How can a trillion-parameter Giant Language Mannequin obtain state-of-the-art enterprise efficiency whereas concurrently chopping its whole parameter rely by 33.3% and boosting pre-training effectivity by 49%? Yuan Lab AI releases Yuan3.0 Extremely, an open-source Combination-of-Specialists (MoE) giant language mannequin that includes 1T whole parameters and 68.8B activated parameters. The mannequin structure is designed to optimize efficiency in enterprise-specific duties whereas sustaining aggressive general-purpose capabilities. Not like conventional dense fashions, Yuan3.0 Extremely makes use of sparsity to scale capability with out a linear enhance in computational value.
Layer-Adaptive Professional Pruning (LAEP)
The first innovation in Yuan3.0 Extremely’s coaching is the Layer-Adaptive Professional Pruning (LAEP) algorithm. Whereas knowledgeable pruning is usually utilized post-training, LAEP identifies and removes underutilized specialists straight throughout the pre-training stage.
Analysis into knowledgeable load distribution revealed two distinct phases throughout pre-training:
- Preliminary Transition Section: Characterised by excessive volatility in knowledgeable hundreds inherited from random initialization.
- Steady Section: Professional hundreds converge, and the relative rating of specialists primarily based on token task stays largely fastened.
As soon as the steady part is reached, LAEP applies pruning primarily based on two constraints:
- Particular person Load Constraint (⍺): Targets specialists whose token load is considerably decrease than the layer common.
- Cumulative Load Constraint (β): Identifies the subset of specialists contributing the least to whole token processing.
By making use of LAEP with β=0.1 and ranging ⍺, the mannequin was pruned from an preliminary 1.5T parameters right down to 1T parameters. This 33.3% discount in whole parameters preserved the mannequin’s multi-domain efficiency whereas considerably reducing reminiscence necessities for deployment. Within the 1T configuration, the variety of specialists per layer was lowered from 64 to a most of 48 preserved specialists.
{Hardware} Effectivity and Professional Rearrangement
MoE fashions typically undergo from device-level load imbalance when specialists are distributed throughout a computing cluster. To handle this, Yuan3.0 Extremely implements an Professional Rearranging algorithm.
This algorithm ranks specialists by token load and makes use of a grasping technique to distribute them throughout GPUs in order that the cumulative token variance is minimized.
| Technique | TFLOPS per GPU |
| Base Mannequin (1515B) | 62.14 |
| DeepSeek-V3 Aux Loss | 80.82 |
| Yuan3.0 Extremely (LAEP) | 92.60 |
Complete pre-training effectivity improved by 49%. This enchancment is attributed to 2 elements:
- Mannequin Pruning: Contributed 32.4% to the effectivity achieve.
- Professional Rearrangement: Contributed 15.9% to the effectivity achieve.
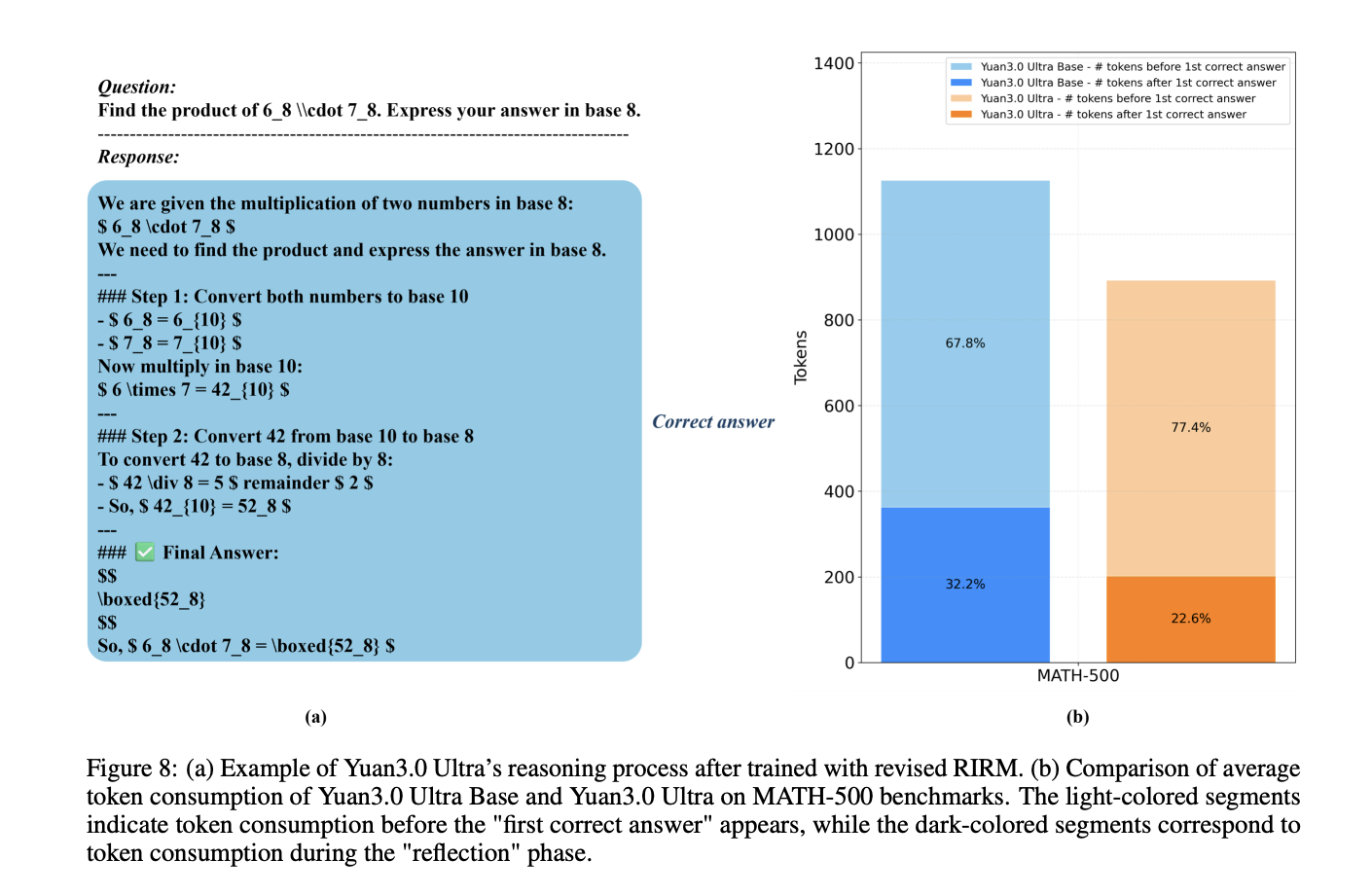
Mitigating Overthinking with Revised RIRM
Within the reinforcement studying (RL) stage, the mannequin employs a refined Reflection Inhibition Reward Mechanism (RIRM) to stop excessively lengthy reasoning chains for easy duties.
The reward for reflection, $R_{ver}$, is calculated utilizing a threshold-based penalty system:
- rmin=0: The best variety of reflection steps for direct responses.
- rmax=3: The utmost tolerable reflection threshold.
For proper samples, the reward decreases as reflection steps strategy rmax, whereas incorrect samples that ‘overthink’ (exceeding rmax obtain most penalties. This mechanism resulted in a 16.33% achieve in coaching accuracy and a 14.38% discount in output token size.

Enterprise Benchmark Efficiency
Yuan3.0 Extremely was evaluated towards a number of trade fashions, together with GPT-5.2 and Gemini 3.1 Professional, throughout specialised enterprise benchmarks.
| Benchmark | Process Class | Yuan3.0 Extremely Rating | Main Competitor Rating |
| Docmatix | Multimodal RAG | 67.4% | 48.4% (GPT-5.2) |
| ChatRAG | Textual content Retrieval (Avg) | 68.2% | 53.6% (Kimi K2.5) |
| MMTab | Desk Reasoning | 62.3% | 66.2% (Kimi K2.5) |
| SummEval | Textual content Summarization | 62.8% | 49.9% (Claude Opus 4.6) |
| Spider 1.0 | Textual content-to-SQL | 83.9% | 82.7% (Kimi K2.5) |
| BFCL V3 | Device Invocation | 67.8% | 78.8% (Gemini 3.1 Professional) |
The outcomes point out that Yuan3.0 Extremely achieves state-of-the-art accuracy in multimodal retrieval (Docmatix) and long-context retrieval (ChatRAG) whereas sustaining sturdy efficiency in structured information processing and gear calling.
Take a look at the Paper and Repo. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be part of us on telegram as nicely.










{kind=link}