EmbeddingGemma is Google’s new open textual content embedding mannequin optimized for on-device AI, designed to stability effectivity with state-of-the-art retrieval efficiency.
How compact is EmbeddingGemma in comparison with different fashions?
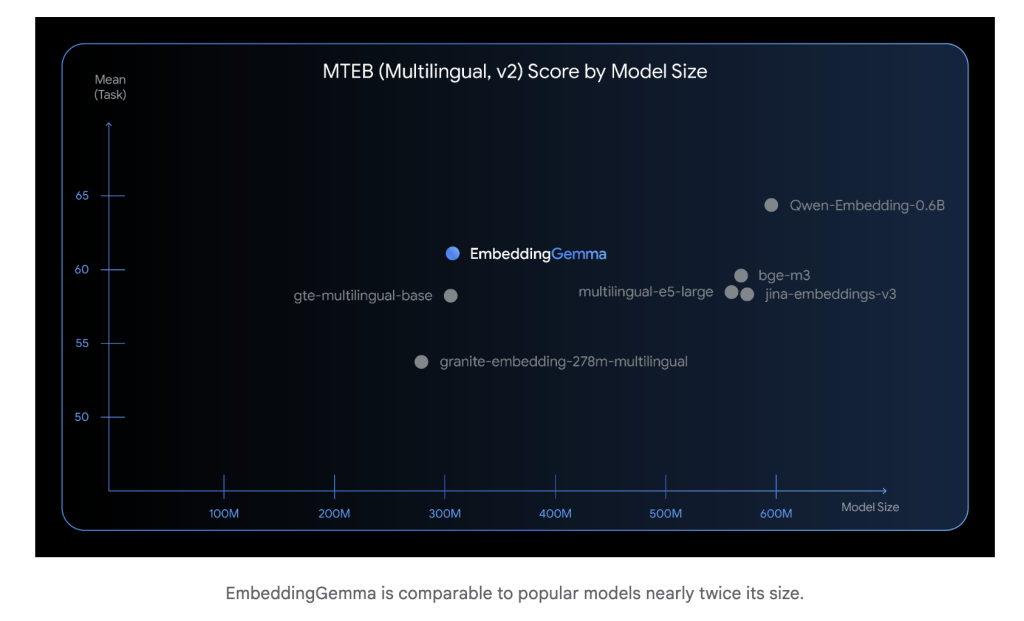
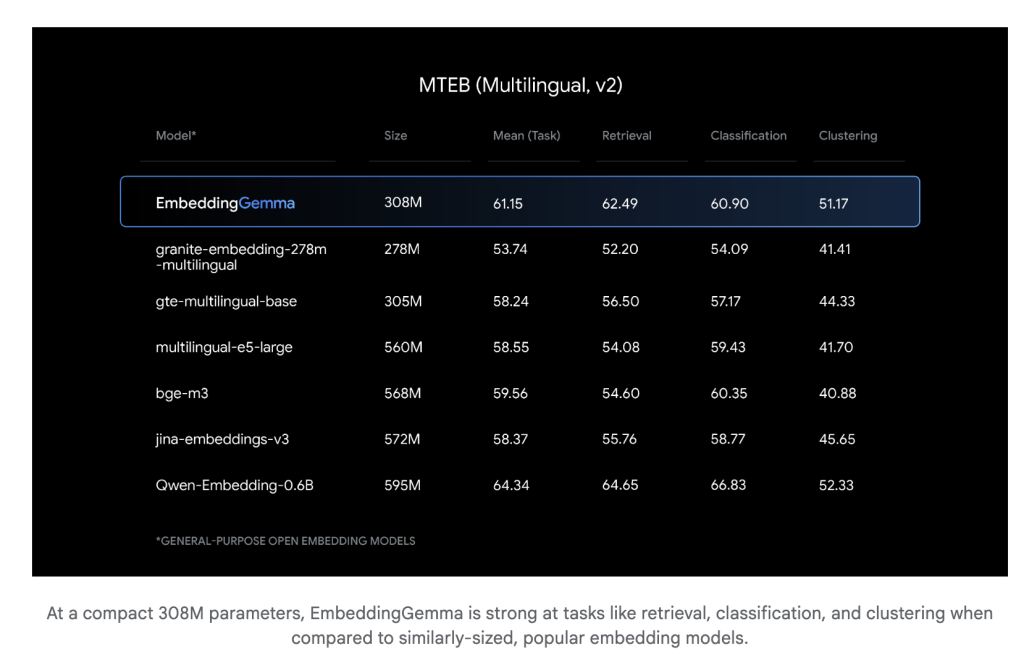
At simply 308 million parameters, EmbeddingGemma is light-weight sufficient to run on cellular units and offline environments. Regardless of its measurement, it performs competitively with a lot bigger embedding fashions. Inference latency is low (sub-15 ms for 256 tokens on EdgeTPU), making it appropriate for real-time purposes.
How effectively does it carry out on multilingual benchmarks?
EmbeddingGemma was skilled throughout 100+ languages and achieved the highest rating on the Huge Textual content Embedding Benchmark (MTEB) amongst fashions beneath 500M parameters. Its efficiency rivals or exceeds embedding fashions almost twice its measurement, notably in cross-lingual retrieval and semantic search.
What’s the underlying structure?
EmbeddingGemma is constructed on a Gemma 3–primarily based encoder spine with imply pooling. Importantly, the structure doesn’t use the multimodal-specific bidirectional consideration layers that Gemma 3 applies for picture inputs. As an alternative, EmbeddingGemma employs a normal transformer encoder stack with full-sequence self-attention, which is typical for textual content embedding fashions.
This encoder produces 768-dimensional embeddings and helps sequences as much as 2,048 tokens, making it well-suited for retrieval-augmented technology (RAG) and long-document search. The imply pooling step ensures fixed-length vector representations no matter enter measurement.
What makes its embeddings versatile?
EmbeddingGemma employs Matryoshka Illustration Studying (MRL). This enables embeddings to be truncated from 768 dimensions right down to 512, 256, and even 128 dimensions with minimal lack of high quality. Builders can tune the trade-off between storage effectivity and retrieval precision with out retraining.
Can it run fully offline?
Sure. EmbeddingGemma was particularly designed for on-device, offline-first use circumstances. Because it shares a tokenizer with Gemma 3n, the identical embeddings can immediately energy compact retrieval pipelines for native RAG methods, with privateness advantages from avoiding cloud inference.
What instruments and frameworks help EmbeddingGemma?
It integrates seamlessly with:
- Hugging Face (transformers, Sentence-Transformers, transformers.js)
- LangChain and LlamaIndex for RAG pipelines
- Weaviate and different vector databases
- ONNX Runtime for optimized deployment throughout platforms
This ecosystem ensures builders can slot it immediately into present workflows.
How can or not it’s carried out in apply?
(1) Load and Embed
from sentence_transformers import SentenceTransformer
mannequin = SentenceTransformer("google/embeddinggemma-300m")
emb = mannequin.encode(["example text to embed"])
(2) Alter Embedding Measurement
Use full 768 dims for max accuracy or truncate to 512/256/128 dims for decrease reminiscence or sooner retrieval.
(3) Combine into RAG
Run similarity search regionally (cosine similarity) and feed prime outcomes into Gemma 3n for technology. This permits a completely offline RAG pipeline.

Why EmbeddingGemma?
- Effectivity at scale – Excessive multilingual retrieval accuracy in a compact footprint.
- Flexibility – Adjustable embedding dimensions through MRL.
- Privateness – Finish-to-end offline pipelines with out exterior dependencies.
- Accessibility – Open weights, permissive licensing, and powerful ecosystem help.
EmbeddingGemma proves that smaller embedding fashions can obtain best-in-class retrieval efficiency whereas being mild sufficient for offline deployment. It marks an necessary step towards environment friendly, privacy-conscious, and scalable on-device AI.
Try the Mannequin and Technical particulars. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Publication.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.











{kind=link}