There’s rather a lot to find out about search intent, from utilizing deep studying to deduce search intent by classifying textual content and breaking down SERP titles utilizing Pure Language Processing (NLP) strategies, to clustering primarily based on semantic relevance, with the advantages defined.
Not solely do we all know the advantages of deciphering search intent, however we even have a lot of strategies at our disposal for scale and automation.
So, why do we’d like one other article on automating search intent?
Search intent is ever extra necessary now that AI search has arrived.
Whereas extra was typically within the 10 blue hyperlinks search period, the other is true with AI search know-how, as these platforms typically search to reduce the computing prices (per FLOP) with a view to ship the service.
SERPs Nonetheless Include The Finest Insights For Search Intent
The strategies thus far contain doing your personal AI, that’s, getting all the copy from titles of the rating content material for a given key phrase after which feeding it right into a neural community mannequin (which it’s important to then construct and take a look at) or utilizing NLP to cluster key phrases.
What in case you don’t have time or the data to construct your personal AI or invoke the Open AI API?
Whereas cosine similarity has been touted as the reply to serving to search engine optimization professionals navigate the demarcation of subjects for taxonomy and website constructions, I nonetheless preserve that search clustering by SERP outcomes is a far superior technique.
That’s as a result of AI may be very eager to floor its outcomes on SERPs and for good motive – it’s modelled on consumer behaviors.
There may be one other means that makes use of Google’s very personal AI to do the be just right for you, with out having to scrape all of the SERPs content material and construct an AI mannequin.
Let’s assume that Google ranks website URLs by the chance of the content material satisfying the consumer question in descending order. It follows that if the intent for 2 key phrases is similar, then the SERPs are more likely to be related.
For years, many search engine optimization professionals in contrast SERP outcomes for key phrases to deduce shared (or shared) search intent to remain on prime of core updates, so that is nothing new.
The worth-add right here is the automation and scaling of this comparability, providing each velocity and higher precision.
How To Cluster Key phrases By Search Intent At Scale Utilizing Python (With Code)
Assuming you will have your SERPs leads to a CSV obtain, let’s import it into your Python pocket book.
1. Import The Listing Into Your Python Pocket book
import pandas as pd
import numpy as np
serps_input = pd.read_csv('information/sej_serps_input.csv')
del serps_input['Unnamed: 0']
serps_input
Under is the SERPs file now imported right into a Pandas dataframe.
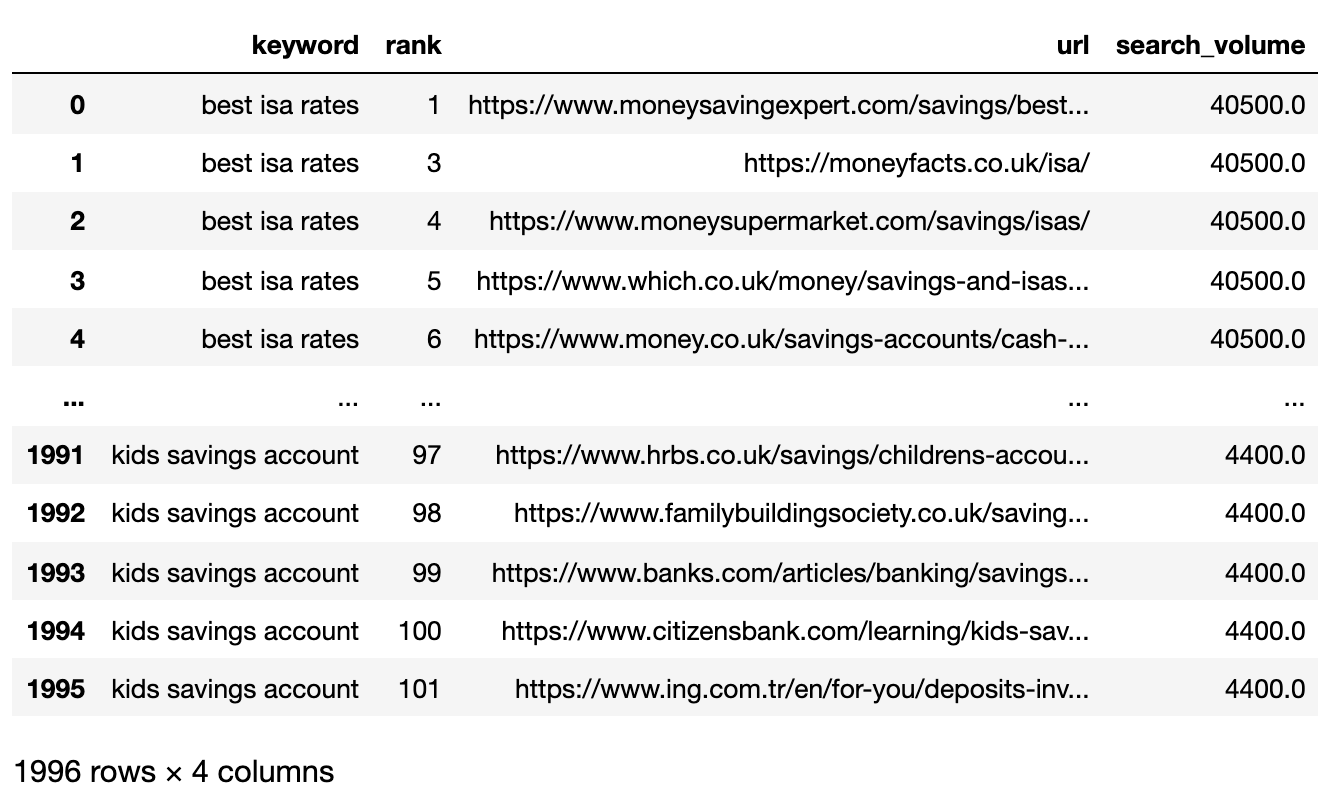 Picture from creator, April 2025
Picture from creator, April 20252. Filter Knowledge For Web page 1
We need to evaluate the Web page 1 outcomes of every SERP between key phrases.
We’ll cut up the dataframe into mini key phrase dataframes to run the filtering operate earlier than recombining right into a single dataframe, as a result of we need to filter on the key phrase stage:
# Break up
serps_grpby_keyword = serps_input.groupby("key phrase")
k_urls = 15
# Apply Mix
def filter_k_urls(group_df):
filtered_df = group_df.loc[group_df['url'].notnull()]
filtered_df = filtered_df.loc[filtered_df['rank'] <= k_urls]
return filtered_df
filtered_serps = serps_grpby_keyword.apply(filter_k_urls)
# Mix
## Add prefix to column names
#normed = normed.add_prefix('normed_')
# Concatenate with preliminary information body
filtered_serps_df = pd.concat([filtered_serps],axis=0)
del filtered_serps_df['keyword']
filtered_serps_df = filtered_serps_df.reset_index()
del filtered_serps_df['level_1']
filtered_serps_df
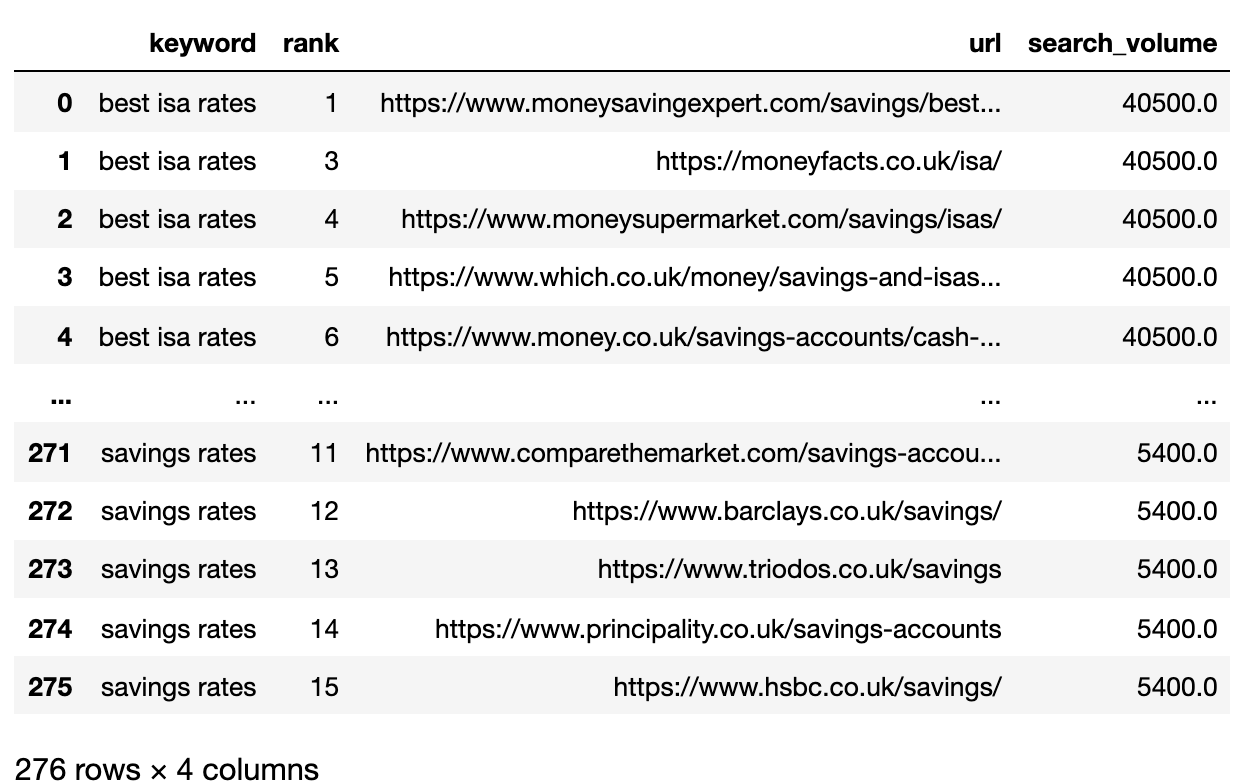 Picture from creator, April 2025
Picture from creator, April 20253. Convert Rating URLs To A String
As a result of there are extra SERP end result URLs than key phrases, we have to compress these URLs right into a single line to characterize the key phrase’s SERP.
Right here’s how:
# convert outcomes to strings utilizing Break up Apply Mix
filtserps_grpby_keyword = filtered_serps_df.groupby("key phrase")
def string_serps(df):
df['serp_string'] = ''.be part of(df['url'])
return df # Mix strung_serps = filtserps_grpby_keyword.apply(string_serps)
# Concatenate with preliminary information body and clear
strung_serps = pd.concat([strung_serps],axis=0)
strung_serps = strung_serps[['keyword', 'serp_string']]#.head(30)
strung_serps = strung_serps.drop_duplicates()
strung_serps
Under reveals the SERP compressed right into a single line for every key phrase.
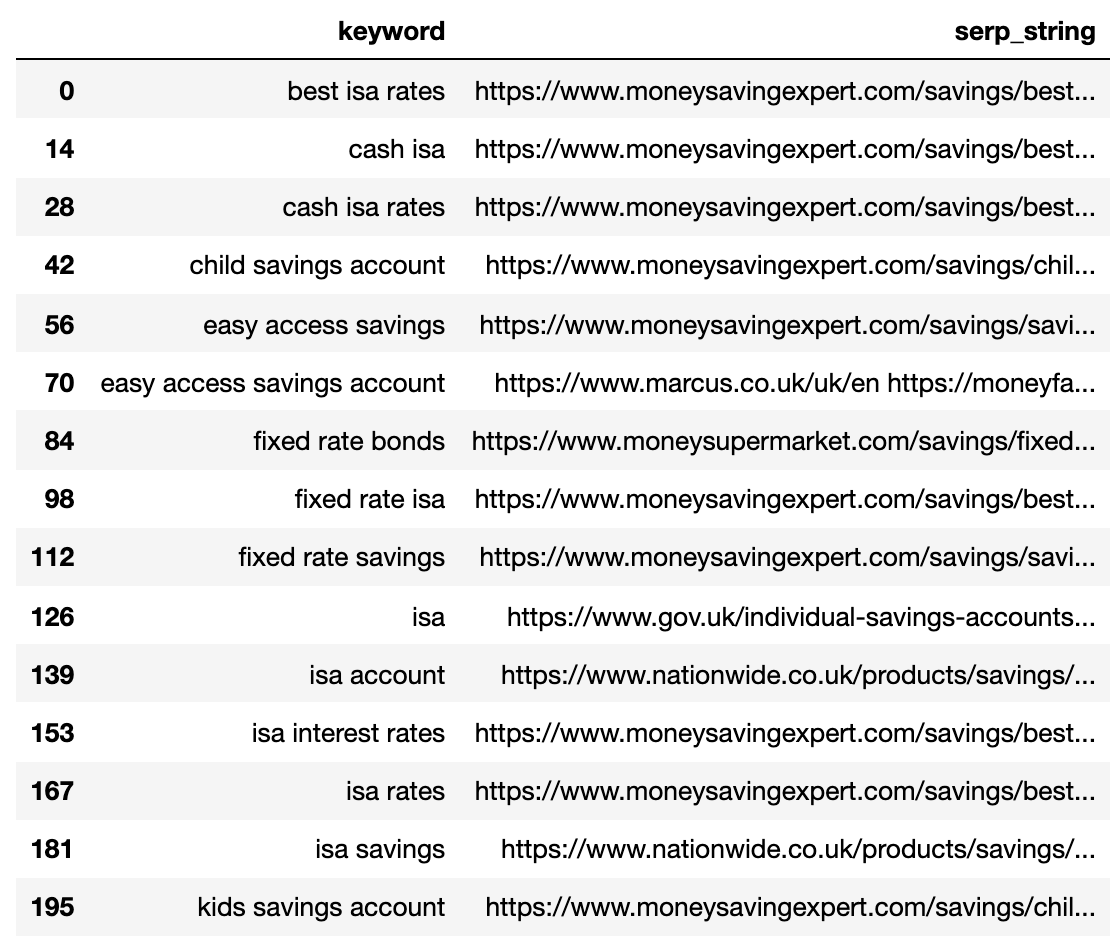 Picture from creator, April 2025
Picture from creator, April 20254. Evaluate SERP Distance
To carry out the comparability, we now want each mixture of key phrase SERP paired with different pairs:
# align serps
def serps_align(okay, df):
prime_df = df.loc[df.keyword == k]
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_a", 'key phrase': 'keyword_a'})
comp_df = df.loc[df.keyword != k].reset_index(drop=True)
prime_df = prime_df.loc[prime_df.index.repeat(len(comp_df.index))].reset_index(drop=True)
prime_df = pd.concat([prime_df, comp_df], axis=1)
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_b", 'key phrase': 'keyword_b', "serp_string_a" : "serp_string", 'keyword_a': 'key phrase'})
return prime_df
columns = ['keyword', 'serp_string', 'keyword_b', 'serp_string_b']
matched_serps = pd.DataFrame(columns=columns)
matched_serps = matched_serps.fillna(0)
queries = strung_serps.key phrase.to_list()
for q in queries:
temp_df = serps_align(q, strung_serps)
matched_serps = matched_serps.append(temp_df)
matched_serps

The above reveals all the key phrase SERP pair mixtures, making it prepared for SERP string comparability.
There isn’t a open-source library that compares record objects by order, so the operate has been written for you beneath.
The operate “serp_compare” compares the overlap of websites and the order of these websites between SERPs.
import py_stringmatching as sm
ws_tok = sm.WhitespaceTokenizer()
# Solely evaluate the highest k_urls outcomes
def serps_similarity(serps_str1, serps_str2, okay=15):
denom = okay+1
norm = sum([2*(1/i - 1.0/(denom)) for i in range(1, denom)])
#use to tokenize the URLs
ws_tok = sm.WhitespaceTokenizer()
#maintain solely first okay URLs
serps_1 = ws_tok.tokenize(serps_str1)[:k]
serps_2 = ws_tok.tokenize(serps_str2)[:k]
#get positions of matches
match = lambda a, b: [b.index(x)+1 if x in b else None for x in a]
#positions intersections of type [(pos_1, pos_2), ...]
pos_intersections = [(i+1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None]
pos_in1_not_in2 = [i+1 for i,j in enumerate(match(serps_1, serps_2)) if j is None]
pos_in2_not_in1 = [i+1 for i,j in enumerate(match(serps_2, serps_1)) if j is None]
a_sum = sum([abs(1/i -1/j) for i,j in pos_intersections])
b_sum = sum([abs(1/i -1/denom) for i in pos_in1_not_in2])
c_sum = sum([abs(1/i -1/denom) for i in pos_in2_not_in1])
intent_prime = a_sum + b_sum + c_sum
intent_dist = 1 - (intent_prime/norm)
return intent_dist
# Apply the operate
matched_serps['si_simi'] = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
# That is what you get
matched_serps[['keyword', 'keyword_b', 'si_simi']]

Now that the comparisons have been executed, we are able to begin clustering key phrases.
We will likely be treating any key phrases which have a weighted similarity of 40% or extra.
# group key phrases by search intent
simi_lim = 0.4
# be part of search quantity
keysv_df = serps_input[['keyword', 'search_volume']].drop_duplicates()
keysv_df.head()
# append matter vols
keywords_crossed_vols = serps_compared.merge(keysv_df, on = 'key phrase', how = 'left')
keywords_crossed_vols = keywords_crossed_vols.rename(columns = {'key phrase': 'matter', 'keyword_b': 'key phrase',
'search_volume': 'topic_volume'})
# sim si_simi
keywords_crossed_vols.sort_values('topic_volume', ascending = False)
# strip NAN
keywords_filtered_nonnan = keywords_crossed_vols.dropna()
keywords_filtered_nonnan
We now have the potential matter identify, key phrases SERP similarity, and search volumes of every.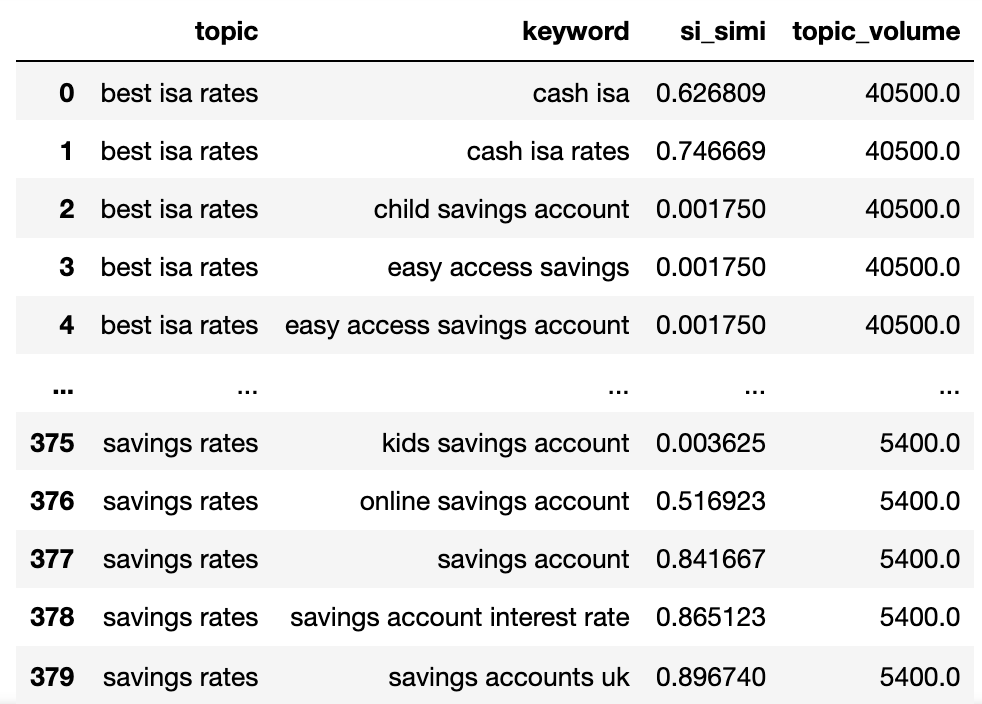
You’ll notice that key phrase and keyword_b have been renamed to matter and key phrase, respectively.
Now we’re going to iterate over the columns within the dataframe utilizing the lambda method.
The lambda method is an environment friendly solution to iterate over rows in a Pandas dataframe as a result of it converts rows to a listing versus the .iterrows() operate.
Right here goes:
queries_in_df = record(set(matched_serps['keyword'].to_list()))
topic_groups = {}
def dict_key(dicto, keyo):
return keyo in dicto
def dict_values(dicto, vala):
return any(vala in val for val in dicto.values())
def what_key(dicto, vala):
for okay, v in dicto.gadgets():
if vala in v:
return okay
def find_topics(si, keyw, topc):
if (si >= simi_lim):
if (not dict_key(sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, topc)):
if (not dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
sim_topic_groups[keyw] = [keyw]
sim_topic_groups[keyw] = [topc]
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, keyw)
sim_topic_groups[d_key].append(topc)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (not dict_values(sim_topic_groups, keyw)) and (dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, topc)
sim_topic_groups[d_key].append(keyw)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (not topc in sim_topic_groups):
sim_topic_groups[keyw].append(topc)
sim_topic_groups[keyw].append(keyw)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (not keyw in sim_topic_groups) and (topc in sim_topic_groups):
sim_topic_groups[topc].append(keyw)
sim_topic_groups[topc].append(topc)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (topc in sim_topic_groups):
if len(sim_topic_groups[keyw]) > len(sim_topic_groups[topc]):
sim_topic_groups[keyw].append(topc)
[sim_topic_groups[keyw].append(x) for x in sim_topic_groups.get(topc)]
sim_topic_groups.pop(topc)
elif len(sim_topic_groups[keyw]) < len(sim_topic_groups[topc]):
sim_topic_groups[topc].append(keyw)
[sim_topic_groups[topc].append(x) for x in sim_topic_groups.get(keyw)]
sim_topic_groups.pop(keyw)
elif len(sim_topic_groups[keyw]) == len(sim_topic_groups[topc]):
if sim_topic_groups[keyw] == topc and sim_topic_groups[topc] == keyw:
sim_topic_groups.pop(keyw)
elif si < simi_lim:
if (not dict_key(non_sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups,keyw)):
non_sim_topic_groups[keyw] = [keyw]
if (not dict_key(non_sim_topic_groups, topc)) and (not dict_key(sim_topic_groups, topc)) and (not dict_values(sim_topic_groups,topc)):
non_sim_topic_groups[topc] = [topc]
Under reveals a dictionary containing all of the key phrases clustered by search intent into numbered teams:
{1: ['fixed rate isa',
'isa rates',
'isa interest rates',
'best isa rates',
'cash isa',
'cash isa rates'],
2: ['child savings account', 'kids savings account'],
3: ['savings account',
'savings account interest rate',
'savings rates',
'fixed rate savings',
'easy access savings',
'fixed rate bonds',
'online savings account',
'easy access savings account',
'savings accounts uk'],
4: ['isa account', 'isa', 'isa savings']}Let’s stick that right into a dataframe:
topic_groups_lst = []
for okay, l in topic_groups_numbered.gadgets():
for v in l:
topic_groups_lst.append([k, v])
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=['topic_group_no', 'keyword'])
topic_groups_dictdf
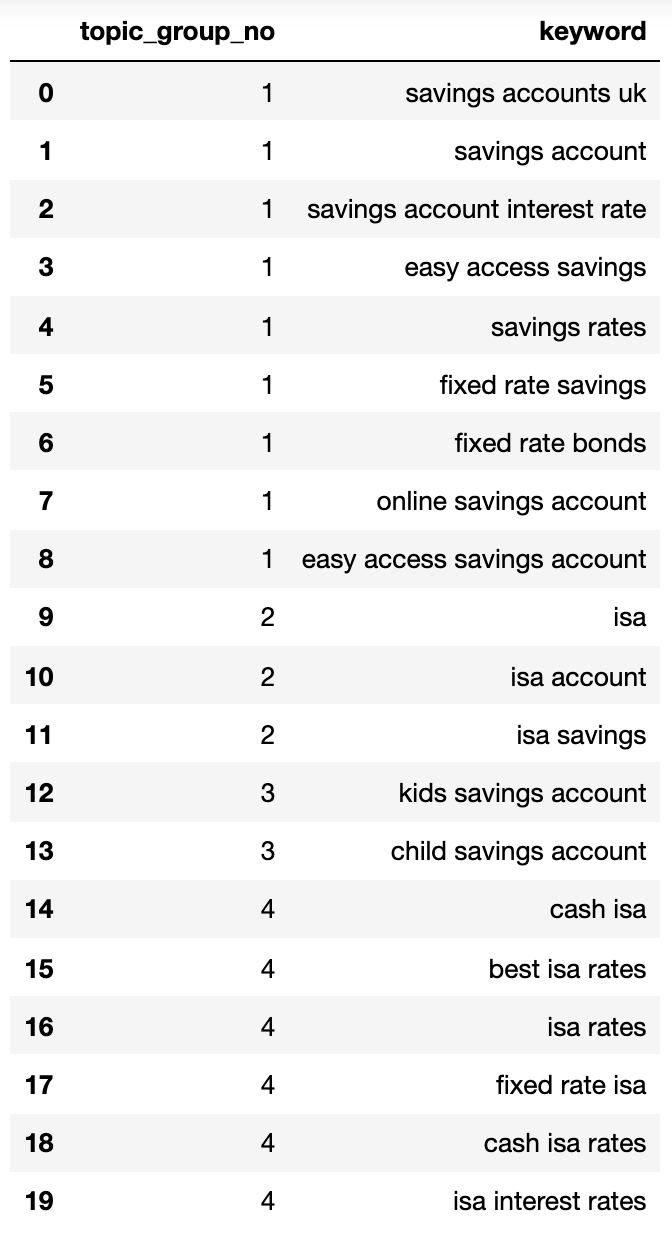 Picture from creator, April 2025
Picture from creator, April 2025The search intent teams above present an excellent approximation of the key phrases inside them, one thing that an search engine optimization skilled would probably obtain.
Though we solely used a small set of key phrases, the tactic can clearly be scaled to hundreds (if no more).
Activating The Outputs To Make Your Search Higher
After all, the above could possibly be taken additional utilizing neural networks, processing the rating content material for extra correct clusters and cluster group naming, as a few of the business merchandise on the market already do.
For now, with this output, you possibly can:
- Incorporate this into your personal search engine optimization dashboard techniques to make your traits and search engine optimization reporting extra significant.
- Construct higher paid search campaigns by structuring your Google Advertisements accounts by search intent for a better High quality Rating.
- Merge redundant aspect ecommerce search URLs.
- Construction a purchasing website’s taxonomy in response to search intent as a substitute of a typical product catalog.
I’m certain there are extra purposes that I haven’t talked about – be at liberty to touch upon any necessary ones that I’ve not already talked about.
In any case, your search engine optimization key phrase analysis simply obtained that little bit extra scalable, correct, and faster!
Obtain the full code right here in your personal use.
Extra Assets:
Featured Picture: Buch and Bee/Shutterstock











{kind=link}