LLMs have enabled us to course of giant quantities of textual content knowledge very effectively, and in a dependable and quick method. Probably the most widespread use circumstances that has emerged over the previous two years is Retrieval-Augmented Technology (RAG).
RAG permits us to take a variety of paperwork (from a pair to even 100 thousand), create a data database with the paperwork, after which question it and obtain solutions with related sources based mostly on the paperwork.
As a substitute of getting to manually search which might take hours and even days, we are able to get an LLM to seek for us with just some seconds of latency.
Cloud-based vs Native
There are two components to creating a RAG system work: the data database, and the LLM. Consider the previous as a library and the latter as a really environment friendly library clerk.
The primary design resolution when creating such a system is whether or not you’ll need to host it within the cloud, or domestically. Native deployments have a value benefit at scale and likewise assist safeguard your privateness. Alternatively, the cloud can provide low startup prices and little to no upkeep.
For the sake of clearly demonstrating the ideas round RAG, we’ll go for a cloud deployment throughout this information, however will even be leaving notes on going native on the finish.
The data (vector) database
So the very first thing we have to do is create a data database (techinically referred to as a vector database). The best way that is finished is by working the paperwork by means of an embedding mannequin that can create a vector out of every one. The embedding fashions are excellent at understanding textual content and the vectors generated could have related paperwork nearer collectively within the vector area.
That is extremely handy, and we are able to illustrate it by plotting the vectors of 4 paperwork of a hypothetical group in a 2D vector area:
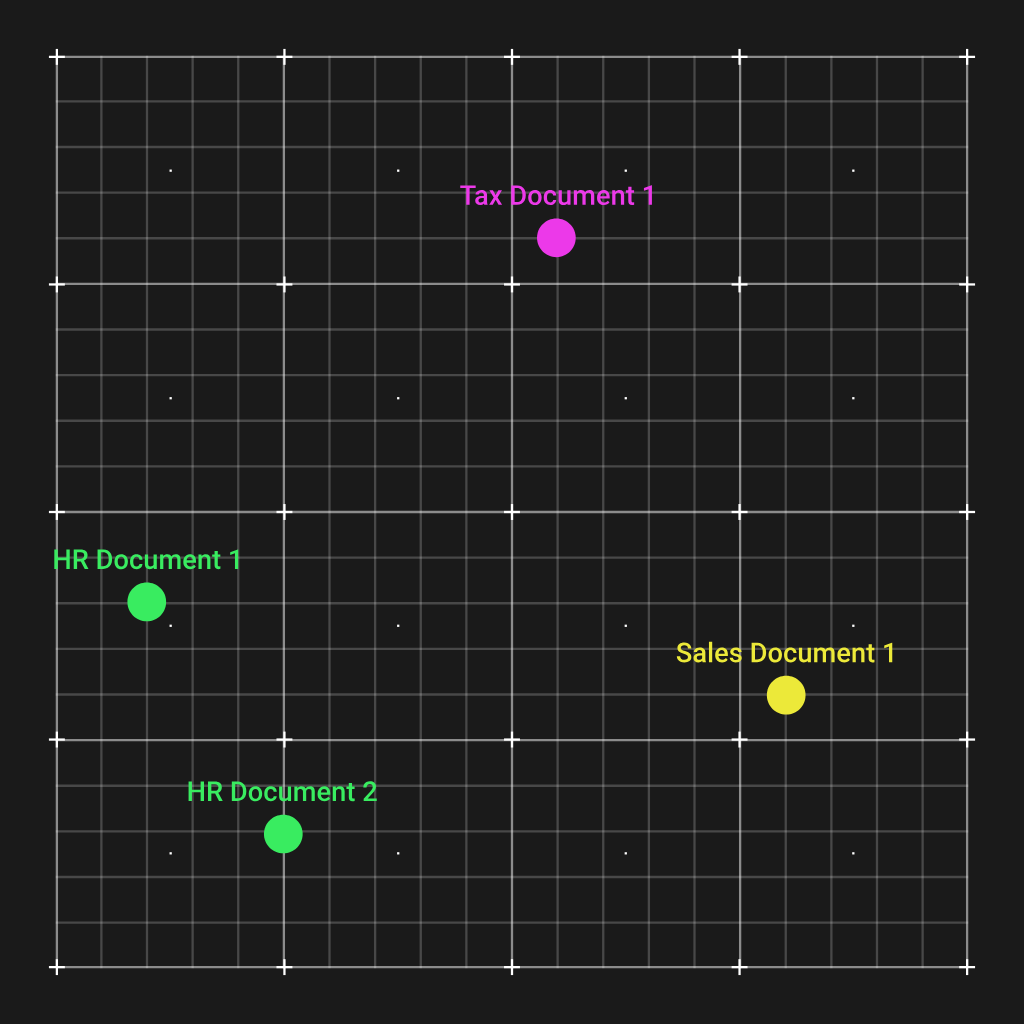
As you see, the 2 HR paperwork have been grouped collectively, and are removed from the opposite kinds of paperwork. Now, the way in which this helps us is that after we get a query concerning HR, we are able to calculate an embeddings vector for that query, which will even find yourself near the 2 HR paperwork.
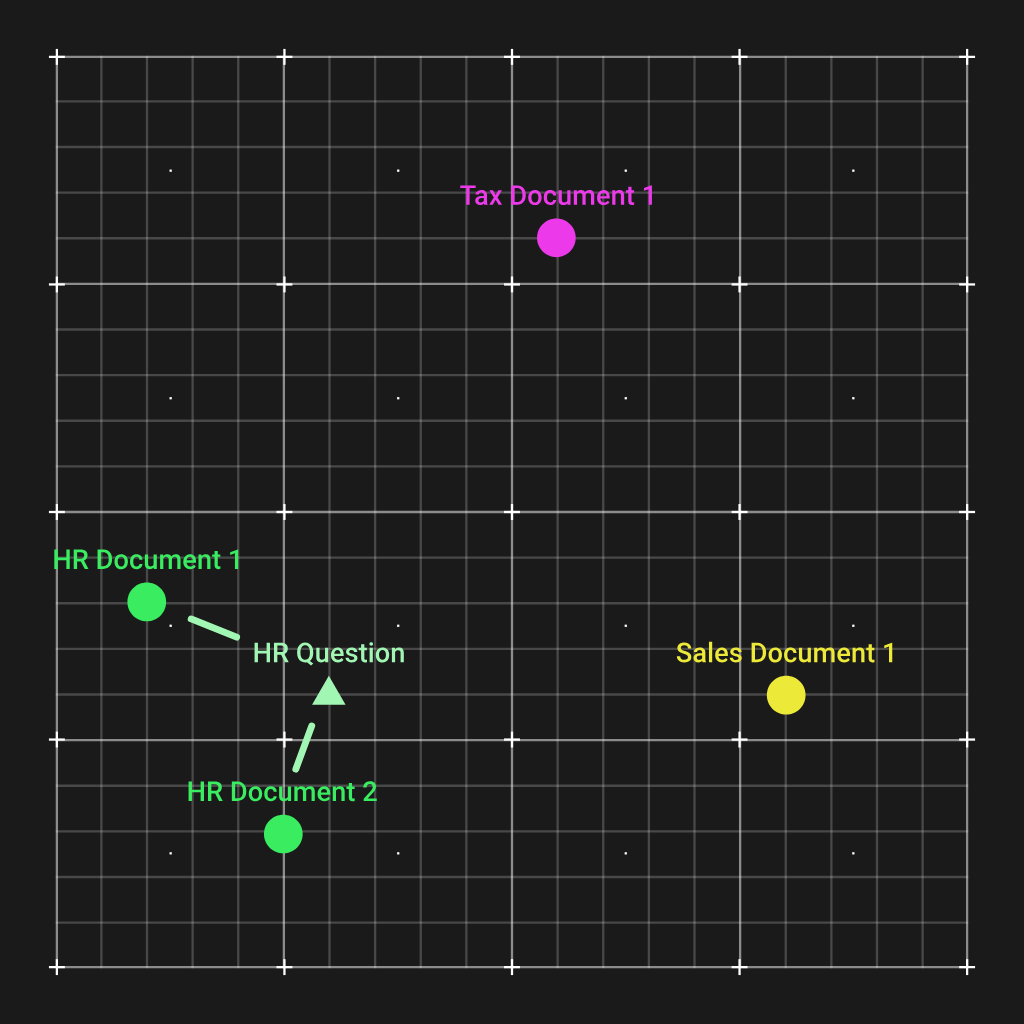
And by a easy Euclidian distance calculation, we are able to match probably the most related paperwork to provide to the LLM so it may possibly reply the query.
There are is an enormous array of embedding algorithms to select from that are all in contrast on the MTEB leaderboard. An fascinating truth right here is that quite a lot of open-source fashions are taking the lead in comparison with proprietary suppliers like OpenAI.
Apart from the general rating, two extra columns to have in mind on that leaderboard are the mannequin dimension, and the max tokens of every mannequin.
The mannequin dimension will decide how a lot V(RAM) will probably be wanted to load the mannequin in reminiscence in addition to how briskly embedding computations will probably be. Every mannequin can solely embed a certain quantity of tokens, so very giant recordsdata would possibly should be break up earlier than being embedded.
Lastly, the fashions can solely embed textual content, so any PDFs will should be transformed, and wealthy parts like photos needs to be both captioned (utilizing an AI picture caption mannequin) or discarded.
The open-source native embedding fashions might be ran domestically utilizing transformers. For the OpenAI embedding mannequin, you’ll want an OpenAI API key as an alternative.
Right here is Python code to create embeddings utilizing the OpenAI API and a easy pickle file-system-based vector database:
import os
from openai import OpenAI
import pickle
openai = OpenAI(
api_key="your_openai_api_key"
)
listing = "doc1"
embeddings_store = {}
def embed_text(textual content):
"""Embed textual content utilizing OpenAI embeddings."""
response = openai.embeddings.create(
enter=textual content,
mannequin="text-embedding-3-large"
)
return response.knowledge[0].embedding
def process_and_store_files(listing):
"""Course of .txt recordsdata, embed them, and retailer in-memory."""
for filename in os.listdir(listing):
if filename.endswith(".txt"):
file_path = os.path.be a part of(listing, filename)
with open(file_path, 'r', encoding='utf-8') as file:
content material = file.learn()
embedding = embed_text(content material)
embeddings_store[filename] = embedding
print(f"Saved embedding for {filename}")
def save_embeddings_to_file(file_path):
"""Save the embeddings dictionary to a file."""
with open(file_path, 'wb') as f:
pickle.dump(embeddings_store, f)
print(f"Embeddings saved to {file_path}")
def load_embeddings_from_file(file_path):
"""Load embeddings dictionary from a file."""
with open(file_path, 'rb') as f:
embeddings_store = pickle.load(f)
print(f"Embeddings loaded from {file_path}")
return embeddings_store
process_and_store_files(listing)
save_embeddings_to_file("embeddings_store.pkl")
LLM
Now that we now have the paperwork saved within the database, let’s create a operate to get the highest 3 most related paperwork based mostly on a question:
import numpy as np
def get_top_k_relevant(question, embeddings_store, top_k=3):
"""
Given a question string and a dictionary of doc embeddings,
return the top_k paperwork most related (lowest Euclidean distance).
"""
query_embedding = embed_text(question)
distances = []
for doc_id, doc_embedding in embeddings_store.objects():
dist = np.linalg.norm(np.array(query_embedding) - np.array(doc_embedding))
distances.append((doc_id, dist))
distances.kind(key=lambda x: x[1])
return distances[:top_k]
And now that we now have the paperwork comes the easy half, which is prompting our LLM, GPT-4o on this case, to provide a solution based mostly on them:
from openai import OpenAI
openai = OpenAI(
api_key="your_openai_api_key"
)
def answer_query_with_context(question, doc_store, embeddings_store, top_k=3):
"""
Given a question, discover the top_k most related paperwork and immediate GPT-4o
to reply the question utilizing these paperwork as context.
"""
best_matches = get_top_k_relevant(question, embeddings_store, top_k)
context = ""
for doc_id, distance in best_matches:
doc_content = doc_store.get(doc_id, "")
context += f"--- Doc: {doc_id} (Distance: {distance:.4f}) ---n{doc_content}nn"
completion = openai.chat.completions.create(
mannequin="gpt-4o",
messages=[
{
"role": "system",
"content": (
"You are a helpful assistant. Use the provided context to answer the user’s query. "
"If the answer isn't in the provided context, say you don't have enough information."
)
},
{
"role": "user",
"content": (
f"Context:n{context}n"
f"Question:n{query}nn"
"Please provide a concise, accurate answer based on the above documents."
)
}
],
temperature=0.7
)
reply = completion.decisions[0].message.content material
return reply
Conclusion
There you might have it! That is an intuitive implementation of RAG with quite a lot of room for enchancment. Listed here are some concepts on the place to go subsequent:










{kind=link}