
A beforehand unknown vulnerability in OpenAI ChatGPT allowed delicate dialog knowledge to be exfiltrated with out consumer data or consent, based on new findings from Test Level.
“A single malicious immediate might flip an in any other case unusual dialog right into a covert exfiltration channel, leaking consumer messages, uploaded information, and different delicate content material,” the cybersecurity firm stated in a report revealed at present. “A backdoored GPT might abuse the identical weak point to acquire entry to consumer knowledge with out the consumer’s consciousness or consent.”
Following accountable disclosure, OpenAI addressed the difficulty on February 20, 2026. There isn’t any proof that the difficulty was ever exploited in a malicious context.
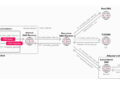
Whereas ChatGPT is constructed with numerous guardrails to stop unauthorized knowledge sharing or generate direct outbound community requests, the newly found vulnerability bypasses these safeguards completely by exploiting a facet channel originating from the Linux runtime utilized by the substitute intelligence (AI) agent for code execution and knowledge evaluation.
Particularly, it abuses a hidden DNS-based communication path as a “covert transport mechanism” by encoding data into DNS requests to get round seen AI guardrails. What’s extra, the identical hidden communication path may very well be used to ascertain distant shell entry contained in the Linux runtime and obtain command execution.
Within the absence of any warning or consumer approval dialog, the vulnerability creates a safety blind spot, with the AI system assuming that the setting was remoted.
As an illustrative instance, an attacker might persuade a consumer to stick a malicious immediate by passing it off as a strategy to unlock premium capabilities totally free or enhance ChatGPT’s efficiency. The menace will get magnified when the method is embedded inside customized GPTs, because the malicious logic may very well be baked into it versus tricking a consumer into pasting a specifically crafted immediate.
“Crucially, as a result of the mannequin operated underneath the idea that this setting couldn’t ship knowledge outward straight, it didn’t acknowledge that conduct as an exterior knowledge switch requiring resistance or consumer mediation,” Test Level defined. “In consequence, the leakage didn’t set off warnings about knowledge leaving the dialog, didn’t require specific consumer affirmation, and remained largely invisible from the consumer’s perspective.”
With instruments like ChatGPT more and more embedded in enterprise environments and customers importing extremely private data, vulnerabilities like these underscore the necessity for organizations to implement their very own safety layer to counter immediate injections and different surprising conduct in AI programs.
“This analysis reinforces a tough fact for the AI period: do not assume AI instruments are safe by default,” Eli Smadja, head of analysis at Test Level Analysis, stated in an announcement shared with The Hacker Information.

“As AI platforms evolve into full computing environments dealing with our most delicate knowledge, native safety controls are not enough on their very own. Organizations want impartial visibility and layered safety between themselves and AI distributors. That is how we transfer ahead safely — by rethinking safety structure for AI, not reacting to the subsequent incident.”
The event comes as menace actors have been noticed publishing net browser extensions (or updating present ones) that have interaction within the doubtful observe of immediate poaching to silently siphon AI chatbot conversations with out consumer consent, highlighting how seemingly innocent add-ons might turn into a channel for knowledge exfiltration.
“It virtually goes with out saying that these plugins open the doorways to a number of dangers, together with id theft, focused phishing campaigns, and delicate knowledge being put up on the market on underground boards,” Expel researcher Ben Nahorney stated. “Within the case of organizations the place staff might have unwittingly put in these extensions, they might have uncovered mental property, buyer knowledge, or different confidential data.”
Command Injection Vulnerability in OpenAI Codex Results in GitHub Token Compromise
The findings additionally coincide with the invention of a important command injection vulnerability in OpenAI’s Codex, a cloud-based software program engineering agent, that would have been exploited to steal GitHub credential knowledge and finally compromise a number of customers interacting with a shared repository.

“The vulnerability exists inside the job creation HTTP request, which permits an attacker to smuggle arbitrary instructions by means of the GitHub department title parameter,” BeyondTrust Phantom Labs researcher Tyler Jespersen stated in a report shared with The Hacker Information. “This may end up in the theft of a sufferer’s GitHub Consumer Entry Token – the identical token Codex makes use of to authenticate with GitHub.”
The problem, per BeyondTrust, stems from improper enter sanitization when processing GitHub department names throughout job execution on the cloud. Due to this inadequacy, an attacker might inject arbitrary instructions by means of the department title parameter in an HTTPS POST request to the backend Codex API, execute malicious payloads contained in the agent’s container, and retrieve delicate authentication tokens.
“This granted lateral motion and skim/write entry to a sufferer’s total codebase,” Kinnaird McQuade, chief safety architect at BeyondTrust, stated in a publish on X. It has been patched by OpenAI as of February 5, 2026, after it was reported on December 16, 2025. The vulnerability impacts the ChatGPT web site, Codex CLI, Codex SDK, and the Codex IDE Extension.
The cybersecurity vendor stated the department command injection method is also prolonged to steal GitHub Set up Entry tokens and execute bash instructions on the code assessment container every time @codex is referenced in GitHub.
“With the malicious department arrange, we referenced Codex in a touch upon a pull request (PR),” it defined. “Codex then initiated a code assessment container and created a job towards our repository and department, executing our payload and forwarding the response to our exterior server.”
The analysis additionally highlights a rising threat the place the privileged entry granted to AI coding brokers might be weaponized to supply a “scalable assault path” into enterprise programs with out triggering conventional safety controls.
“As AI brokers turn into extra deeply built-in into developer workflows, the safety of the containers they run in – and the enter they devour – have to be handled with the identical rigor as some other software safety boundary,” BeyondTrust stated. “The assault floor is increasing, and the safety of those environments must maintain tempo.”








{kind=link}