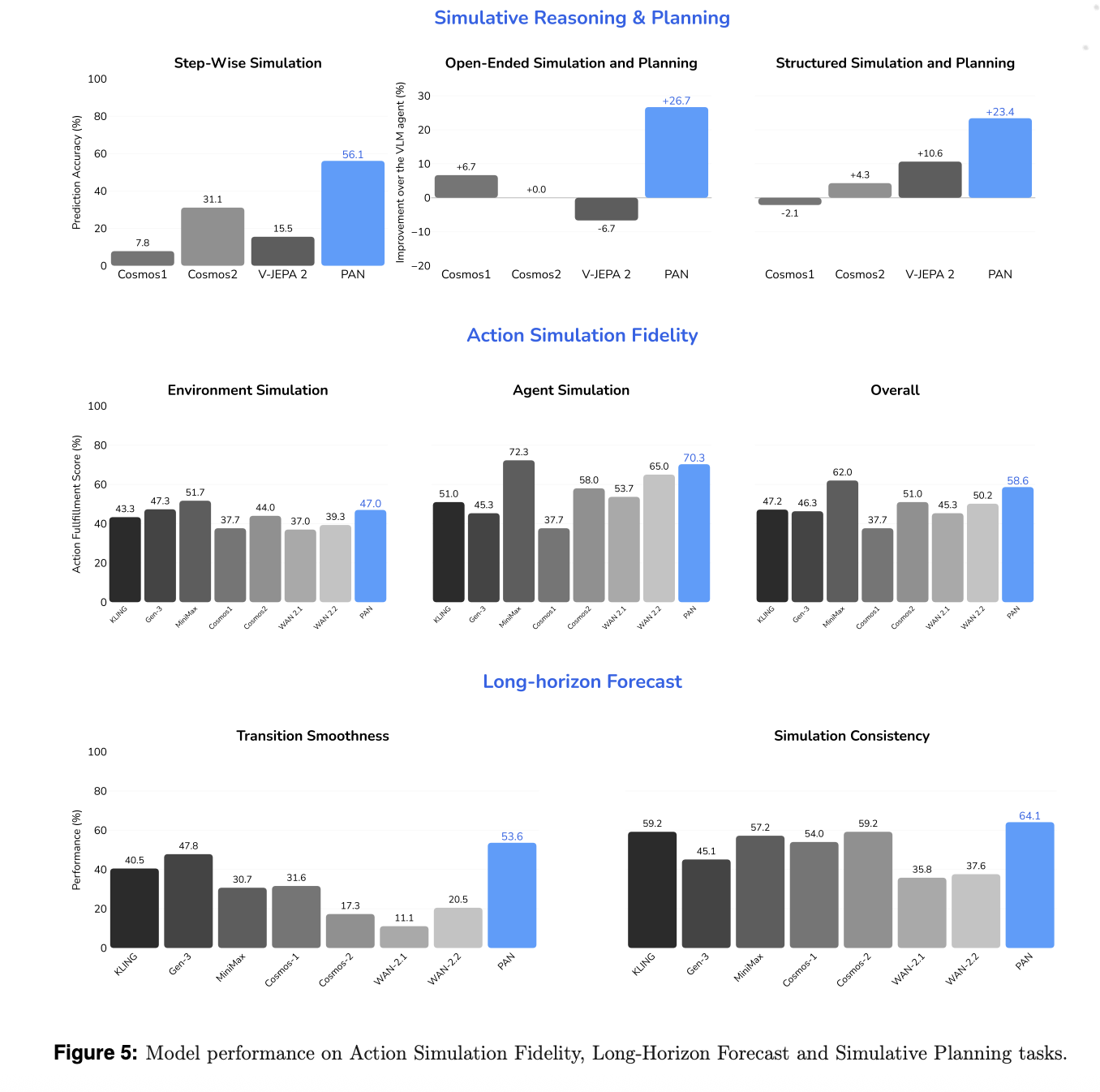
For motion simulation constancy, a VLM based mostly decide scores how effectively the mannequin executes language specified actions whereas sustaining a secure background. PAN reaches 70.3% accuracy on agent simulation and 47% on atmosphere simulation, for an total rating of 58.6%. It achieves the very best constancy amongst open supply fashions and surpasses most business baselines.
For lengthy horizon forecast, the analysis workforce measures Transition Smoothness and Simulation Consistency. Transition Smoothness makes use of optical move acceleration to quantify how easy movement is throughout motion boundaries. Simulation Consistency makes use of metrics impressed by WorldScore to observe degradation over prolonged sequences. PAN scores 53.6% on Transition Smoothness and 64.1% on Simulation Consistency and exceeds all baselines, together with KLING and MiniMax, on these metrics.
For simulative reasoning and planning, PAN is used as an inside simulator inside an OpenAI-o3 based mostly agent loop. In step clever simulation, PAN achieves 56.1% accuracy, the most effective amongst open supply world fashions.
Key Takwaways
- PAN implements the Generative Latent Prediction structure, combining a Qwen2.5-VL-7B based mostly latent dynamics spine with a Wan2.1-T2V-14B based mostly video diffusion decoder, to unify latent world reasoning and reasonable video era.
- The Causal Swin DPM mechanism introduces a sliding window, chunk clever causal denoising course of that circumstances on partially noised previous chunks, which stabilizes lengthy horizon video rollouts and reduces temporal drift in comparison with naive final body conditioning.
- PAN is skilled in two phases, first adapting the Wan2.1 decoder to Causal Swin DPM on 960 NVIDIA H200 GPUs with a move matching goal, then collectively coaching the GLP stack with a frozen Qwen2.5-VL spine and discovered question embeddings plus decoder.
- The coaching corpus consists of enormous scale video motion pairs from numerous domains, processed with segmentation, filtering, and dense temporal recaptioning, enabling PAN to study motion conditioned, lengthy vary dynamics as a substitute of remoted quick clips.
- PAN achieves cutting-edge open supply outcomes on motion simulation constancy, lengthy horizon forecasting, and simulative planning, with reported scores corresponding to 70.3% agent simulation, 47% atmosphere simulation, 53.6% transition smoothness, and 64.1% simulation consistency, whereas remaining aggressive with main business techniques.
Comparability Desk
| Dimension | PAN | Cosmos video2world WFM | Wan2.1 T2V 14B | V JEPA 2 |
|---|---|---|---|---|
| Group | MBZUAI Institute of Basis Fashions | NVIDIA Analysis | Wan AI and Open Laboratory | Meta AI |
| Major function | Common world mannequin for interactive, lengthy horizon world simulation with pure language actions | World basis mannequin platform for Bodily AI with video to world era for management and navigation | Top quality textual content to video and picture to video generator for normal content material creation and enhancing | Self supervised video mannequin for understanding, prediction and planning duties |
| World mannequin framing | Express GLP world mannequin, latent state, motion, and subsequent statement outlined, focuses on simulative reasoning and planning | Described as world basis mannequin that generates future video worlds from previous video and management immediate, geared toward Bodily AI, robotics, driving, navigation | Framed as video era mannequin, not primarily as world mannequin, no persistent inside world state described in docs | Joint embedding predictive structure for video, focuses on latent prediction quite than express generative supervision in statement area |
| Core structure | GLP stack, imaginative and prescient encoder from Qwen2.5 VL 7B, LLM based mostly latent dynamics spine, video diffusion decoder with Causal Swin DPM | Household of diffusion based mostly and autoregressive world fashions, with video2world era, plus diffusion decoder and immediate upsampler based mostly on a language mannequin | Spatio temporal variational autoencoder and diffusion transformer T2V mannequin at 14 billion parameters, helps a number of generative duties and resolutions | JEPA model encoder plus predictor structure that matches latent representations of consecutive video observations |
| Spine and latent area | Multimodal latent area from Qwen2.5 VL 7B, used each for encoding observations and for autoregressive latent prediction underneath actions | Token based mostly video2world mannequin with textual content immediate conditioning and non-obligatory diffusion decoder for refinement, latent area particulars rely on mannequin variant | Latent area from VAE plus diffusion transformer, pushed primarily by textual content or picture prompts, no express agent motion sequence interface | Latent area constructed from self supervised video encoder with predictive loss in illustration area, not generative reconstruction loss |
| Motion or management enter | Pure language actions in dialogue format, utilized at each simulation step, mannequin predicts subsequent latent state and decodes video conditioned on motion and historical past | Management enter as textual content immediate and optionally digicam pose for navigation and downstream duties corresponding to humanoid management and autonomous driving | Textual content prompts and picture inputs for content material management, no express multi step agent motion interface described as world mannequin management | Doesn’t deal with pure language actions, used extra as visible illustration and predictor module inside bigger brokers or planners |
| Lengthy horizon design | Causal Swin DPM sliding window diffusion, chunk clever causal consideration, conditioning on barely noised final body to scale back drift and keep secure lengthy horizon rollouts | Video2world mannequin generates future video given previous window and immediate, helps navigation and lengthy sequences however the paper doesn’t describe a Causal Swin DPM model mechanism | Can generate a number of seconds at 480 P and 720 P, focuses on visible high quality and movement, lengthy horizon stability is evaluated by means of Wan Bench however with out express world state mechanism | Lengthy temporal reasoning comes from predictive latent modeling and self supervised coaching, not from generative video rollouts with express diffusion home windows |
| Coaching knowledge focus | Massive scale video motion pairs throughout numerous bodily and embodied domains, with segmentation, filtering and dense temporal recaptioning for motion conditioned dynamics | Mixture of proprietary and public Web movies centered on Bodily AI classes corresponding to driving, manipulation, human exercise, navigation and nature dynamics, with a devoted curation pipeline | Massive open area video and picture corpora for normal visible era, with Wan Bench analysis prompts, not focused particularly at agent atmosphere rollouts | Massive scale unlabelled video knowledge for self supervised illustration studying and prediction, particulars in V JEPA 2 paper |
PAN is a vital step as a result of it operationalizes Generative Latent Prediction with manufacturing scale parts corresponding to Qwen2.5-VL-7B and Wan2.1-T2V-14B, then validates this stack on effectively outlined benchmarks for motion simulation, lengthy horizon forecasting, and simulative planning. The coaching and analysis pipeline is clearly documented by the analysis workforce, the metrics are reproducible, and the mannequin is launched inside a clear world modeling framework quite than as an opaque video demo. General, PAN reveals how a imaginative and prescient language spine plus diffusion video decoder can perform as a sensible world mannequin as a substitute of a pure generative toy.
Take a look at the Paper, Technical particulars and Challenge. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be part of us on telegram as effectively.
Max is an AI analyst at MarkTechPost, based mostly in Silicon Valley, who actively shapes the way forward for know-how. He teaches robotics at Brainvyne, combats spam with ComplyEmail, and leverages AI every day to translate complicated tech developments into clear, comprehensible insights











{kind=link}