Google has launched T5Gemma 2, a household of open encoder-decoder Transformer checkpoints constructed by adapting Gemma 3 pretrained weights into an encoder-decoder structure, then persevering with pretraining with the UL2 goal. The discharge is pretrained solely, meant for builders to post-train for particular duties, and Google explicitly notes it’s not releasing post-trained or IT checkpoints for this drop.
T5Gemma 2 is positioned as an encoder-decoder counterpart to Gemma 3 that retains the identical low degree constructing blocks, then provides 2 structural adjustments aimed toward small mannequin effectivity. The fashions inherit Gemma 3 options that matter for deployment, notably multimodality, lengthy context as much as 128K tokens, and broad multilingual protection, with the weblog stating over 140 languages.
What Google really launched?
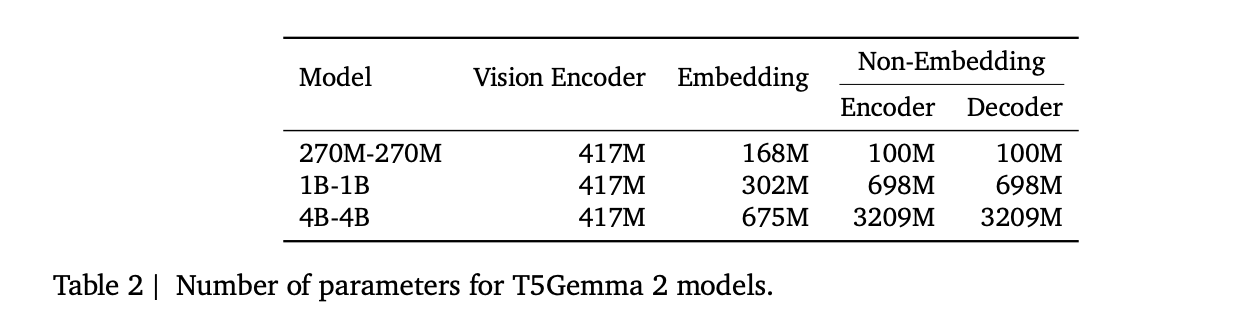
The discharge consists of 3 pretrained sizes, 270M-270M, 1B-1B, and 4B-4B, the place the notation means the encoder and decoder are the identical measurement. The analysis staff stories approximate totals excluding the imaginative and prescient encoder, about 370M, 1.7B, and 7B parameters. The multimodal accounting lists a 417M parameter imaginative and prescient encoder, together with encoder and decoder parameters damaged into embedding and non embedding elements.
The difference, encoder-decoder with out coaching from scratch
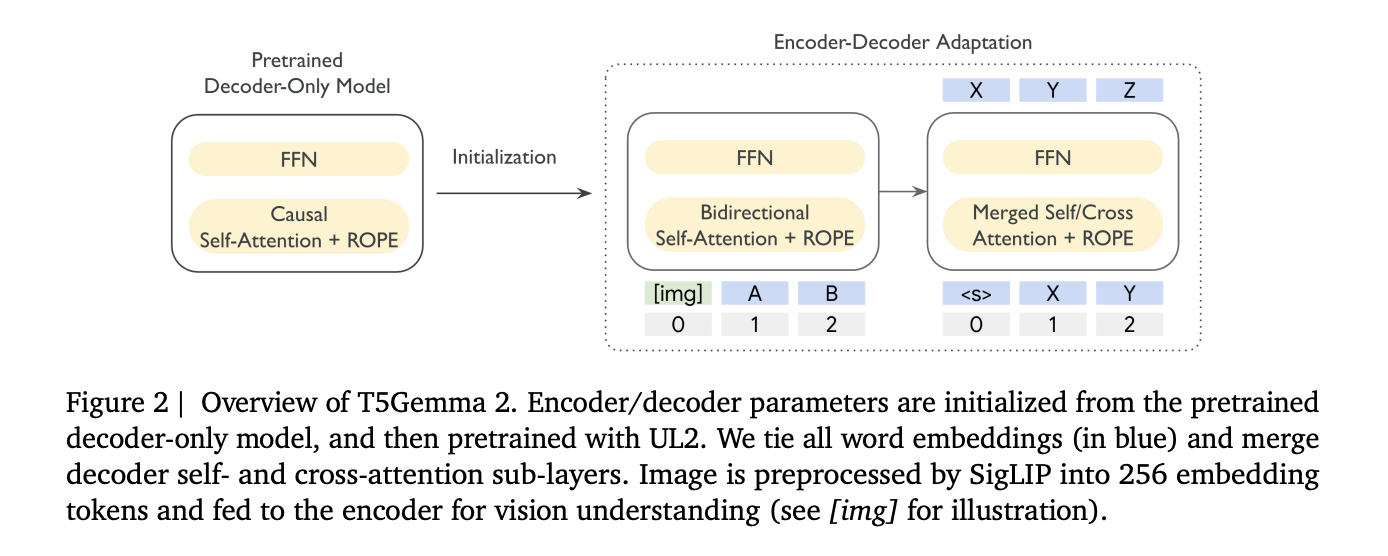
T5Gemma 2 follows the identical adaptation concept launched in T5Gemma, initialize an encoder-decoder mannequin from a decoder-only checkpoint, then adapt with UL2. Within the above determine the analysis staff present encoder and decoder parameters initialized from the pretrained decoder-only mannequin, then pretrained with UL2, with photos first transformed by SigLIP into 256 tokens.
This issues as a result of encoder-decoder splits the workload, the encoder can learn the total enter bidirectionally, whereas the decoder focuses on autoregressive technology. The analysis staff argues this separation may also help lengthy context duties the place the mannequin should retrieve related proof from a big enter earlier than producing.
Two effectivity adjustments which can be simple to overlook however have an effect on small fashions
First, T5Gemma 2 makes use of tied phrase embeddings throughout encoder enter embedding, decoder enter embedding, and decoder output or softmax embedding. This reduces parameter redundancy, and references an ablation exhibiting little high quality change whereas lowering embedding parameters.
Second, it introduces merged consideration within the decoder. As an alternative of separate self-attention and cross-attention sublayers, the decoder performs a single consideration operation the place Ok and V are fashioned by concatenating encoder outputs and decoder states, and masking preserves causal visibility for decoder tokens. This ties to simpler initialization, as a result of it narrows variations between the tailored decoder and the unique Gemma type decoder stack, and it stories parameter financial savings with a small common high quality drop of their ablations.

Multimodality, picture understanding is encoder facet, not decoder facet
T5Gemma 2 is multimodal by reusing Gemma 3’s imaginative and prescient encoder and maintaining it frozen throughout coaching. Imaginative and prescient tokens are all the time fed to the encoder and encoder tokens have full visibility to one another in self consideration. This can be a pragmatic encoder-decoder design, the encoder fuses picture tokens with textual content tokens into contextual representations, and the decoder can then attend to these representations whereas producing textual content.
On the tooling facet, T5Gemma 2 is positioned below an image-text-to-text pipeline, which matches the analysis’s design, picture in, textual content immediate in, textual content out. That pipeline instance is the quickest option to validate the tip to finish multimodal path, together with dtype decisions like bfloat16 and automated gadget mapping.
Lengthy context to 128K, what allows it
Google researchers attributes the 128K context window to Gemma 3’s alternating native and international consideration mechanism. The Gemma 3 staff describes a repeating 5 to 1 sample, 5 native sliding window consideration layers adopted by 1 international consideration layer, with a neighborhood window measurement of 1024. This design reduces KV cache development relative to creating each layer international, which is one purpose lengthy context turns into possible at smaller footprints.
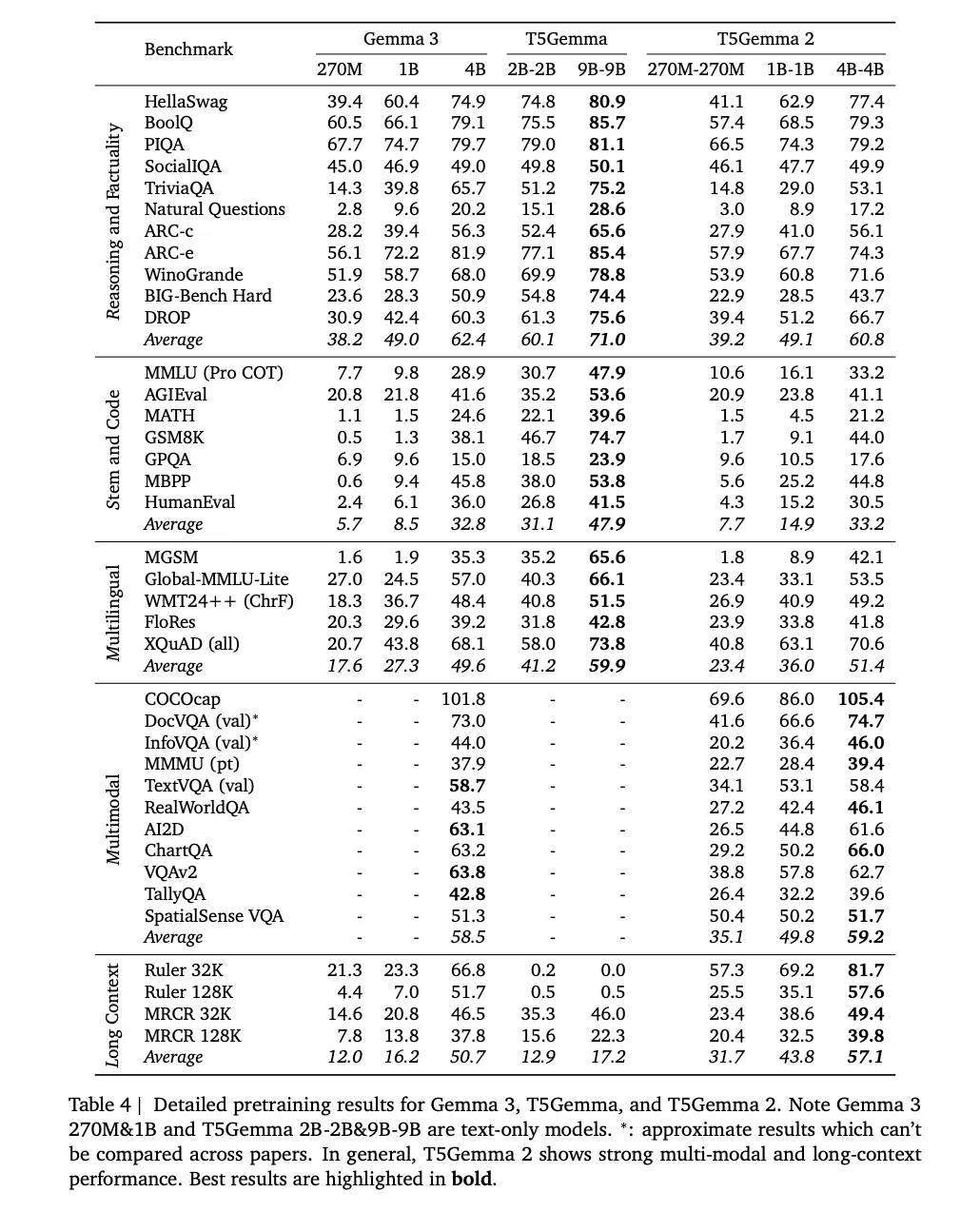
Within the T5Gemma 2, the analysis staff additionally point out adopting positional interpolation strategies for lengthy context, they usually pretrain on sequences as much as 16K enter paired with 16K goal outputs, then consider lengthy context efficiency as much as 128K on benchmarks together with RULER and MRCR. The detailed pretraining outcomes desk consists of 32K and 128K evaluations, exhibiting the lengthy context deltas they declare over Gemma 3 on the identical scale.
Coaching setup and what “pretrained solely” implies for customers
The analysis staff states the fashions are pretrained on 2T tokens and describes a coaching setup that features a batch measurement of 4.2M tokens, cosine studying charge decay with 100 warmup steps, international gradient clipping at 1.0, and checkpoint averaging over the past 5 checkpoints.
Key Takeaways
- T5Gemma 2 is an encoder decoder household tailored from Gemma 3 and continued with UL2, it reuses Gemma 3 pretrained weights, then applies the identical UL2 primarily based adaptation recipe utilized in T5Gemma.
- Google launched pretrained checkpoints solely, no put up educated or instruction tuned variants are included on this drop, so downstream use requires your individual put up coaching and analysis.
- Multimodal enter is dealt with by a SigLIP imaginative and prescient encoder that outputs 256 picture tokens and stays frozen, these imaginative and prescient tokens go into the encoder, the decoder generates textual content.
- Two parameter effectivity adjustments are central, tied phrase embeddings share encoder, decoder, and output embeddings, merged consideration unifies decoder self consideration and cross consideration right into a single module.
- Lengthy context as much as 128K is enabled by Gemma 3’s interleaved consideration design, a repeating 5 native sliding window layers with window measurement 1024 adopted by 1 international layer, and T5Gemma 2 inherits this mechanism.
Try the Paper, Technical particulars and Mannequin on Hugging Face. Additionally, be happy to observe us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be part of us on telegram as nicely.

I’m a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I’ve a eager curiosity in Information Science, particularly Neural Networks and their software in varied areas.











{kind=link}