Mistral AI has launched Voxtral TTS, an open-weight text-to-speech mannequin that marks the corporate’s first main transfer into audio era. Following the discharge of its transcription and language fashions, Mistral is now offering the ultimate ‘output layer’ of the audio stack, positioning itself as a direct competitor to proprietary voice APIs within the developer ecosystem.
Voxtral TTS is greater than only a artificial voice generator. It’s a high-performance, modular element designed to be built-in into real-time voice workflows. By releasing the mannequin beneath a CC BY-NC license, Mistral workforce continues its technique of enabling builders to construct and deploy frontier-grade capabilities with out the constraints of closed-source API pricing or knowledge privateness limitations.
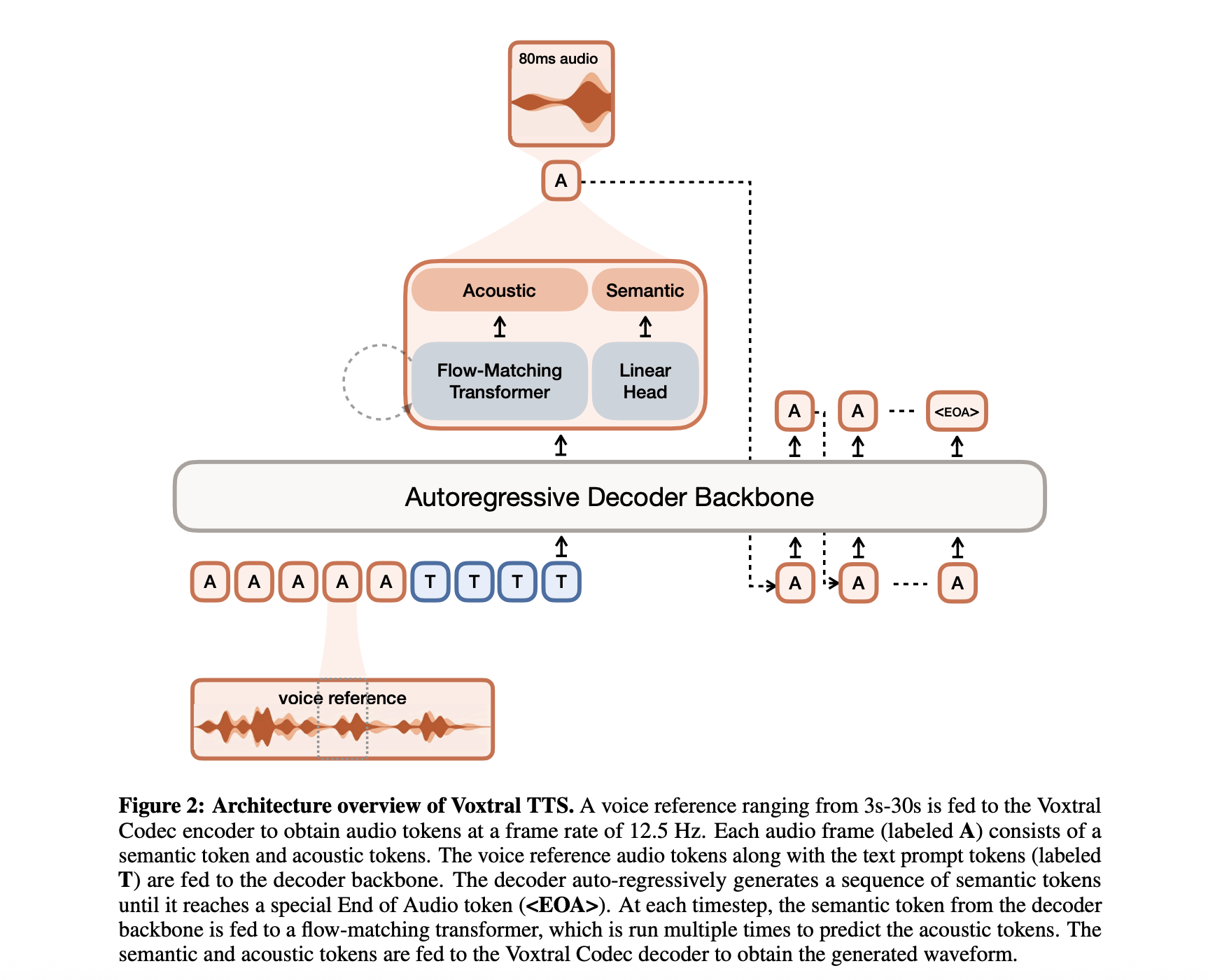
Structure: The 4B Parameter Hybrid Mannequin
Whereas many current developments in text-to-speech have centered on huge, resource-intensive architectures, Voxtral TTS is constructed with a deal with effectivity. The mannequin options 4B parameters, categorized as a light-weight mannequin by trendy frontier requirements.
This parameter rely is distributed throughout a hybrid structure designed to resolve the frequent trade-offs between era velocity and audio naturalness. The system contains three major parts:
- Transformer Decoder Spine: A 3.4B parameter module based mostly on the Ministral structure that handles the textual content understanding and predicts semantic representations of speech.
- Movement-Matching Acoustic Transformer: A 390M parameter module that converts these semantic representations into detailed acoustic options.
- Neural Audio Codec: A 300M parameter decoder that maps the acoustic options again right into a high-fidelity audio waveform.
By separating the ‘which means’ of the speech (semantic) from the ‘texture’ of the voice (acoustic), Voxtral TTS maintains long-range consistency whereas delivering the fine-grained nuances required for lifelike interplay.
Efficiency: 70ms Latency and Excessive Throughput
Within the context of production-grade AI, latency is the defining constraint. Mistral has optimized Voxtral TTS for low-latency streaming inference, making it appropriate for conversational brokers and real-time translation.
The mannequin achieves a 70ms mannequin latency for a typical 10-second voice pattern and 500-character enter. This velocity is essential for decreasing the perceived delay in voice-first functions, the place even small pauses can disrupt the circulation of human-machine interplay.
Moreover, the mannequin boasts a excessive Actual-Time Issue (RTF) of roughly 9.7x. This implies the system can synthesize audio almost ten instances quicker than it’s spoken. For builders, this throughput interprets to decrease compute prices and the flexibility to deal with high-concurrency workloads on commonplace inference {hardware}.
World Attain: 9 Languages and Dialect Accuracy
Voxtral TTS is natively multilingual, supporting 9 languages out of the gate: English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, and Arabic.
The coaching goal for the mannequin goes past easy phonetic translation. Mistral has emphasised the mannequin’s capacity to seize various dialects, recognizing the delicate shifts in cadence and prosody that distinguish regional audio system. This technical precision makes the mannequin an efficient software for world functions—from worldwide buyer assist to localized content material creation—the place a generic, ‘flattened’ accent usually fails to go the human check.
Adaptive Voice Adaptation
One of many standout options for AI devs is the mannequin’s ease of voice adaptation. Voxtral TTS helps zero-shot and few-shot voice cloning, permitting it to adapt to a brand new voice utilizing as little as 3 seconds of reference audio.
This functionality permits for the creation of constant model voices or personalised consumer experiences with out the necessity for intensive fine-tuning. As a result of the mannequin makes use of a factorized illustration, it could possibly apply the traits of a reference voice (timbre, tone, and pitch) to any generated textual content whereas sustaining the proper linguistic prosody of the goal language.
Benchmarks: A Problem to the Proprietary Giants
Mistral’s evaluations deal with how Voxtral TTS stacks up towards the present business leaders in artificial speech, particularly ElevenLabs. In human choice exams carried out by native audio system, Voxtral TTS demonstrated vital beneficial properties in naturalness and expressivity.
- Vs. ElevenLabs Flash v2.5: Voxtral TTS achieved a 68.4% win charge in multilingual voice cloning evaluations.
- Vs. ElevenLabs v3: The mannequin achieved parity or larger scores in speaker similarity, proving that an open-weight mannequin can successfully match the constancy of probably the most superior proprietary flagship voices.
These benchmarks counsel that for a lot of enterprise use circumstances, the efficiency hole between open-source instruments and high-cost APIs has successfully closed.

Deployment and Integration
Voxtral TTS is designed to operate as a part of a complete Audio Intelligence stack. It integrates natively with Voxtral Transcribe, creating an end-to-end speech-to-speech (S2S) pipeline.
For AI builders constructing on native or personal cloud infrastructure, the mannequin’s small footprint is a major benefit. Mistral’s workforce has confirmed that the mannequin is environment friendly sufficient to run on commonplace smartphone and laptop computer {hardware} as soon as quantized. This ‘edge-readiness’ permits for a brand new class of personal, offline functions, from safe company assistants to on-device accessibility instruments.
| Specification | Metric |
| Mannequin Dimension | 4B Parameters |
| Latency (10s voice / 500 chars) | 70ms |
| Actual-Time Issue (RTF) | ~9.7x |
| Supported Languages | 9 |
| Reference Audio Wanted | 3 – 30 seconds |
| License | CC BY-NC |
Key Takeaways
- Excessive-Effectivity 4B Parameter Mannequin: Voxtral TTS is a frontier open-weight mannequin with a 4B parameter footprint, using a hybrid structure that mixes auto-regressive semantic era with flow-matching for acoustic particulars.
- Extremely-Low 70ms Latency: Optimized for real-time functions, the mannequin achieves a 70ms mannequin latency for a typical 10-second voice pattern (500-character enter) and a formidable Actual-Time Issue (RTF) of roughly 9.7x.
- Superior Multilingual Efficiency: The mannequin helps 9 languages (English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, and Arabic) and outperformed ElevenLabs Flash v2.5 with a 68.4% win charge in human choice exams for multilingual voice cloning.
- On the spot Voice Adaptation: Builders can obtain high-fidelity voice cloning with as little as 3 seconds of reference audio, enabling zero-shot cross-lingual adaptation the place a speaker’s distinctive id is preserved throughout totally different languages.
- Full Audio Stack Integration: Designed because the ‘output layer’ of a unified audio intelligence pipeline, it plugs natively into Voxtral Transcribe to create low-latency, end-to-end speech-to-speech workflows.
Try the Paper, Mannequin Weight and Technical particulars. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as properly.

![The AI Search Content material Optimization Guidelines [With Google Sheets]](https://blog.aimactgrow.com/wp-content/uploads/2025/06/ai-search-optimization-checklist-120x86.png)








{kind=link}