Smart Agent is an AI analysis framework and prototype from Google that chooses each the motion an augmented actuality (AR) agent ought to take and the interplay modality to ship/affirm it, conditioned on real-time multimodal context (e.g., whether or not palms are busy, ambient noise, social setting). Relatively than treating “what to recommend” and “the best way to ask” as separate issues, it computes them collectively to reduce friction and social awkwardness within the wild.
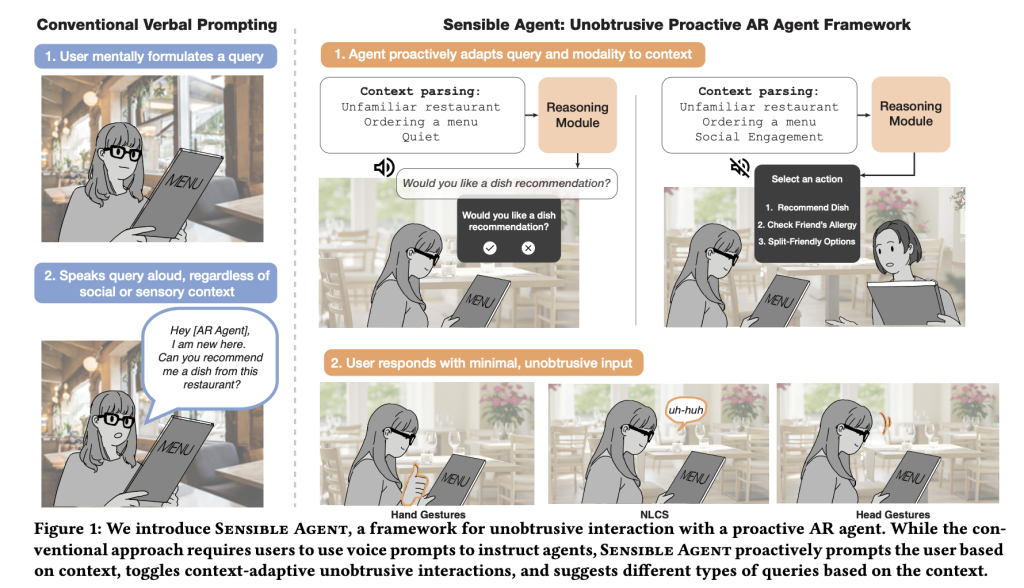
What interplay failure modes is it focusing on?
Voice-first prompting is brittle: it’s sluggish below time strain, unusable with busy palms/eyes, and awkward in public. Smart Agent’s core guess is {that a} high-quality suggestion delivered via the flawed channel is successfully noise. The framework explicitly fashions the joint choice of (a) what the agent proposes (advocate/information/remind/automate) and (b) how it’s offered and confirmed (visible, audio, or each; inputs by way of head nod/shake/tilt, gaze dwell, finger poses, short-vocabulary speech, or non-lexical conversational sounds). By binding content material choice to modality feasibility and social acceptability, the system goals to decrease perceived effort whereas preserving utility.
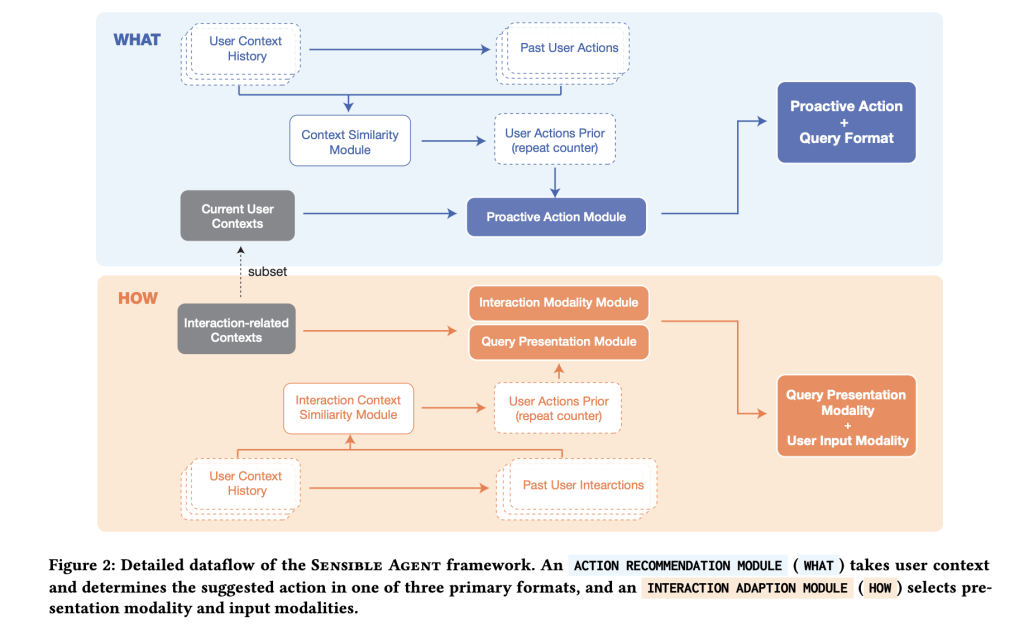
How is the system architected at runtime?
A prototype on an Android-class XR headset implements a pipeline with three principal phases. First, context parsing fuses selfish imagery (vision-language inference for scene/exercise/familiarity) with an ambient audio classifier (YAMNet) to detect situations like noise or dialog. Second, a proactive question generator prompts a big multimodal mannequin with few-shot exemplars to pick out the motion, question construction (binary / multi-choice / icon-cue), and presentation modality. Third, the interplay layer allows solely these enter strategies appropriate with the sensed I/O availability, e.g., head nod for “sure” when whispering isn’t acceptable, or gaze dwell when palms are occupied.
The place do the few-shot insurance policies come from—designer intuition or knowledge?
The workforce seeded the coverage area with two research: an skilled workshop (n=12) to enumerate when proactive assist is beneficial and which micro-inputs are socially acceptable; and a context mapping examine (n=40; 960 entries) throughout on a regular basis eventualities (e.g., fitness center, grocery, museum, commuting, cooking) the place individuals specified desired agent actions and selected a most popular question sort and modality given the context. These mappings floor the few-shot exemplars used at runtime, shifting the selection of “what+how” from ad-hoc heuristics to data-derived patterns (e.g., multi-choice in unfamiliar environments, binary below time strain, icon + visible in socially delicate settings).
What concrete interplay methods does the prototype help?
For binary confirmations, the system acknowledges head nod/shake; for multi-choice, a head-tilt scheme maps left/proper/again to choices 1/2/3. Finger-pose gestures help numeric choice and thumbs up/down; gaze dwell triggers visible buttons the place raycast pointing can be fussy; short-vocabulary speech (e.g., “sure,” “no,” “one,” “two,” “three”) supplies a minimal dictation path; and non-lexical conversational sounds (“mm-hm”) cowl noisy or whisper-only contexts. Crucially, the pipeline solely presents modalities which might be possible below present constraints (e.g., suppress audio prompts in quiet areas; keep away from gaze dwell if the consumer isn’t trying on the HUD).
Does the joint choice truly scale back interplay price?
A preliminary within-subjects consumer examine (n=10) evaluating the framework to a voice-prompt baseline throughout AR and 360° VR reported decrease perceived interplay effort and decrease intrusiveness whereas sustaining usability and choice. It is a small pattern typical of early HCI validation; it’s directional proof moderately than product-grade proof, nevertheless it aligns with the thesis that coupling intent and modality reduces overhead.
How does the audio facet work, and why YAMNet?
YAMNet is a light-weight, MobileNet-v1–primarily based audio occasion classifier educated on Google’s AudioSet, predicting 521 lessons. On this context it’s a sensible option to detect tough ambient situations—speech presence, music, crowd noise—quick sufficient to gate audio prompts or to bias towards visible/gesture interplay when speech can be awkward or unreliable. The mannequin’s ubiquity in TensorFlow Hub and Edge guides makes it easy to deploy on gadget.
How will you combine it into an current AR or cell assistant stack?
A minimal adoption plan seems like this: (1) instrument a light-weight context parser (VLM on selfish frames + ambient audio tags) to supply a compact state; (2) construct a few-shot desk of context→(motion, question sort, modality) mappings from inner pilots or consumer research; (3) immediate an LMM to emit each the “what” and the “how” without delay; (4) expose solely possible enter strategies per state and preserve confirmations binary by default; (5) log selections and outcomes for offline coverage studying. The Smart Agent artifacts present that is possible in WebXR/Chrome on Android-class {hardware}, so migrating to a local HMD runtime or perhaps a phone-based HUD is generally an engineering train.
Abstract
Smart Agent operationalizes proactive AR as a coupled coverage downside—choosing the motion and the interplay modality in a single, context-conditioned choice—and validates the strategy with a working WebXR prototype and small-N consumer examine displaying decrease perceived interplay effort relative to a voice baseline. The framework’s contribution will not be a product however a reproducible recipe: a dataset of context→(what/how) mappings, few-shot prompts to bind them at runtime, and low-effort enter primitives that respect social and I/O constraints.
Take a look at the Paper and Technical particulars. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter.

Michal Sutter is an information science skilled with a Grasp of Science in Information Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking complicated datasets into actionable insights.











{kind=link}