DeepSeek researchers are attempting to unravel a exact situation in giant language mannequin coaching. Residual connections made very deep networks trainable, hyper connections widened that residual stream, and coaching then grew to become unstable at scale. The brand new methodology mHC, Manifold Constrained Hyper Connections, retains the richer topology of hyper connections however locks the blending habits on a properly outlined manifold in order that alerts stay numerically steady in very deep stacks.
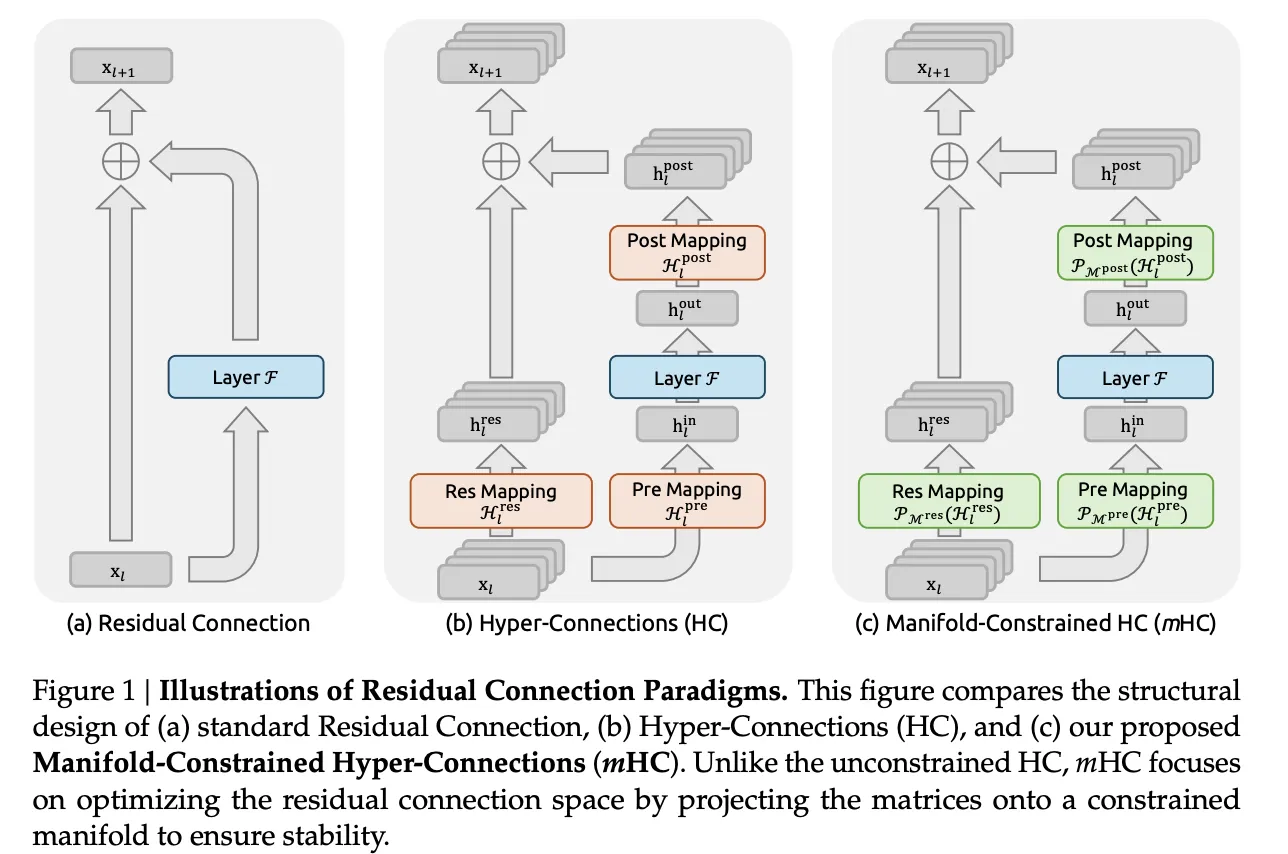
From Residual Connections To Hyper Connections
Commonplace residual connections, as in ResNets and Transformers, propagate activations with xl+1=xl+F(xl,Wl)
The identification path preserves magnitude and retains gradients usable even while you stack many layers.
Hyper Connections generalize this construction. As a substitute of a single residual vector of dimension C, the mannequin retains an n stream buffer 𝑥𝑙∈𝑅𝑛×𝐶. Three discovered mappings management how every layer reads and writes this buffer:
- Hlpre selects a combination of streams because the layer enter
- F is the same old consideration or feed ahead sublayer
- Hlsubmit writes outcomes again into the n stream buffer
- Hlres∈Rn×n mixes streams between layers
The replace has the shape
xl+1=Hlresxl+Hlsubmit⊤F(Hlprexl,Wl)
With n set to 4, this design will increase expressivity with out a big enhance in floating level price, which is why hyper connections enhance downstream efficiency in language fashions.
Why Hyper Connections Turn into Unstable
The issue seems while you have a look at the product of residual mixers throughout many layers. In a 27B combination of specialists mannequin, DeepSeek research the composite mapping
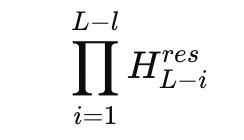
and defines an Amax Achieve Magnitude primarily based on most row and column sums. This metric measures worst case amplification within the ahead and backward sign paths. Within the hyper connection mannequin, this acquire reaches peaks round 3000, removed from the best worth 1 that you simply count on from a steady residual path.
This implies small per layer deviations compound into very giant amplification components throughout depth. Coaching logs present loss spikes and unstable gradient norms relative to a baseline residual mannequin. On the identical time, holding a multi stream buffer will increase reminiscence site visitors for every token, which makes naive scaling of hyper connections unattractive for manufacturing giant language fashions.
Manifold Constrained Hyper Connections
mHC retains the multi stream residual thought however constrains the harmful half. The residual mixing matrix Hlres not lives within the full n by n house. As a substitute, it’s projected onto the manifold of doubly stochastic matrices, additionally known as the Birkhoff polytope. In that set all entries are non unfavourable and every row and every column sums to 1.
DeepSeek group enforces this constraint with the classical Sinkhorn Knopp algorithm from 1967, which alternates row and column normalizations to approximate a doubly stochastic matrix. The analysis group makes use of 20 iterations per layer throughout coaching, which is sufficient to hold the mapping near the goal manifold whereas holding price manageable.
Below these constraints, Hlresxl behaves like a convex mixture of residual streams. Whole characteristic mass is preserved and the norm is tightly regularized, which eliminates the explosive development seen in plain hyper connections. The analysis group additionally parameterize enter and output mappings in order that coefficients are non unfavourable, which avoids cancellation between streams and retains the interpretation as averaging clear.
With mHC the composite Amax Achieve Magnitude stays bounded and peaks at about 1.6 within the 27B mannequin, in contrast with peaks close to 3000 for the unconstrained variant. That could be a discount of about 3 orders of magnitude in worst case amplification, and it comes from a direct mathematical constraint fairly than tuned methods.
Techniques Work And Coaching Overhead
Constraining each residual mixer with Sinkhorn type iterations provides price on paper. The analysis group addresses this with a number of methods decisions:
- Fused kernels mix RMSNorm, projections and gating for the mHC mappings in order that reminiscence site visitors stays low
- Recompute primarily based activation checkpointing trades compute for reminiscence by recomputing mHC activations throughout backprop for blocks of layers
- Integration with a DualPipe like pipeline schedule overlaps communication and recomputation, in order that extra work doesn’t stall the coaching pipeline
In giant scale in home coaching runs, mHC with enlargement price n equal to 4 provides about 6.7 p.c coaching time overhead relative to the baseline structure. That determine already consists of each the additional compute from Sinkhorn Knopp and the infrastructure optimizations.
Empirical Outcomes
The analysis group trains 3B, 9B and 27B combination of specialists fashions and evaluates them on an ordinary language mannequin benchmark suite, together with duties like BBH, DROP, GSM8K, HellaSwag, MMLU, PIQA and TriviaQA.
For the 27B mannequin, the reported numbers on a subset of duties present the sample clearly:
- Baseline: BBH 43.8, DROP F1 47.0
- With hyper connections: BBH 48.9, DROP 51.6
- With mHC: BBH 51.0, DROP 53.9
So hyper connections already present a acquire over the essential residual design, and manifold constrained hyper connections push efficiency additional whereas restoring stability. Related traits seem on different benchmarks and throughout mannequin sizes, and scaling curves counsel that the benefit persists throughout compute budgets and thru the complete coaching trajectory fairly than solely at convergence.
Key Takeaways
- mHC stabilizes widened residual streams: mHC, Manifold Constrained Hyper Connections, widens the residual pathway into 4 interacting streams like HC, however constrains the residual mixing matrices on a manifold of doubly stochastic matrices, so lengthy vary propagation stays norm managed as an alternative of exploding.
- Exploding acquire is diminished from ≈3000 to ≈1.6: For a 27B MoE mannequin, the Amax Achieve Magnitude of the composite residual mapping peaks close to 3000 for unconstrained HC, whereas mHC retains this metric bounded round 1.6, which removes the exploding residual stream habits that beforehand broke coaching.
- Sinkhorn Knopp enforces doubly stochastic residual mixing: Every residual mixing matrix is projected with about 20 Sinkhorn Knopp iterations in order that rows and columns each sum to 1, making the mapping a convex mixture of permutations, which restores an identification like habits whereas nonetheless permitting wealthy cross stream communication.
- Small coaching overhead, measurable downstream good points: Throughout 3B, 9B and 27B DeepSeek MoE fashions, mHC improves benchmark accuracy, for instance about plus 2.1 p.c on BBH for the 27B mannequin, whereas including solely about 6.7 p.c coaching time overhead by fused kernels, recompute and pipeline conscious scheduling.
- Introduces a brand new scaling axis for LLM design: As a substitute of solely scaling parameters or context size, mHC reveals that explicitly designing the topology and manifold constraints of the residual stream, for instance residual width and construction, is a sensible technique to unlock higher efficiency and stability in future giant language fashions.
Try the FULL PAPER right here. Additionally, be at liberty to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be part of us on telegram as properly.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.











{kind=link}