Accountability & Security

Utilizing superior AI to repair vital software program vulnerabilities
At this time, we’re sharing early outcomes from our analysis on CodeMender, a brand new AI-powered agent that improves code safety mechanically.
Software program vulnerabilities are notoriously troublesome and time-consuming for builders to search out and repair, even with conventional, automated strategies like fuzzing. Our AI-based efforts like Large Sleep and OSS-Fuzz have demonstrated AI’s means to search out new zero-day vulnerabilities in well-tested software program. As we obtain extra breakthroughs in AI-powered vulnerability discovery, it is going to turn into more and more troublesome for people alone to maintain up.
CodeMender helps clear up this downside by taking a complete method to code safety that’s each reactive, immediately patching new vulnerabilities, and proactive, rewriting and securing current code and eliminating total lessons of vulnerabilities within the course of. Over the previous six months that we’ve been constructing CodeMender, we’ve got already upstreamed 72 safety fixes to open supply tasks, together with some as giant as 4.5 million traces of code.
By mechanically creating and making use of high-quality safety patches, CodeMender’s AI-powered agent helps builders and maintainers deal with what they do greatest — constructing good software program.
CodeMender in motion
CodeMender operates by leveraging the considering capabilities of latest Gemini Deep Assume fashions to provide an autonomous agent able to debugging and fixing advanced vulnerabilities.
To do that, the CodeMender agent is provided with strong instruments that permit it cause about code earlier than making modifications, and mechanically validate these modifications to ensure they’re appropriate and don’t trigger regressions.
Animation displaying CodeMender’s course of for fixing vulnerabilities.
Whereas giant language fashions are quickly enhancing, errors in code safety might be expensive. CodeMender’s automated validation course of ensures that code modifications are appropriate throughout many dimensions by solely surfacing for human assessment high-quality patches that, for instance, repair the foundation reason behind the difficulty, are functionally appropriate, trigger no regressions and observe type pointers.
As a part of our analysis, we additionally developed new methods and instruments that permit CodeMender cause about code and validate modifications extra successfully. This contains:
- Superior program evaluation: We developed instruments primarily based on superior program evaluation that embody static evaluation, dynamic evaluation, differential testing, fuzzing and SMT solvers. Utilizing these instruments to systematically scrutinize code patterns, management movement and information movement, CodeMender can higher determine the foundation causes of safety flaws and architectural weaknesses.
- Multi-agent programs: We developed special-purpose brokers that allow CodeMender to sort out particular elements of an underlying downside. For instance, CodeMender makes use of a big language model-based critique instrument that highlights the variations between the unique and modified code in an effort to confirm that the proposed modifications don’t introduce regressions, and self-correct as wanted.
Fixing vulnerabilities
To successfully patch a vulnerability, and forestall it from re-emerging, Code Mender makes use of a debugger, supply code browser, and different instruments to pinpoint root causes and devise patches. Now we have added two examples of CodeMender patching vulnerabilities within the video carousel under.
Instance #1: Figuring out the foundation reason behind a vulnerability
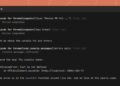
Right here’s a snippet of the agent’s reasoning in regards to the root trigger for a CodeMender-generated patch, after analyzing the outcomes of debugger output and a code search instrument.
Though the ultimate patch on this instance solely modified a number of traces of code, the foundation reason behind the vulnerability was not instantly clear. On this case, the crash report confirmed a heap buffer overflow, however the precise downside was elsewhere — an incorrect stack administration of Extensible Markup Language (XML) parts throughout parsing.
Instance #2: Agent is ready to create non-trivial patches
On this instance, the CodeMender agent was capable of give you a non-trivial patch that offers with a fancy object lifetime concern.
The agent was not solely in a position to determine the foundation reason behind the vulnerability, however was additionally capable of modify a very customized system for producing C code inside the venture.
Proactively rewriting current code for higher safety
We additionally designed CodeMender to proactively rewrite current code to make use of safer information buildings and APIs.
For instance, we deployed CodeMender to use -fbounds-safety annotations to components of a broadly used picture compression library known as libwebp. When -fbounds-safety annotations are utilized, the compiler provides bounds checks to the code to forestall an attacker from exploiting a buffer overflow or underflow to execute arbitrary code.
A number of years in the past, a heap buffer overflow vulnerability in libwebp (CVE-2023-4863) was utilized by a menace actor as a part of a zero-click iOS exploit. With -fbounds-safety annotations, this vulnerability, together with most different buffer overflows within the venture the place we have utilized annotations, would’ve been rendered unexploitable endlessly.
Within the video carousel under we present examples of the agent’s decision-making course of, together with the validation steps.
Instance #1: Agent’s reasoning steps
On this instance, the CodeMender agent is requested to deal with the next -fbounds-safety error on bit_depths pointer:
Instance #2: Agent mechanically corrects errors and take a look at failures
One other of CodeMender’s key options is its means to mechanically appropriate new errors and any take a look at failures that come up from its personal annotations. Right here is an instance of the agent recovering from a compilation error.
Instance #3: Agent validates the modifications
On this instance, the CodeMender agent modifies a operate after which makes use of the LLM decide instrument configured for useful equivalence to confirm that the performance stays intact. When the instrument detects a failure, the agent self-corrects primarily based on the LLM decide’s suggestions.
Making software program safe for everybody
Whereas our early outcomes with CodeMender are promising, we’re taking a cautious method, specializing in reliability. At the moment, all patches generated by CodeMender are reviewed by human researchers earlier than they’re submitted upstream.
Utilizing CodeMender, we have already begun submitting patches to varied vital open-source libraries, a lot of which have already been accepted and upstreamed. We’re progressively ramping up this course of to make sure high quality and systematically handle suggestions from the open-source group.
We’ll even be progressively reaching out to maintainers of vital open supply tasks with CodeMender-generated patches. By iterating on suggestions from this course of, we hope to launch CodeMender as a instrument that can be utilized by all software program builders to maintain their codebases safe.
We may have a lot of methods and outcomes to share, which we intend to publish as technical papers and experiences within the coming months. With CodeMender, we have solely simply begun to discover AI’s unbelievable potential to boost software program safety for everybody.
Acknowledgements
Credit (listed in alphabetical order):
Alex Rebert, Arman Hasanzadeh, Carlo Lemos, Charles Sutton, Dongge Liu, Gogul Balakrishnan, Hiep Chu, James Zern, Koushik Sen, Lihao Liang, Max Shavrick, Oliver Chang and Petros Maniatis.










{kind=link}