This text outlines important methods for securing AI chatbots by way of strong authorization strategies. Through the use of instruments like Pinecone, Supabase, and Microsoft Copilot, it introduces methods comparable to metadata filtering, row-level safety, and identity-based entry management, aiming to guard delicate information whereas optimizing AI-driven workflows.
AI chatbots are revolutionizing how organizations work together with information, delivering advantages like personalised buyer assist, improved inside information administration, and environment friendly automation of enterprise workflows. Nonetheless, with this elevated functionality comes the necessity for sturdy authorization mechanisms to stop unauthorized entry to delicate information. As chatbots develop extra clever and highly effective, strong authorization turns into vital for safeguarding customers and organizations.
It is a 101 information to take builders by way of the totally different methods and suppliers accessible so as to add strong and granular authorization to AI chatbots. By taking Pinecone, Supabase, and Microsoft Copilot as references, we’ll dive into real-world methods like metadata filtering, row-level safety (RLS), and identity-based entry management. We’ll additionally cowl how OAuth/OIDC, JWT claims, and token-based authorization safe AI-driven interactions.
Lastly, we’ll talk about how combining these strategies helps create safe and scalable AI chatbots tailor-made to your group’s wants.
Pinecone, a vector database designed for AI functions, simplifies authorization by way of metadata filtering. This methodology permits vectors to be tagged with metadata (e.g., consumer roles or departments) and filtered throughout search operations. It’s notably efficient in AI chatbot eventualities, the place you need to be certain that solely approved customers can entry particular information primarily based on predefined metadata guidelines.
Understanding vector similarity search
In vector similarity search, we construct vector representations of information (comparable to photos, textual content, or recipes), retailer them in an index (a specialised database for vectors), after which search that index with one other question vector.
This is identical precept that powers Google’s search engine, which identifies how your search question aligns with a web page’s vector illustration. Equally, platforms like Netflix, Amazon, and Spotify depend on vector similarity search to suggest reveals, merchandise, or music by evaluating customers’ preferences and figuring out related behaviors inside teams.
Nonetheless, in terms of securing this information, it’s vital to implement authorization filters in order that search outcomes are restricted primarily based on the consumer’s roles, departments, or different context-specific metadata.
Introduction to metadata filtering
Metadata filtering provides a layer of authorization to the search course of by tagging every vector with extra context, comparable to consumer roles, departments, or timestamps. For instance, vectors representing paperwork might embody metadata like:
- Person roles (e.g., solely “managers” can entry sure paperwork)
- Departments (e.g., information accessible solely to the “engineering” division)
- Dates (e.g., limiting information to paperwork from the final 12 months)
This filtering ensures that customers solely retrieve outcomes they’re approved to view.
Challenges in metadata filtering: pre-filtering vs. post-filtering
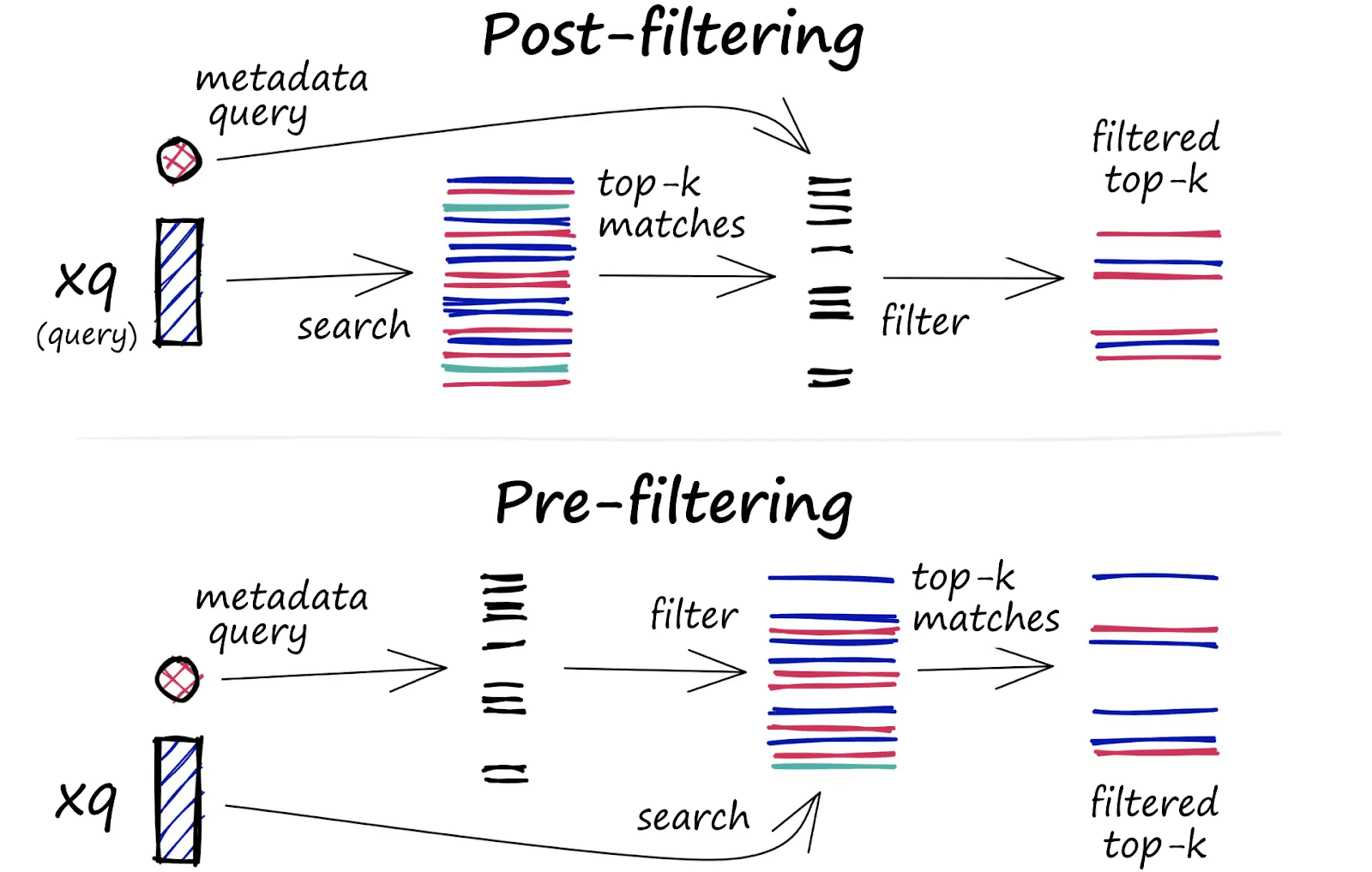
When making use of metadata filtering, two conventional strategies are generally used: Pre-filtering and Submit-filtering.
- Pre-filtering applies the metadata filter earlier than the search, limiting the dataset to related vectors. Whereas this ensures that solely approved vectors are thought of, it disrupts the effectivity of Approximate Nearest Neighbor (ANN) search algorithms, resulting in slower, brute-force searches.
- Submit-filtering, in distinction, performs the search first and applies the filter afterward. This avoids slowdowns from pre-filtering however dangers returning irrelevant outcomes if not one of the high matches meet the filtering circumstances. For instance, you would possibly retrieve fewer or no outcomes if not one of the high vectors cross the metadata filter.
To resolve these points, Pinecone introduces Single-Stage Filtering. This methodology merges the vector and metadata indexes, permitting for each velocity and accuracy. By imposing entry controls inside a single-stage filtering course of, Pinecone optimizes each efficiency and safety in real-time searches.
Making use of metadata filtering for authorization: code instance
Now, let’s discover the way to implement metadata filtering in Pinecone for a real-world AI chatbot use case. This instance demonstrates the way to insert vectors with metadata after which question the index utilizing metadata filters to make sure approved entry.
Open menu
import pinecone
# Initialize Pinecone
pinecone.init(api_key="your_api_key", setting="us-west1-gcp")
# Create an index
index_name = "example-index"
if index_name not already created:
pinecone.create_index(index_name, dimension=128, metric="cosine")
# Hook up with the index
index = pinecone.Index(index_name)
# Insert a vector with metadata
vector = [0.1, 0.2, 0.3, ..., 0.128] # Instance vector
metadata = {
"user_id": "user123",
"position": "admin",
"division": "finance"
}
# Upsert the vector with metadata
index.upsert(vectors=[("vector_id_1", vector, metadata)])On this instance, we’ve inserted a vector with related metadata, such because the user_id, position, and division, which may later be used for imposing entry management. The subsequent step entails querying the index whereas making use of a metadata filter to limit the outcomes primarily based on the consumer’s authorization profile.
Open menu
# Querying the index, limiting outcomes primarily based on metadata
query_vector = [0.15, 0.25, 0.35, ..., 0.128]
filter = {
"user_id": "user123", # Solely retrieve vectors belonging to this consumer
"position": {"$eq": "admin"} # Non-compulsory: match position
}
# Carry out the question with metadata filter
outcomes = index.question(queries=[query_vector], filter=filter, top_k=5)
# Show outcomes
for lead to outcomes["matches"]:
print(end result)By making use of the metadata filter throughout the question, we be certain that solely vectors that match the consumer’s metadata (e.g., consumer ID and position) are returned, successfully imposing authorization in real-time.
Implementing complicated filters for authorization
Metadata filtering can be prolonged to deal with extra complicated, multi-dimensional authorization eventualities. As an illustration, we are able to filter outcomes primarily based on a number of circumstances, comparable to limiting search outcomes to paperwork inside a particular division and date vary.
Open menu
# Question with a number of metadata circumstances
filter = {
"division": {"$eq": "finance"},
"date": {"$gte": "2023-01-01", "$lt": "2023-12-31"}
}
outcomes = index.question(queries=[query_vector], filter=filter, top_k=5)
# Show outcomes
for lead to outcomes["matches"]:
print(end result)This mixture of vector similarity search and metadata filtering creates a sturdy framework for fine-grained authorization. It ensures that AI chatbots can ship each excessive efficiency and safe, context-driven responses by limiting search outcomes to approved customers primarily based on a number of dimensions comparable to position, division, and time-frame.
Need to be taught extra about metadata filtering and see a totally built-out instance with Descope and Pinecone? Take a look at our weblog under:
Add Auth and Entry Management to a Pinecone RAG App
Supabase: Row-level safety for vector information

Metadata filtering is right for broad entry management primarily based on classes or tags (e.g., limiting search outcomes by division or position). Nonetheless, it falls quick when strict management is required over who can view, modify, or retrieve particular data.
In enterprise methods that depend on relational databases, comparable to monetary platforms, entry typically must be enforced right down to particular person transaction data or buyer information rows. Supabase row-level safety (RLS) permits this by defining insurance policies that implement fine-grained permissions on the row stage, primarily based on consumer attributes or exterior permission methods utilizing Overseas Information Wrappers (FDWs).
Whereas metadata filtering excels at managing entry to non-relational, vector-based information—excellent for AI-powered searches or suggestion methods—Supabase RLS presents exact, record-level management, making it a greater match for environments that require strict permissions and compliance.
For added studying on Supabase and its RLS capabilities, take a look at our weblog under demonstrating the way to add SSO to Supabase with Descope.
Including SSO to Supabase With Descope
Implementing RLS for retrieval-augmented technology (RAG)
In retrieval-augmented technology (RAG) methods, like vector similarity searches in Pinecone, paperwork are damaged into smaller sections for extra exact search and retrieval.
Right here’s the way to implement RLS on this use case:
Open menu
-- Observe paperwork/pages/recordsdata/and so on
create desk paperwork (
id bigint main key generated all the time as identification,
identify textual content not null,
owner_id uuid not null references auth.customers (id) default auth.uid(),
created_at timestamp with time zone not null default now()
);
-- Retailer content material and embedding vector for every part
create desk document_sections (
id bigint main key generated all the time as identification,
document_id bigint not null references paperwork (id),
content material textual content not null,
embedding vector(384)
);On this setup, every doc is linked to an owner_id that determines entry. By enabling RLS, we are able to limit entry to solely the proprietor of the doc:
Open menu
-- Allow row stage safety
alter desk document_sections allow row stage safety;
-- Setup RLS for choose operations
create coverage "Customers can question their very own doc sections"
on document_sections for choose to authenticated utilizing (
document_id in (
choose id from paperwork the place (owner_id = (choose auth.uid()))
)
);As soon as RLS is enabled, each question on document_sections will solely return rows the place the presently authenticated consumer owns the related doc. This entry management is enforced even throughout vector similarity searches:
Open menu
-- Carry out internal product similarity primarily based on a match threshold
choose *
from document_sections
the place document_sections.embedding <#> embedding < -match_threshold
order by document_sections.embedding <#> embedding;This ensures that semantic search respects the RLS insurance policies, so customers can solely retrieve the doc sections they’re approved to entry.
Dealing with exterior consumer and doc information with international information wrappers
In case your consumer and doc information reside in an exterior database, Supabase’s assist for Overseas Information Wrappers (FDW) lets you connect with an exterior Postgres database whereas nonetheless making use of RLS. That is particularly helpful in case your current system manages consumer permissions externally.
Right here’s the way to implement RLS when coping with exterior information sources:
Open menu
-- Create international tables for exterior customers and paperwork
create schema exterior;
create extension postgres_fdw with schema exterior;
create server foreign_server
international information wrapper postgres_fdw
choices (host '', port '', dbname '');
create consumer mapping for authenticated
server foreign_server
choices (consumer 'postgres', password '');
import international schema public restrict to (customers, paperwork)
from server foreign_server into exterior;When you’ve linked the exterior information, you’ll be able to apply RLS insurance policies to filter doc sections primarily based on exterior information:
Open menu
create desk document_sections (
id bigint main key generated all the time as identification,
document_id bigint not null,
content material textual content not null,
embedding vector(384)
);
-- RLS for exterior information sources
create coverage "Customers can question their very own doc sections"
on document_sections for choose to authenticated utilizing (
document_id in (
choose id from exterior.paperwork the place owner_id = current_setting('app.current_user_id')::bigint
)
);On this instance, the app.current_user_id session variable is about initially of every request. This ensures that Postgres enforces fine-grained entry management primarily based on the exterior system’s permissions.
Whether or not you’re managing a easy user-document relationship or a extra complicated system with exterior information, the mixture of RLS and FDW from Supabase supplies a scalable, versatile answer for imposing authorization in your vector similarity searches.
This ensures strong entry management for customers whereas sustaining excessive efficiency in RAG methods or different AI-driven functions.
Each Pinecone metadata filtering and Supabase RLS supply highly effective authorization mechanisms, however they’re suited to various kinds of information and functions:
- Supabase RLS: Excellent for structured, relational information the place entry must be managed on the row stage, notably in functions that require exact permissions for particular person data (e.g., in RAG setups). Supabase RLS supplies tight management, with the pliability of integrating exterior methods by way of Overseas Information Wrappers (FDW).
- Pinecone Metadata Filtering: Fitted to non-relational, vector-based information in search or suggestion methods. It supplies dynamic, context-driven filtering utilizing metadata, which permits AI-driven functions to handle entry flexibly and effectively throughout retrieval.
When to decide on
- Select Pinecone in case your software focuses on AI-powered search or suggestion methods that depend on quick, scalable vector information searches with metadata-driven entry management.
- Select Supabase if you might want to management entry over particular person database rows for structured information, particularly in instances the place complicated permissions are wanted.
| Characteristic | Pinecone | Supabase |
| Authorization Mannequin | Metadata filtering on vectors | Row-level safety (RLS) on database rows |
| Scope | Vector-based filtering for search and suggestion methods | Database-level entry management for particular person rows and paperwork |
| Effectivity | Single-stage filtering for quick, large-scale searches | Postgres-enforced RLS for fine-grained information entry |
| Complexity | Easy to implement with metadata tags | Requires configuring insurance policies and guidelines in Postgres |
| Efficiency | Optimized for big datasets with fast search occasions | May be slower for big datasets if complicated RLS insurance policies are utilized |
| Integration with Exterior Methods | N/A | Helps Overseas Information Wrappers (FDW) to combine exterior databases |
| Excellent Use Instances | Search and suggestion methods, AI-powered buyer assist, SaaS apps dealing with non-relational or vector-based information | SaaS platforms with structured, relational information; enterprise functions requiring strict row-level management (e.g., finance, healthcare, compliance-heavy environments) |
Whereas each strategies have their strengths, neither totally covers complicated, organization-wide information entry wants. For a broader, multi-layered answer, Microsoft Purview supplies an instance of integrating parts of each approaches to handle information entry comprehensively throughout a number of methods and information sorts.
Microsoft 365 Copilot and Purview: a real-world instance of AI chatbot authorization
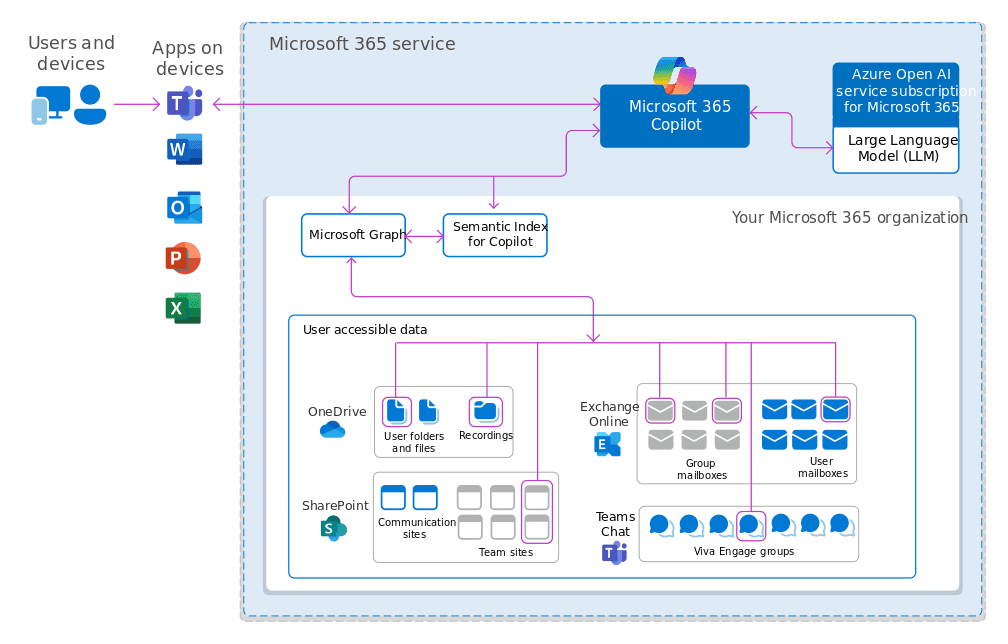
Microsoft 365 Copilot and Purview supply a multi-layered system for managing information entry that mixes metadata filtering, identity-based entry management, and utilization rights enforcement. This strategy integrates seamlessly with Microsoft Entra ID (previously Azure AD), making use of the identical authorization guidelines already configured for each inside and exterior customers throughout Microsoft companies.
Information merchandise in Microsoft Purview: Including enterprise context to information entry
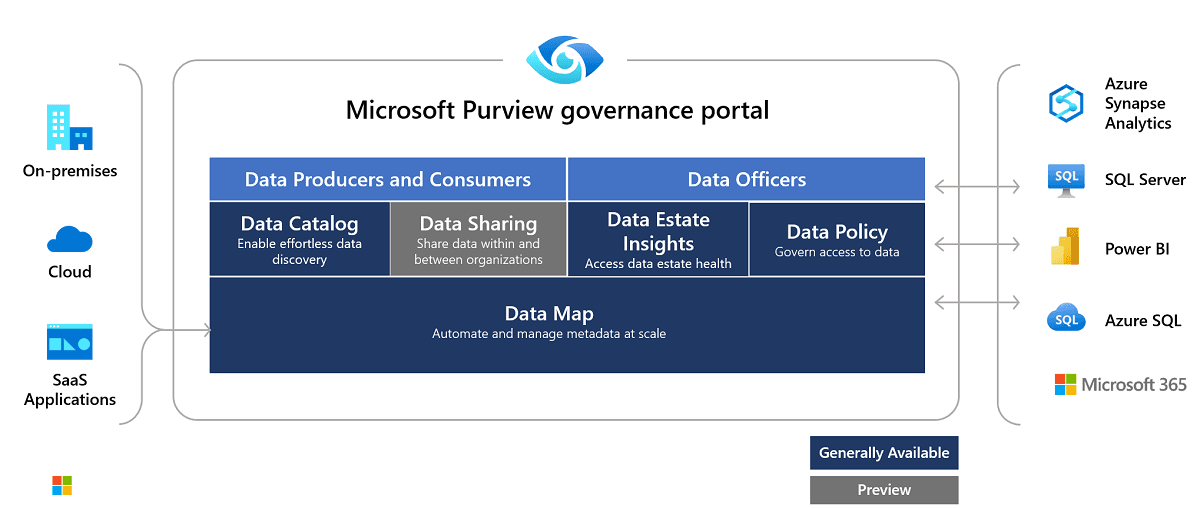
A key function of Microsoft Purview is the usage of information merchandise, that are collections of associated information property (comparable to tables, recordsdata, and reviews) organized round enterprise use instances. These information merchandise streamline information discovery and entry, guaranteeing governance insurance policies are persistently utilized.
Information maps present a complete view of how information flows by way of your group. They guarantee delicate information is correctly labeled and managed by monitoring the group, possession, and governance of information merchandise. For instance, monetary reviews marked with a “Confidential” label might be restricted to finance staff, whereas exterior auditors might have restricted entry primarily based on pre-configured guidelines.
Integration with Entra ID: Seamless authorization
Microsoft Entra ID enforces current authorization insurance policies throughout all Microsoft companies. This integration ensures that roles, permissions, and group memberships are mechanically revered throughout companies like SharePoint, Energy BI, and Microsoft 365 Copilot.
- Unified authorization: Worker roles and permissions configured in Entra ID decide which information a consumer can work together with, guaranteeing Copilot adheres to those self same guidelines.
- Exterior consumer entry: Entra ID simplifies entry management for exterior companions or distributors, permitting safe collaboration whereas respecting the identical sensitivity labels and permissions utilized to inside customers.
- Automated sensitivity labels: By leveraging sensitivity labels, Purview mechanically enforces encryption and utilization rights throughout all information merchandise, guaranteeing safe information dealing with, whether or not seen, extracted, or summarized by Copilot.
- Consistency throughout Microsoft ecosystem: Governance and authorization insurance policies stay constant throughout all Microsoft companies, offering seamless safety throughout instruments like SharePoint, Energy BI, and Trade On-line.
Advantages of Purview and Copilot
The mixing of Copilot, Purview, and Entra ID presents scalable, safe, and computerized enforcement of information entry insurance policies throughout your group. Whether or not for inside or exterior customers, this setup eliminates the necessity for handbook configuration of entry controls when deploying new companies like AI chatbots, offering a streamlined, enterprise-grade answer for information governance.
Choosing the proper authorization technique in your AI chatbot
Choosing the suitable authorization methodology is crucial for balancing safety, efficiency, and usefulness in AI chatbots:
- Pinecone metadata filtering: Greatest suited to vector-based information and AI-powered search or personalised content material supply. It supplies context-based management, best for non-relational information.
- Supabase row-level safety (RLS): Provides fine-grained management over particular person database data, making it excellent for SaaS functions the place customers want particular row-level entry in relational databases.
- Microsoft Enterprise Copilot: Excellent for enterprise-level functions that require identity-based entry throughout a number of information sorts and methods. It supplies a structured, business-oriented strategy to information governance.
Combining authentication and authorization options
Choosing the proper authorization technique is simply half the answer. Integrating a sturdy authentication system is equally necessary for a safe and seamless AI chatbot.
Utilizing an OIDC-compliant authentication supplier like Descope simplifies integration with third-party companies whereas managing customers, roles, and entry management by way of JWT-based tokens. This ensures that tokens can implement the fine-grained authorization insurance policies talked about above.
Listed below are the advantages of mixing AI authorization with a contemporary authentication system:
- Seamless integration: OIDC compliance simplifies connections to exterior methods utilizing customary authentication protocols.
- Dynamic entry management: JWT tokens, from companies like Descope or Supabase Auth, enable for real-time administration of roles and permissions guaranteeing versatile and safe entry management.
- Scalability: The mix of versatile authorization fashions (RLS or metadata filtering) with a robust authentication service permits your chatbot to scale securely, managing huge numbers of customers with out sacrificing safety.
To be taught extra about Descope capabilities for AI apps, go to this web page or take a look at our weblog under on including auth to a Subsequent.js AI chat app with Descope.
DocsGPT: Construct AI Chat With Auth Utilizing Subsequent.js & OpenAI
Conclusion
AI chatbots and AI brokers are reworking industries, however securing information with sturdy authorization is vital. Whether or not you use metadata filtering, row-level safety, identity-based entry management, or a blended mixture of any of them, every strategy presents distinct advantages for chatbot safety.
By integrating an OIDC-compliant authentication answer which manages customers and roles with JWT-based tokens, you’ll be able to construct a scalable and safe chatbot system. Choosing the proper mixture of instruments ensures each effectivity and information safety, making your chatbot appropriate for various enterprise wants.
Need to chat about auth and AI with like-minded builders? Be part of Descope’s dev neighborhood AuthTown to ask questions and keep within the loop.











{kind=link}