Poolside AI launched the primary two fashions in its Laguna household: Laguna M.1 and Laguna XS.2. Alongside these, the corporate is releasing pool — a light-weight terminal-based coding agent and a twin Agent Shopper Protocol (ACP) client-server — the identical surroundings Poolside makes use of internally for agent RL coaching and analysis, now out there as a analysis preview.
What are These Fashions, and Why Ought to You Care?
Each Laguna M.1 and Laguna XS.2 are Combination-of-Consultants (MoE) fashions. As a substitute of activating all parameters for each token, MoE fashions route every token by means of solely a subset of specialised sub-networks known as ‘specialists.’ This implies a big complete parameter rely and the aptitude headroom that comes with it whereas solely paying the compute price of a a lot smaller “activated” parameter rely at inference time.
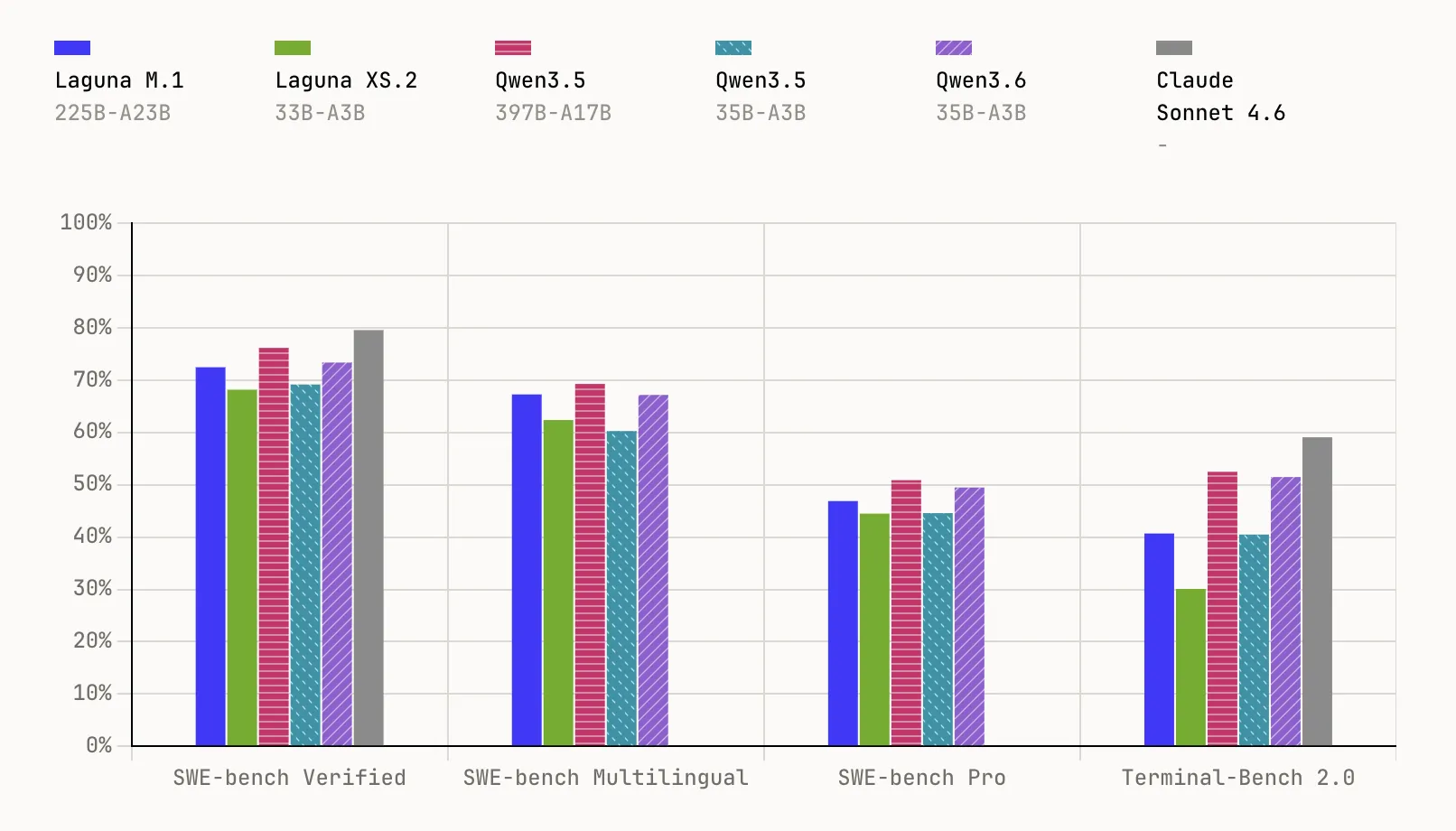
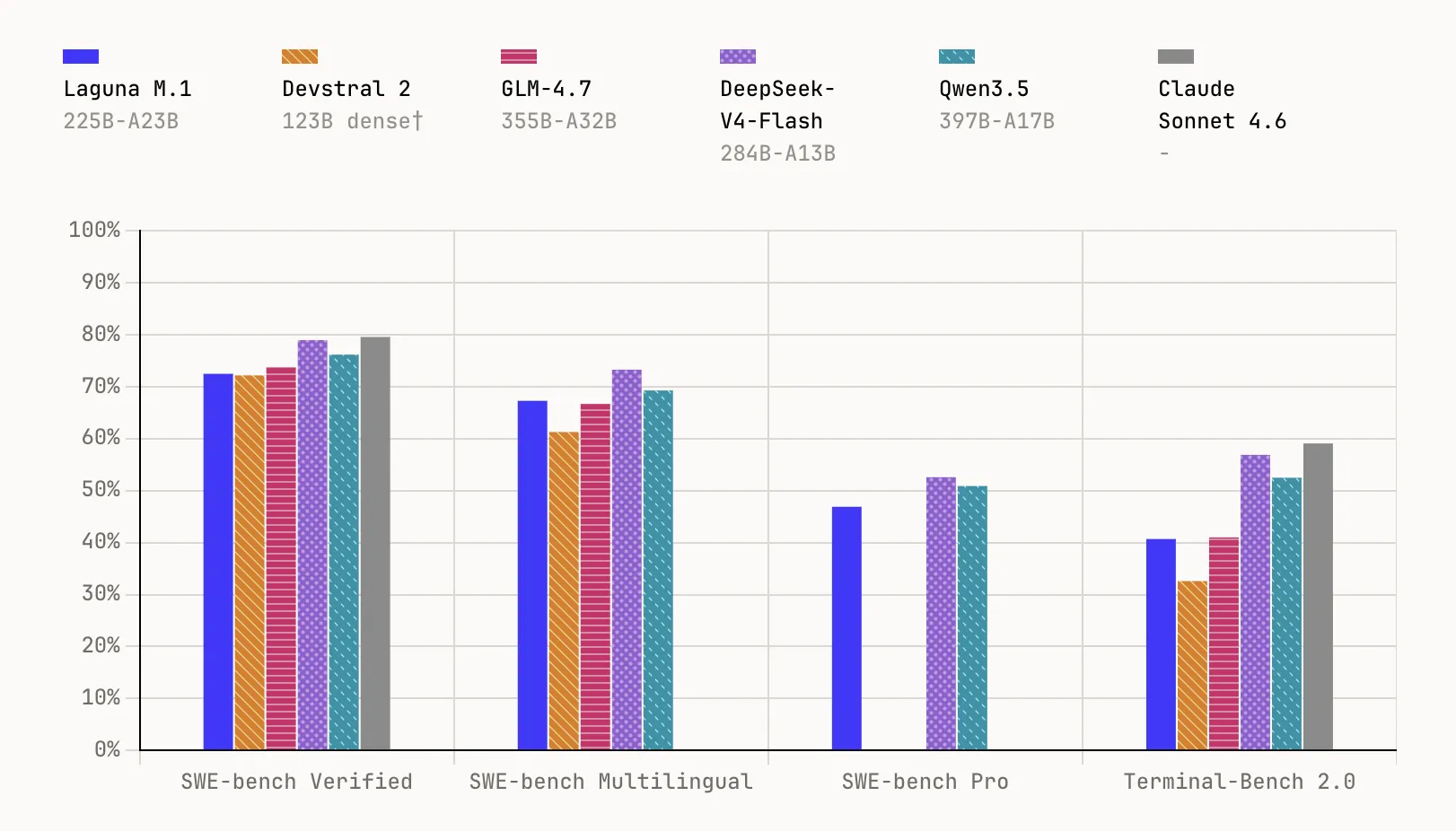
Laguna M.1 is a 225B complete parameter MoE mannequin with 23B activated parameters, skilled from scratch on 30T tokens utilizing 6,144 interconnected NVIDIA Hopper GPUs. It accomplished pre-training on the finish of final 12 months and serves as the muse for your complete Laguna household. On benchmarks, it reaches 72.5% on SWE-bench Verified, 67.3% on SWE-bench Multilingual, 46.9% on SWE-bench Professional, and 40.7% on Terminal-Bench 2.0.

Laguna XS.2 is the second-generation MoE and Poolside’s first open-weight mannequin, constructed on every little thing realized since coaching M.1. At 33B complete parameters with 3B activated per token, it’s designed for agentic coding and long-horizon work on a neighborhood machine — compact sufficient to run on a Mac with 36 GB of RAM through Ollama. It scores 68.2% on SWE-bench Verified, 62.4% on SWE-bench Multilingual, 44.5% on SWE-bench Professional, and 30.1% on Terminal-Bench 2.0. Poolside may even launch Laguna XS.2-base quickly for practitioners who wish to fine-tune.
Structure: The Effectivity Selections in XS.2
XS.2 makes use of sigmoid gating with per-layer rotary scales, enabling a blended Sliding Window Consideration (SWA) and international consideration format in a 3:1 ratio throughout 40 complete layers — 30 SWA layers and 10 international consideration layers. Sliding Window Consideration limits every token’s consideration to a neighborhood window of 512 tokens quite than the total sequence, dramatically slicing KV cache reminiscence. The worldwide consideration layers at a 1-in-4 ratio protect long-range dependencies with out paying the total price all over the place. The mannequin additionally quantizes the KV cache to FP8, additional lowering reminiscence per token.
Beneath the hood, XS.2 makes use of 256 specialists with 1 shared skilled, helps a context window of 131,072 tokens, and options native reasoning assist — interleaved considering between instrument calls with per-request management over enabling or disabling considering.
Coaching: Three Areas Poolside Pushed Arduous
Poolside workforce trains all its fashions from scratch utilizing its personal information pipeline, its personal coaching codebase (Titan), and its personal agent RL infrastructure. Three areas noticed specific funding for Laguna.
AutoMixer: Optimizing the Information Combine Robotically. Information curation and the combo that goes into coaching is extraordinarily impactful on closing mannequin efficiency. Somewhat than counting on guide heuristics, Poolside developed an automixing framework that trains a swarm of roughly 60 proxy fashions, every on a distinct information combine, and measures efficiency throughout key functionality teams — code, math, STEM, and customary sense. Surrogate regressors are then match to approximate how modifications in dataset proportions have an effect on downstream evaluations, giving a realized mapping from information combine to efficiency that may be immediately optimized. The method is impressed by prior work together with Olmix, MDE, and RegMix, tailored to Poolside’s setting with richer information groupings.
On the information aspect, each Laguna fashions have been skilled on greater than 30T tokens. Poolside’s diversity-preserving information curation method — which retains parts of mid- and lower-quality buckets alongside top-quality information to keep away from STEM bias — yields roughly 2× extra distinctive tokens in comparison with precision-focused pipelines, with the achieve persisting at longer coaching horizons. A separate deduplication evaluation additionally confirmed that international deduplication disproportionately removes high-quality information, informing how the workforce tuned its pipeline. Artificial information contributes about 13% of the ultimate coaching combine in Laguna XS.2, with the Laguna sequence utilizing roughly 4.4T+ artificial tokens in complete.
Muon Optimizer. Somewhat than AdamW — the commonest optimizer in giant mannequin coaching — Poolside used a distributed implementation of the Muon optimizer by means of all coaching levels of each fashions. In preliminary pre-training ablations, the analysis workforce achieved the identical coaching loss as an AdamW baseline in roughly 15% fewer steps, with giant absolute analysis uplifts on the ultimate mannequin, and achieved studying fee switch throughout mannequin scales. An extra profit: Muon requires just one state per parameter quite than two, lowering reminiscence necessities for each coaching and checkpointing. Throughout pre-training of Laguna M.1, the overhead from the optimizer was lower than 1% of the coaching step time.
Poolside additionally runs periodic hash checks on mannequin weights throughout coaching replicas to catch silent information corruption (SDC) from faulty GPUs — particularly errors in arithmetic logic and pipeline registers, which not like DRAM and SRAM aren’t lined by ECC safety.
Async On-Coverage Agent RL. That is arguably essentially the most advanced piece of the Laguna coaching stack. Poolside constructed a completely asynchronous on-line RL system the place actor processes pull duties from a dataset, spin up sandboxed containers, and run the manufacturing agent binary in opposition to every job utilizing the freshly deployed mannequin. The ensuing trajectories are scored, filtered, and written to Iceberg tables, whereas the coach repeatedly consumes these data and produces the subsequent checkpoint — inference and coaching operating asynchronously in parallel, with throughput tuned to stability off-policy staleness.
Key Takeaways
- Poolside releases its first open-weight mannequin: Laguna XS.2 is a 33B complete parameter MoE mannequin with solely 3B activated parameters per token, out there beneath an Apache 2.0 license — compact sufficient to run domestically on a Mac with 36 GB of RAM through Ollama.
- Robust benchmark efficiency at small scale: Laguna XS.2 scores 68.2% on SWE-bench Verified and 44.5% on SWE-bench Professional, whereas the bigger Laguna M.1 (225B complete, 23B activated) reaches 72.5% on SWE-bench Verified and 46.9% on SWE-bench Professional — each skilled from scratch on 30T tokens.
- Muon optimizer beats AdamW by 15% in coaching effectivity: Poolside changed AdamW with a distributed implementation of the Muon optimizer, attaining the identical coaching loss in roughly 15% fewer steps, with decrease reminiscence necessities — just one state per parameter as an alternative of two.
- AutoMixer replaces guide information mixing with realized optimization: As a substitute of handcrafted information recipes, Poolside trains a swarm of ~60 proxy fashions on totally different information mixes and suits surrogate regressors to optimize dataset proportions — with artificial information making up ~13% of Laguna XS.2’s closing coaching combine from a complete of 4.4T+ artificial tokens.
- Totally asynchronous agent RL with GPUDirect RDMA weight switch: Poolside’s RL system runs inference and coaching in parallel, transferring a whole bunch of gigabytes of BF16 weights between nodes in beneath 5 seconds through GPUDirect RDMA, utilizing a token-in, token-out actor design and the CISPO algorithm for off-policy coaching stability.
Try the Mannequin Weights and Technical particulars. Additionally, be happy to comply with us on Twitter and don’t overlook to affix our 130k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be part of us on telegram as effectively.
Must accomplice with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and many others.? Join with us










{kind=link}