Massive language fashions want big human datasets, so what occurs if the mannequin should create all its personal curriculum and educate itself to make use of instruments? A crew of researchers from UNC-Chapel Hill, Salesforce Analysis and Stanford College introduce ‘Agent0’, a totally autonomous framework that evolves high-performing brokers with out exterior information by multi-step co-evolution and seamless device integration
Agent0 targets mathematical and normal reasoning. It exhibits that cautious activity technology and gear built-in rollouts can push a base mannequin past its unique capabilities, throughout ten benchmarks.
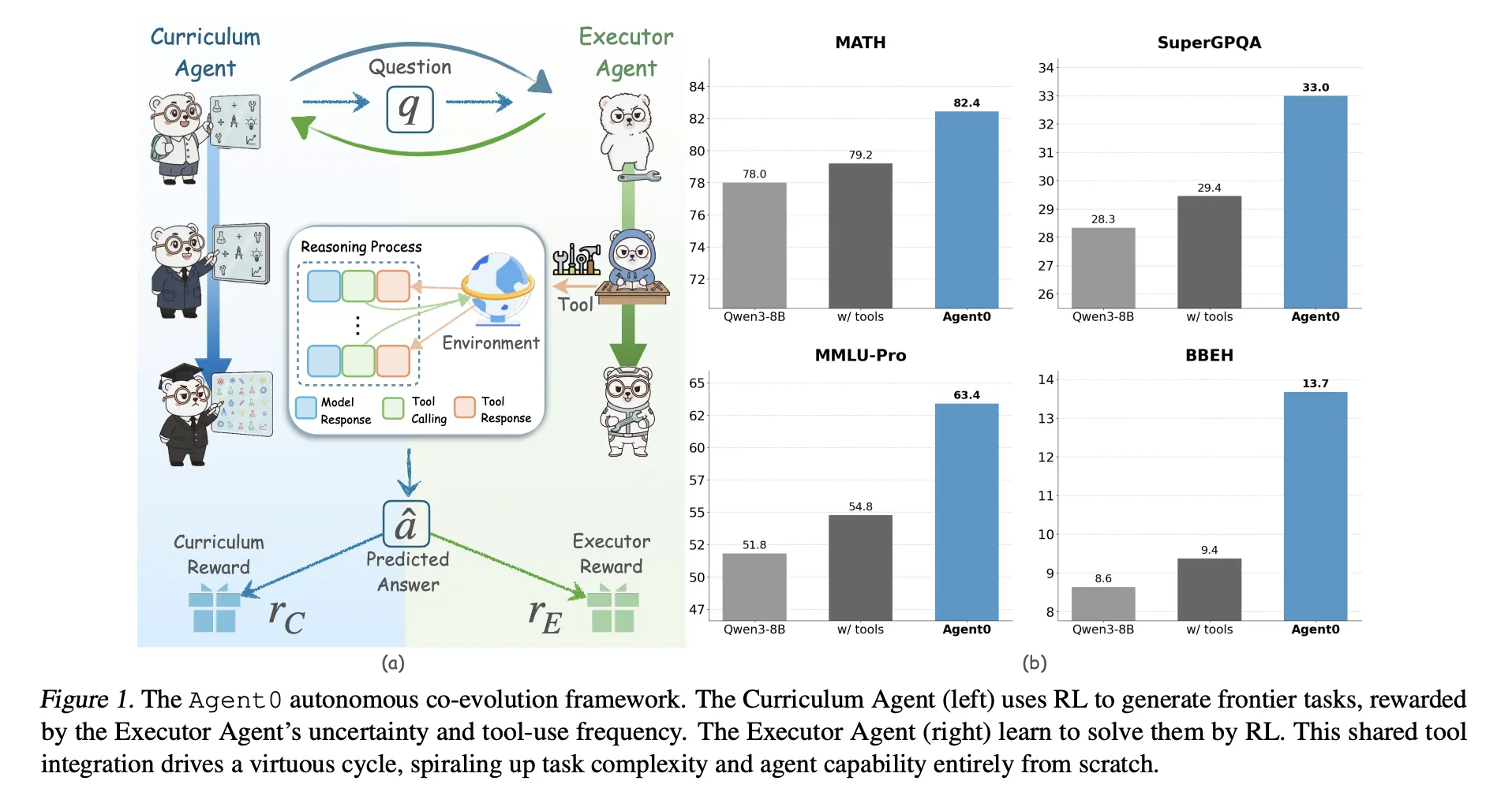
Two brokers from one base mannequin
Agent0 begins from a base coverage π_base, for instance Qwen3 4B Base or Qwen3 8B Base. It clones this coverage into:
- a Curriculum Agent πθ that generates duties,
- an Executor Agent πϕ that solves these duties with a Python device.
Coaching proceeds in iterations with two levels per iteration:
- Curriculum evolution: The curriculum agent generates a batch of duties. For every activity, the executor samples a number of responses. A composite reward measures how unsure the executor is, how usually it makes use of the device and the way various the batch is. πθ is up to date with Group Relative Coverage Optimization (GRPO) utilizing this reward.
- Executor evolution: The skilled curriculum agent is frozen. It generates a big pool of duties. Agent0 filters this pool to maintain solely duties close to the executor’s functionality frontier, then trains the executor on these duties utilizing an ambiguity conscious RL goal referred to as Ambiguity Dynamic Coverage Optimization (ADPO).
This loop creates a suggestions cycle. Because the executor turns into stronger by utilizing the code interpreter, the curriculum should generate extra complicated, device reliant issues to maintain its reward excessive.

How the curriculum agent scores duties?
The curriculum reward combines three alerts:
Uncertainty reward: For every generated activity x, the executor samples ok responses and majority votes a pseudo reply. Self consistency p̂(x) is the fraction of responses that agree with this majority. The reward is maximal when p̂ is near 0.5 and low when duties are too simple or too arduous. This encourages duties which might be difficult however nonetheless solvable for the present executor.
Instrument use reward: The executor can set off a sandboxed code interpreter utilizing python tags and receives outcomes tagged as output. Agent0 counts the variety of device calls in a trajectory and offers a scaled, capped reward, with a cap C set to 4 in experiments. This favors duties that really require device calls relatively than pure psychological arithmetic.
Repetition penalty: Inside every curriculum batch, Agent0 measures pairwise similarity between duties utilizing a BLEU based mostly distance. Duties are clustered, and a penalty time period will increase with cluster measurement. This discourages the curriculum from producing many close to duplicates.
A composite reward multiplies a format examine with a weighted sum of uncertainty and gear rewards minus the repetition penalty. This composite worth feeds into GRPO to replace πθ.
How the executor learns from noisy self labels?
The executor can be skilled with GRPO however on multi flip, device built-in trajectories and pseudo labels as an alternative of floor fact solutions.
Frontier dataset building: After curriculum coaching in an iteration, the frozen curriculum generates a big candidate pool. For every activity, Agent0 computes self consistency p̂(x) with the present executor and retains solely duties the place p̂ lies in an informative band, for instance between 0.3 and 0.8. This defines a difficult frontier dataset that avoids trivial or inconceivable issues.
Multi flip device built-in rollouts: For every frontier activity, the executor generates a trajectory that may interleave:
- pure language reasoning tokens,
pythoncode segments,outputdevice suggestions.
Era pauses when a device name seems, executes the code in a sandboxed interpreter constructed on VeRL Instrument, then resumes conditioned on the end result. The trajectory terminates when the mannequin produces a ultimate reply inside {boxed ...} tags.
A majority vote throughout sampled trajectories defines a pseudo label and a terminal reward for every trajectory.
ADPO, ambiguity conscious RL: Customary GRPO treats all samples equally, which is unstable when labels come from majority voting on ambiguous duties. ADPO modifies GRPO in two methods utilizing p̂ as an ambiguity sign.
- It scales the normalized benefit with an element that will increase with self consistency, so trajectories from low confidence duties contribute much less.
- It units a dynamic higher clipping sure for the significance ratio, which will depend on self consistency. Empirical evaluation exhibits that fastened higher clipping primarily impacts low likelihood tokens. ADPO relaxes this sure adaptively, which improves exploration on unsure duties, as visualized by the up clipped token likelihood statistics.

Outcomes on mathematical and normal reasoning
Agent0 is carried out on prime of VeRL and evaluated on Qwen3 4B Base and Qwen3 8B Base. It makes use of a sandboxed Python interpreter as the only exterior device.
The analysis crew consider on ten benchmarks:
- Mathematical reasoning: AMC, Minerva, MATH, GSM8K, Olympiad Bench, AIME24, AIME25.
- Normal reasoning: SuperGPQA, MMLU Professional, BBEH.
They report go@1 for many datasets and imply@32 for AMC and AIME duties.
For Qwen3 8B Base, Agent0 reaches:
- math common 58.2 versus 49.2 for the bottom mannequin,
- total normal common 42.1 versus 34.5 for the bottom mannequin.
Agent0 additionally improves over robust information free baselines reminiscent of R Zero, Absolute Zero, SPIRAL and Socratic Zero, each with and with out instruments. On Qwen3 8B, it surpasses R Zero by 6.4 proportion factors and Absolute Zero by 10.6 factors on the general common. It additionally beats Socratic Zero, which depends on exterior OpenAI APIs.
Throughout three co evolution iterations, common math efficiency on Qwen3 8B will increase from 55.1 to 58.2 and normal reasoning additionally improves per iteration. This confirms secure self enchancment relatively than collapse.
Qualitative examples present that curriculum duties evolve from fundamental geometry inquiries to complicated constraint satisfaction issues, whereas executor trajectories combine reasoning textual content with Python calls to succeed in right solutions.
Key Takeaways
- Absolutely information free co evolution: Agent0 eliminates exterior datasets and human annotations. Two brokers, a curriculum agent and an executor agent, are initialized from the identical base LLM and co evolve solely through reinforcement studying and a Python device.
- Frontier curriculum from self uncertainty: The curriculum agent makes use of the executor’s self consistency and gear utilization to attain duties. It learns to generate frontier duties which might be neither trivial nor inconceivable, and that explicitly require device built-in reasoning.
- ADPO stabilizes RL with pseudo labels: The executor is skilled with Ambiguity Dynamic Coverage Optimization. ADPO down weights extremely ambiguous duties and adapts the clipping vary based mostly on self consistency, which makes GRPO model updates secure when rewards come from majority vote pseudo labels.
- Constant positive factors on math and normal reasoning: On Qwen3 8B Base, Agent0 improves math benchmarks from 49.2 to 58.2 common and normal reasoning from 34.5 to 42.1, which corresponds to relative positive factors of about 18 % and 24 %.
- Outperforms prior zero information frameworks: Throughout ten benchmarks, Agent0 surpasses earlier self evolving strategies reminiscent of R Zero, Absolute Zero, SPIRAL and Socratic Zero, together with people who already use instruments or exterior APIs. This exhibits that the co evolution plus device integration design is a significant step past earlier single spherical self play approaches.
Editorial Notes
Agent0 is a vital step towards sensible, information free reinforcement studying for device built-in reasoning. It exhibits {that a} base LLM can act as each Curriculum Agent and Executor Agent, and that GRPO with ADPO and VeRL Instrument can drive secure enchancment from majority vote pseudo labels. The strategy additionally demonstrates that device built-in co evolution can outperform prior zero information frameworks reminiscent of R Zero and Absolute Zero on robust Qwen3 baselines. Agent0 makes a robust case that self evolving, device built-in LLM brokers have gotten a sensible coaching paradigm.
Try the PAPER and Repo. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be a part of us on telegram as effectively.

Michal Sutter is an information science skilled with a Grasp of Science in Information Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and information engineering, Michal excels at remodeling complicated datasets into actionable insights.










{kind=link}