Everybody has an opinion on llms.txt, however relating to precise proof we’ve got solely single-site logs or the odd small-scale experiment.
Utilizing Ahrefs Net Analytics and Bot Analytics, we analyzed the server logs and dwell visitors of 137K domains, plus the person brokers hitting all of them.
Right here’s what we discovered.
High findings
- 28% of the 137K domains utilizing Ahrefs Net Analytics publish an llms.txt file.
- 97% of these recordsdata obtained zero visitors in Might 2026. Nothing fetched them at all.
- 96% of the requests that did attain llms.txt recordsdata got here from bots.
- 19.5% of fetches got here from named AI instruments (of the three% of recordsdata that weren’t ignored). GPTBot is prime and Claude-Code is second, forward of each AI search and assistant bot.
- 12% of fetches come from the business learning itself: GEO/AEO instruments, llms.txt checker instruments, and researchers.
- Zero requests got here from AI bots for llms.txt recordsdata that don’t exist. They by no means go searching.
- The Chrome Lighthouse llms.txt audit produced roughly 1 in 1,000 fetches.
In late Might 2026, Google took either side of the llms.txt argument in beneath a week.
Its new information on optimizing for generative AI options instructed web site homeowners, in a bit actually titled “mythbusting”, that machine-readable recordsdata like llms.txt aren’t wanted to seem in generative AI search.
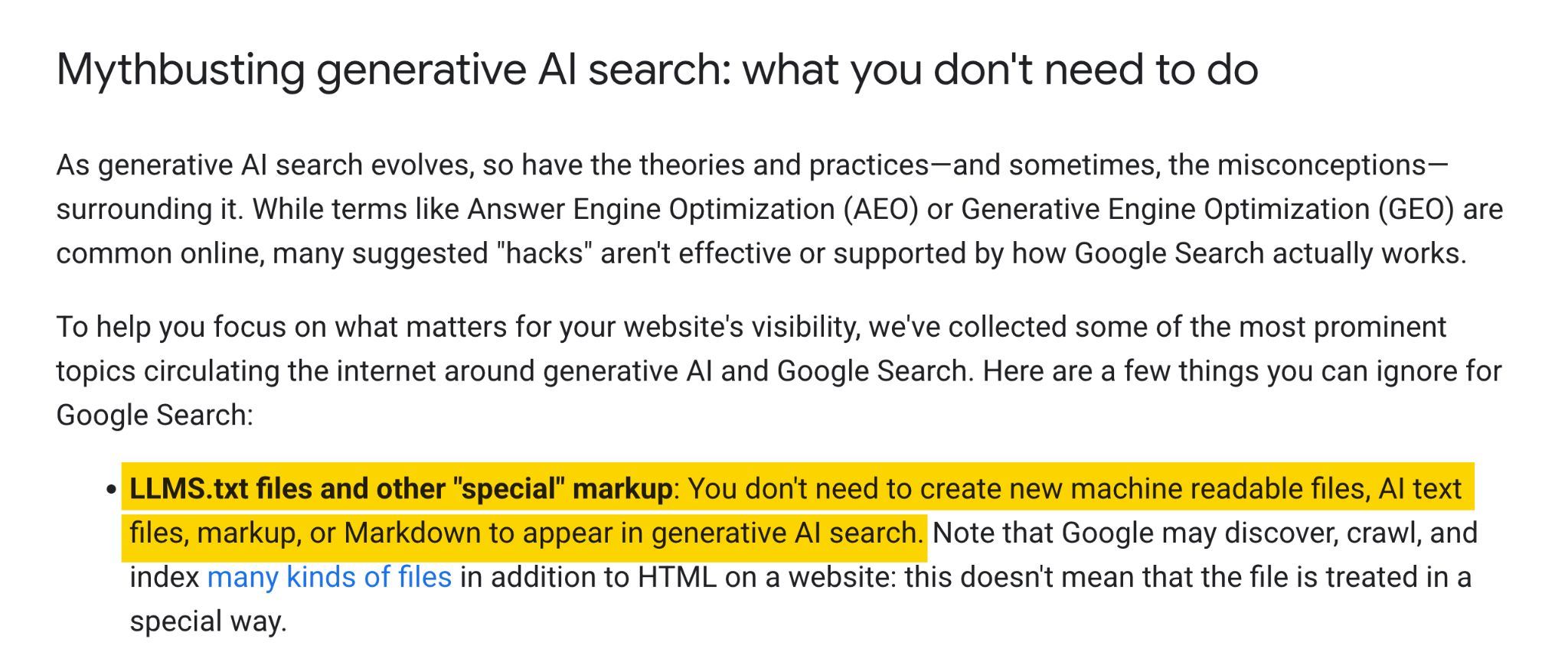
Days later, the Chrome group shipped an llms.txt examine inside Lighthouse’s experimental Agentic Searching audits, with documentation explaining that with out the file, brokers might spend extra time crawling a web site to know its construction
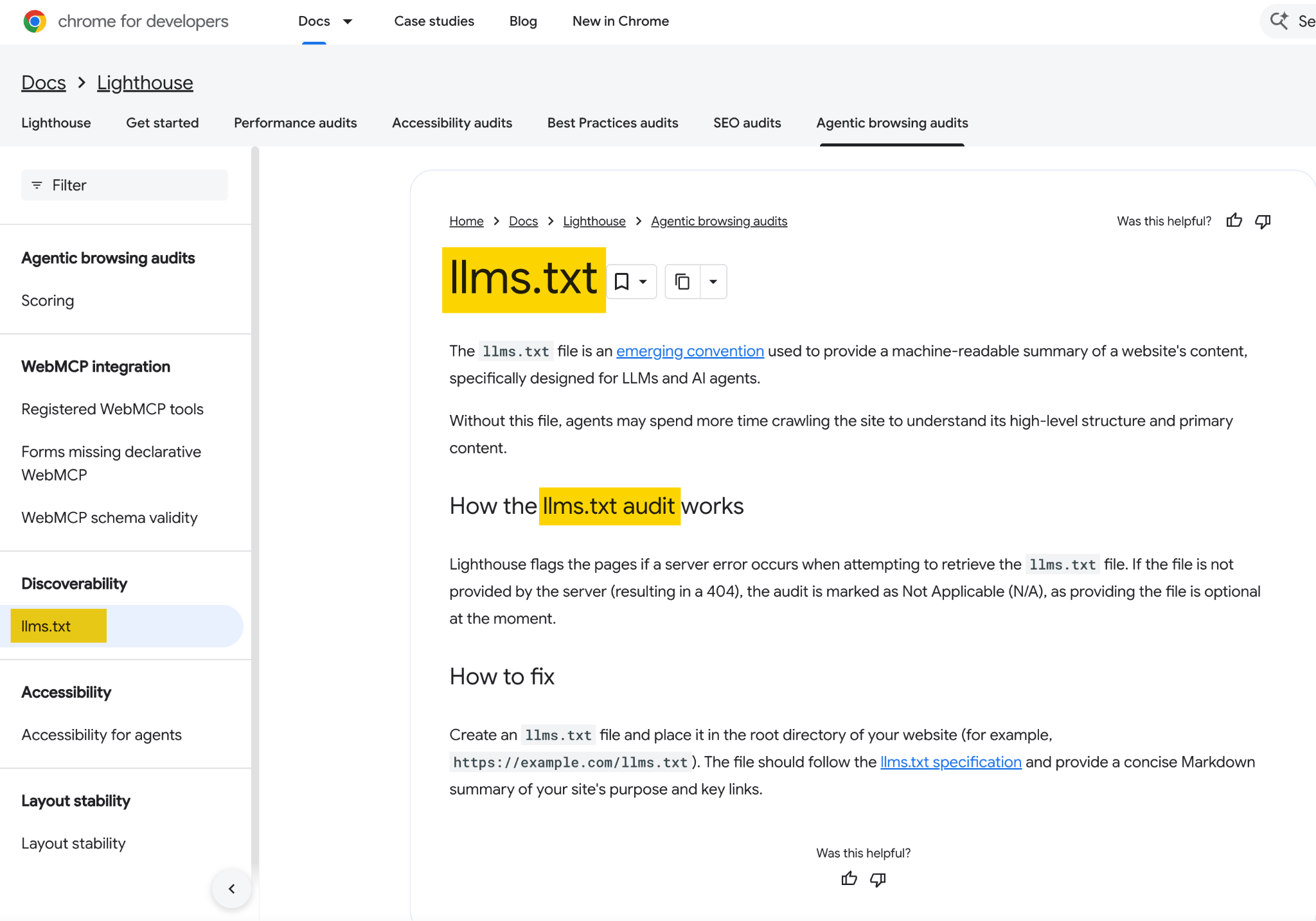
When Lily Ray pressed Google’s John Mueller on the contradiction, he defined that llms.txt is “not accomplished for search.” It’s a “momentary crutch, maybe to avoid wasting tokens” for AI coding instruments parsing developer documentation—not one thing non-developer websites want to fret about.
He additionally said that web site homeowners who examine their logs will discover little or no AI agent visitors.
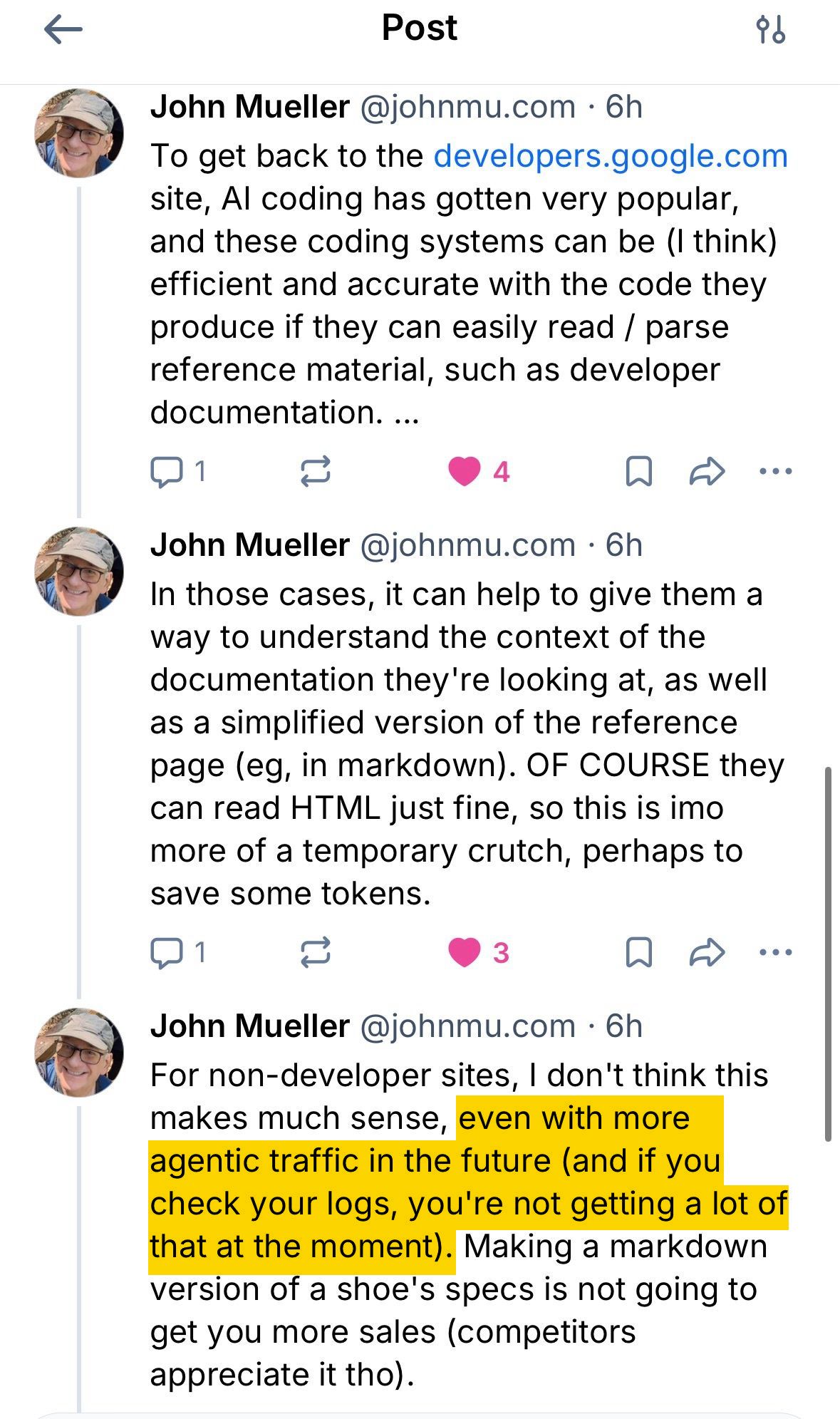
That is one thing we determined to take a look at.
What llms.txt is (and what it isn’t)
- It’s not the follow of publishing markdown copies of your net pages, a separate tactic with its personal issues.
- And regardless of the filename, it’s not a robots.txt-style directive: it controls nothing and blocks nothing.
This examine measures the index file, and solely the index file.
Our examine focuses on all 137,210 domains in Ahrefs Net Analytics that obtained visitors in Might 2026.
We checked every area root for an llms.txt returning HTTP 200, then used Ahrefs Bot Analytics to look at each request to /llms.txt paths throughout the inhabitants, cut up by HTTP response (200 vs 404) and categorized by channel and particular person person agent.
To rule out tender 404s and phantom recordsdata, we additionally confirmed every file was precise Markdown slightly than HTML, and screened titles and content material for error alerts like “404” or “Web page not discovered”
It’s vital to observe:
- Ahrefs Net Analytics clients skew extra technical and Search engine optimization-aware than the online at massive, so deal with the 28% adoption determine as an higher certain.
- We didn’t explicitly examine whether or not a file was well-formed towards the llms.txt specification.
Google Search’s steerage says you possibly can skip it, the Chrome group audits for it, and Mueller calls it a stopgap for coding instruments.
So amid all of the combined messages, how widespread is llms.txt really? Among the many 137K domains in our examine, 28% publish these recordsdata.
A couple of in 4 domains (38,000) in our inhabitants have adopted llms.txt, even if no main AI platform has ever dedicated to studying it.
Adoption has been pushed by hypothesis that AI platforms might begin consuming the file, slightly than by any affirmation that they do.
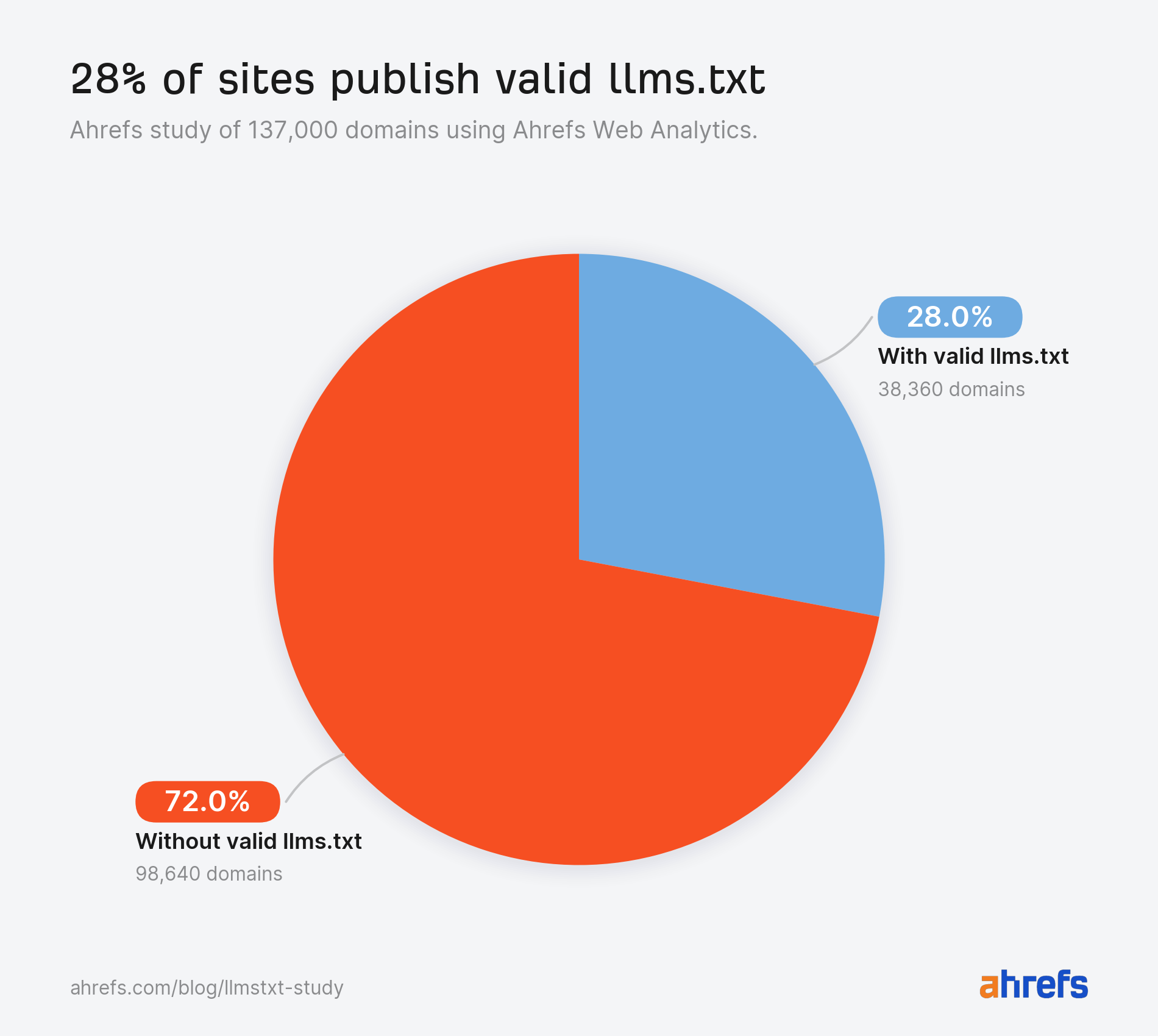
Virtually each llms.txt file in our examine is unread.
Of the ~38,000 domains with a sound file, 97% noticed no requests for it by any means in Might.
No bots. No people. Nothing.
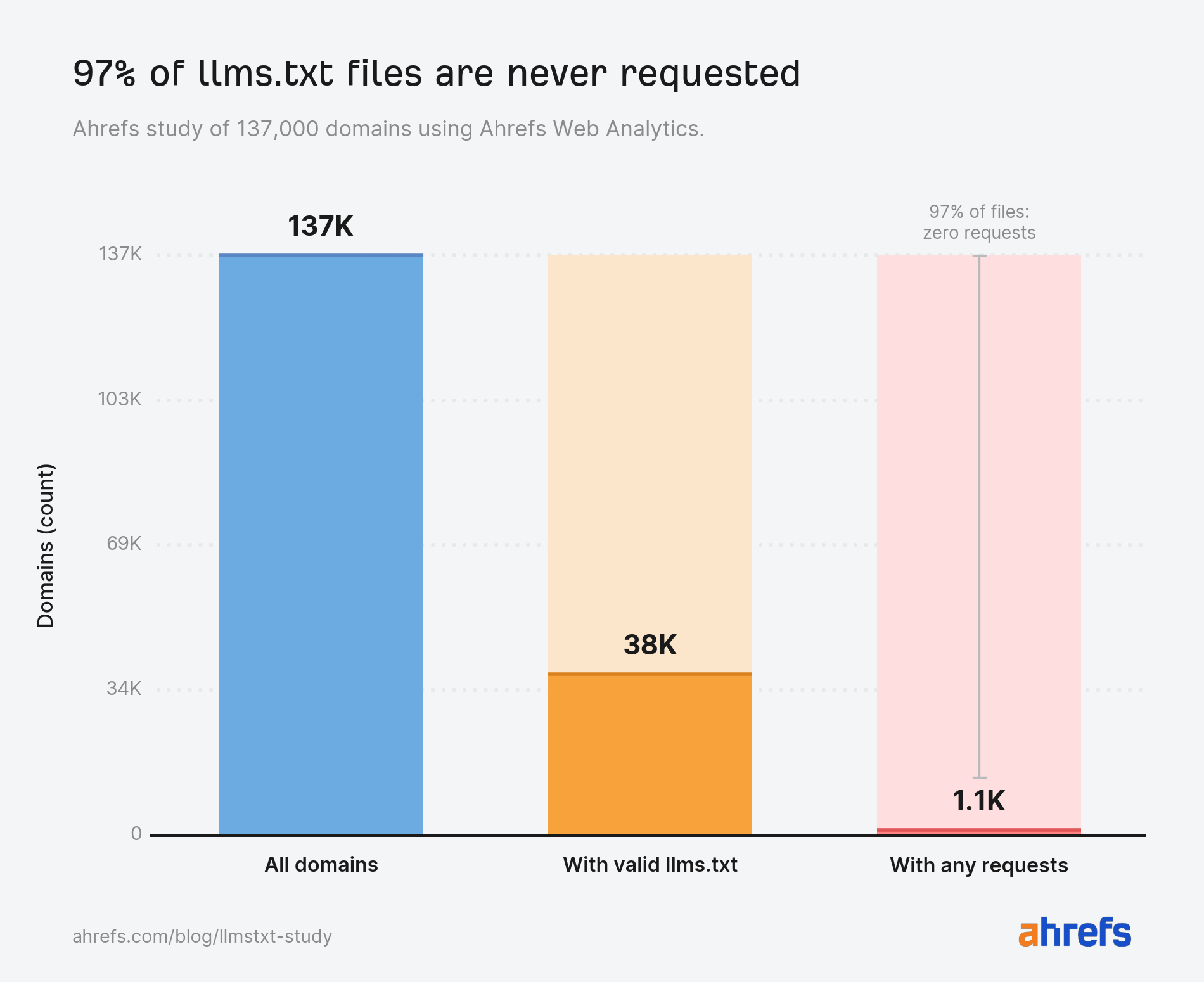
The remaining 3% (1.1K domains) obtained all the llms.txt visitors we measured.
Our information suggests John Mueller is correct. Not solely will you discover little or no AI visitors on account of this file—you’ll find little or no visitors, interval.
If you happen to publish an llms.txt file immediately, the most definitely end result by far is that nothing ever fetches it.
The three% of recordsdata that do get learn, although, get learn by fascinating guests.
We’ll concentrate on them for the remainder of the examine.
Llms.txt recordsdata are written for machines, and machines are almost the one issues studying them.
Throughout the recordsdata that obtained visitors, 96% of requests got here from bots.
People accounted for 4%, and a bit of these look like SEOs sharing llms.txt hyperlinks in chat apps, the place unfurl bots dutifully fetch them.
Slackbot alone fetched llms.txt recordsdata extra typically than PerplexityBot did.
Perplexity is among the AI serps llms.txt was seemingly designed to assist, so discovering {that a} chat app’s link-preview bot outfetched it speaks volumes about how a lot actual AI search curiosity these recordsdata are literally producing.
Many websites publish llms.txt exactly as a result of they suppose it is going to enhance their probabilities of showing in ChatGPT solutions, or touchdown Perplexity citations, or profitable an AI Overview.
However our information tells a special story: 77% of the bots fetching llms.txt aren’t AI instruments at all.
To grasp which bots had been requesting llms.txt, we categorized each person agent into twelve classes.
| CATEGORY | TYPE | REQUESTS | % OF TOTAL |
|---|---|---|---|
| Search engine optimization audit instrumentsCrawl websites for conventional Search engine optimization well being checks, with no particular curiosity in llms.txte.g. SiteAuditBot, WebPageTest | Auditing | 4,776 | 21.7% |
| Different and unidentifiedNameless SDK defaults and bots whose function or operator we couldn’t decidee.g. node, satoric-indexer | Unknown | 3,278 | 14.9% |
| Normal net crawlersIndex the online for search and product discovery, with no said AI-agent use casee.g. Googlebot, Amazonbot | Crawling | 2,871 | 13.1% |
| Tech profiling instrumentsCrawl websites to determine expertise stacks and enterprise intelligence informatione.g. BuiltWith, Dataprovider | Profiling | 2,546 | 11.6% |
| AI brokers & agentic infrastructureAI brokers appearing on a person’s behalf, plus the crawlers and tooling constructed to serve theme.g. Claude-Code, IbouBot | AI | 2,302 | 10.5% |
| GEO/AEO instrumentsScan web sites and rating their readiness for AI search and agent discoverye.g. CairrotReadinessBot, AuditMetricBot | 1,278 | 5.8% | |
| AI coaching crawlersAccumulate information for mannequin constructinge.g. GPTBot, ClaudeBot | AI | 1,179 | 5.3% |
| llms.txt discoverability botsParticularly scan, validate, or catalogue llms.txt recordsdatae.g. LLMS-Txt-Scanner, txtfeed-bot | 793 | 3.6% | |
| Service and social botsFetch URLs to generate hyperlink previews in messaging apps and social platformse.g. Slackbot, Skype URI Preview | Social | 645 | 2.9% |
| Analysis botsCrawl for tutorial or investigative functions, together with safety analysise.g. prompt-injection-survey, ResearchProject | 585 | 2.7% | |
| AI assistantsBrowse the online on behalf of a person in response to a single questione.g. ChatGPT-Person, Claude-Person | AI | 559 | 2.5% |
| AI retrieval botsFetch pages to reply dwell person queries in AI search merchandisee.g. OAI-SearchBot, PerplexityBot | AI | 233 | 1.1% |
Individually, no AI bot class makes the highest 4.
Search engine optimization audit instruments (21.7%), Different and unidentified (14.9%), Normal net crawlers (13.1%), and Tech profiling instruments (11.6%) all ship extra requests than anybody AI bot.
Sidenote.
That prime class additionally incorporates Chrome’s Lighthouse audit, the examine that reignited the llms.txt debate. It made simply 22 requests—roughly 1 in 1,000.
The largest standalone AI class, AI brokers, sits in fifth place at 10.5%.
However while you mix the 4 AI classes (coaching crawlers, retrieval bots, assistants, and brokers), AI bots develop into the biggest single bucket at 19.5%.
The bot visitors splits into three tales:
- AI bots consuming the file (19.5%)
- An extended tail of nameless scrapers (14.9%)
- An business auditing it (12.1%)
We’ll dig into a few these under.
Of the requests that do attain llms.txt recordsdata, named AI bots account for 19.5%.
Whereas AI bots are the biggest identifiable readership of llms.txt, the breakdown by AI bot kind exhibits the file isn’t serving the AI instruments most individuals have in thoughts.
We group them 4 methods:
- AI brokers & agentic infrastructure that act on a person’s behalf, or crawl to serve the brokers that do.
- AI coaching crawlers that acquire information for mannequin constructing
- AI assistants that browse the online on behalf of a person in actual time
- AI retrieval bots that fetch pages to reply dwell person queries in AI platforms
Right here’s how they measurement up…
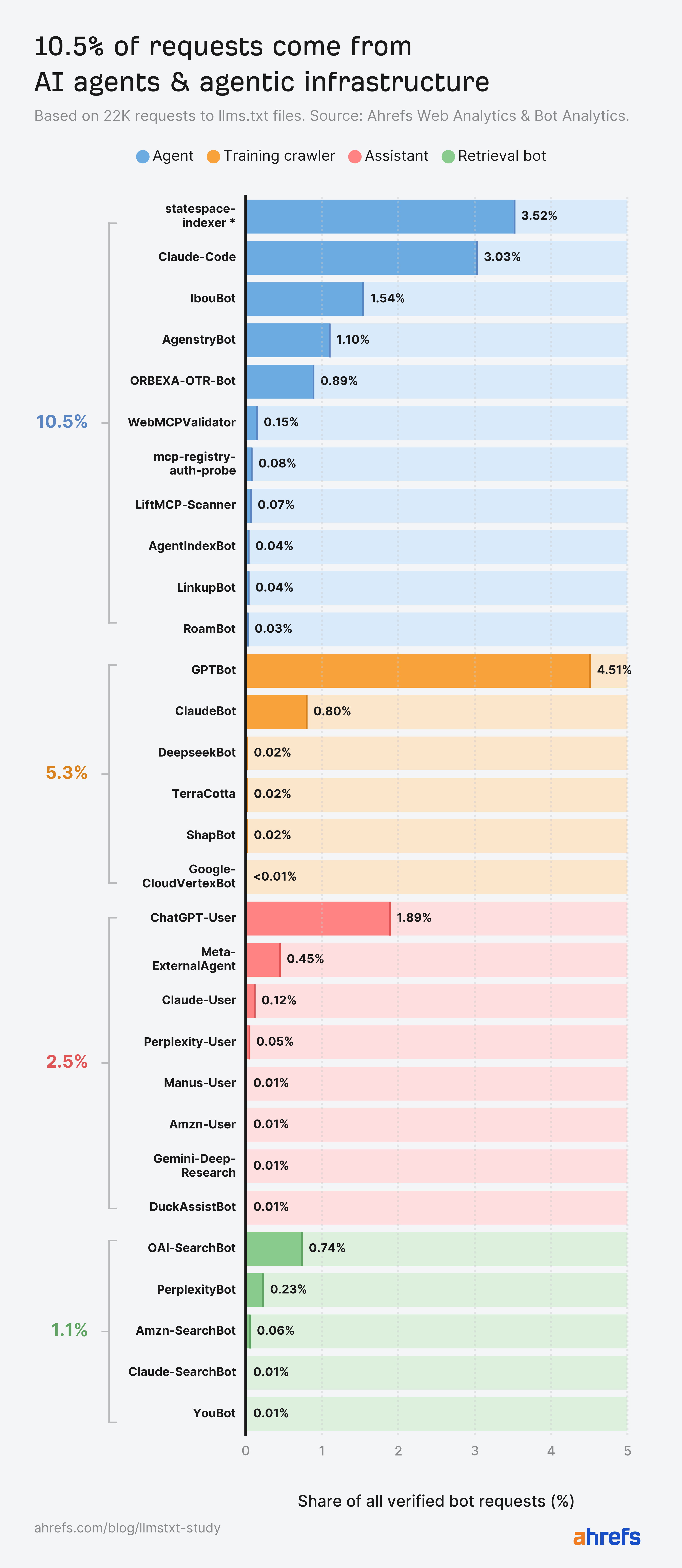
*statespace-indexer: operator recognized as Statespace (agentic infrastructure), IP ranges unconfirmed.
Sidenote.
Fast reminder: This evaluation covers the three% of recordsdata that obtained any requests in any respect, to not the overall 137K domains. That equates to roughly 1.1K domains and 22K requests in complete—so we’re nonetheless solely learning a tiny pool. Additionally, “fetched” doesn’t imply “learn”. Many bots might have fetched the llms.txt file with out ever appearing on what’s inside. Each determine on this examine is due to this fact a ceiling on precise llms.txt consumption. As an illustration, 19.5% of requests from AI is probably the most beneficiant doable studying. Precise AI consumption is someplace at or under this.
The agentic net is the actual shopper, sending 10.5% of requests
AI brokers, and the infrastructure constructed to serve them, drive 10.5% of llms.txt requests—greater than another kind of AI bot.
This discovering strains up with a hunch that many within the business already had.
We heard earlier from John Mueller that llms.txt works greatest as reference materials for AI coding brokers.
Chris Lengthy, Founding father of Nectiv, has additionally said that, even when llms.txt doesn’t make it easier to in Google search, the file has utility in case your clients “are utilizing Claude Code to supply suggestions”
Our Bot Analytics information helps each concepts.
We see llms.txt recordsdata being fetched far much less by the search and AI bots which can be seemingly chargeable for visibility, and much more by the agentic instruments that hunt down structured data and/or act on a person’s behalf.
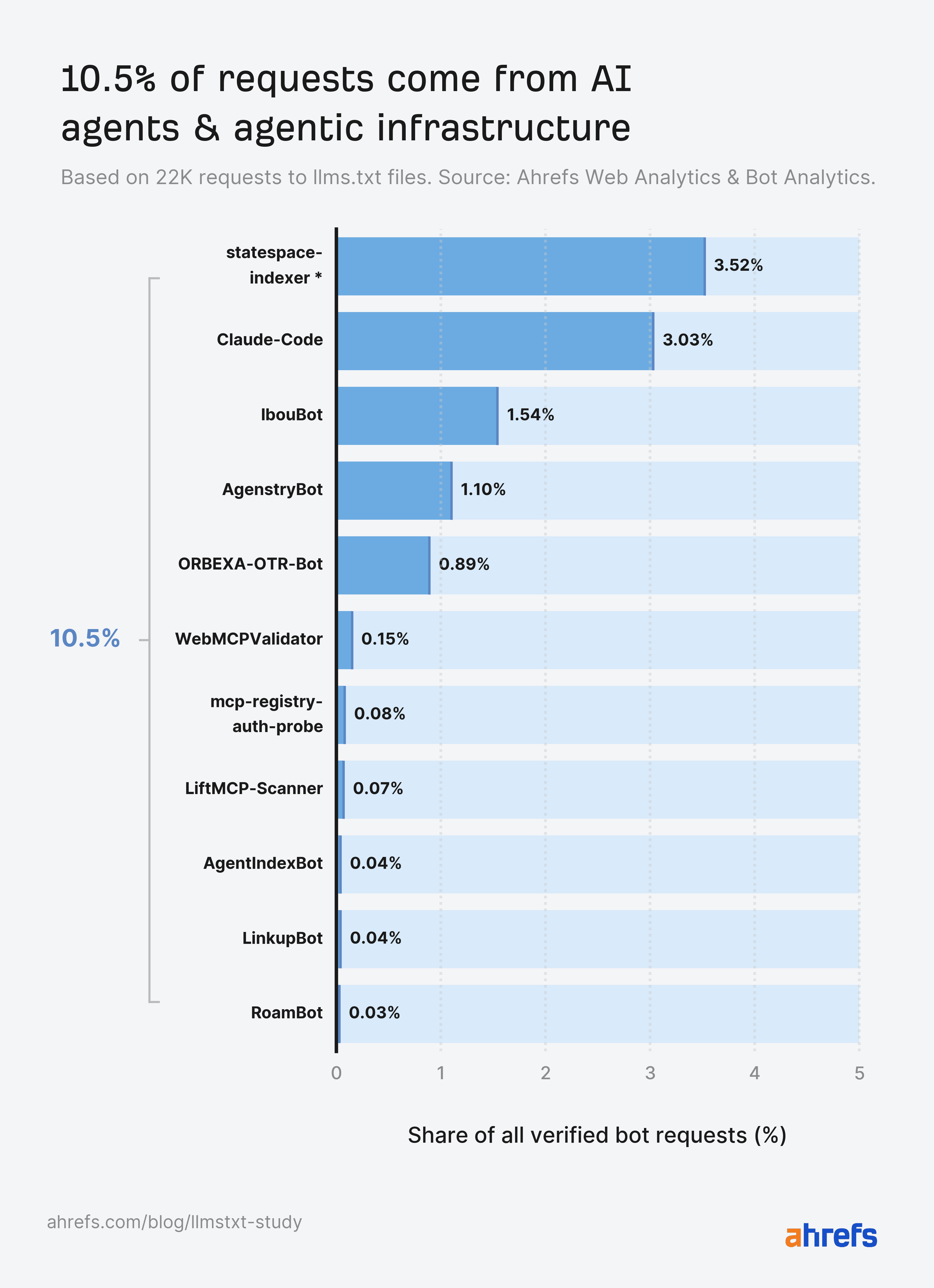
*statespace-indexer: operator recognized as Statespace (agentic infrastructure), IP ranges unconfirmed.
Except for statespace-indexer and GPTBot, Claude-Code (Anthropic’s coding agent), out-fetched each AI retrieval bot, each AI assistant, and each AI coaching crawler.
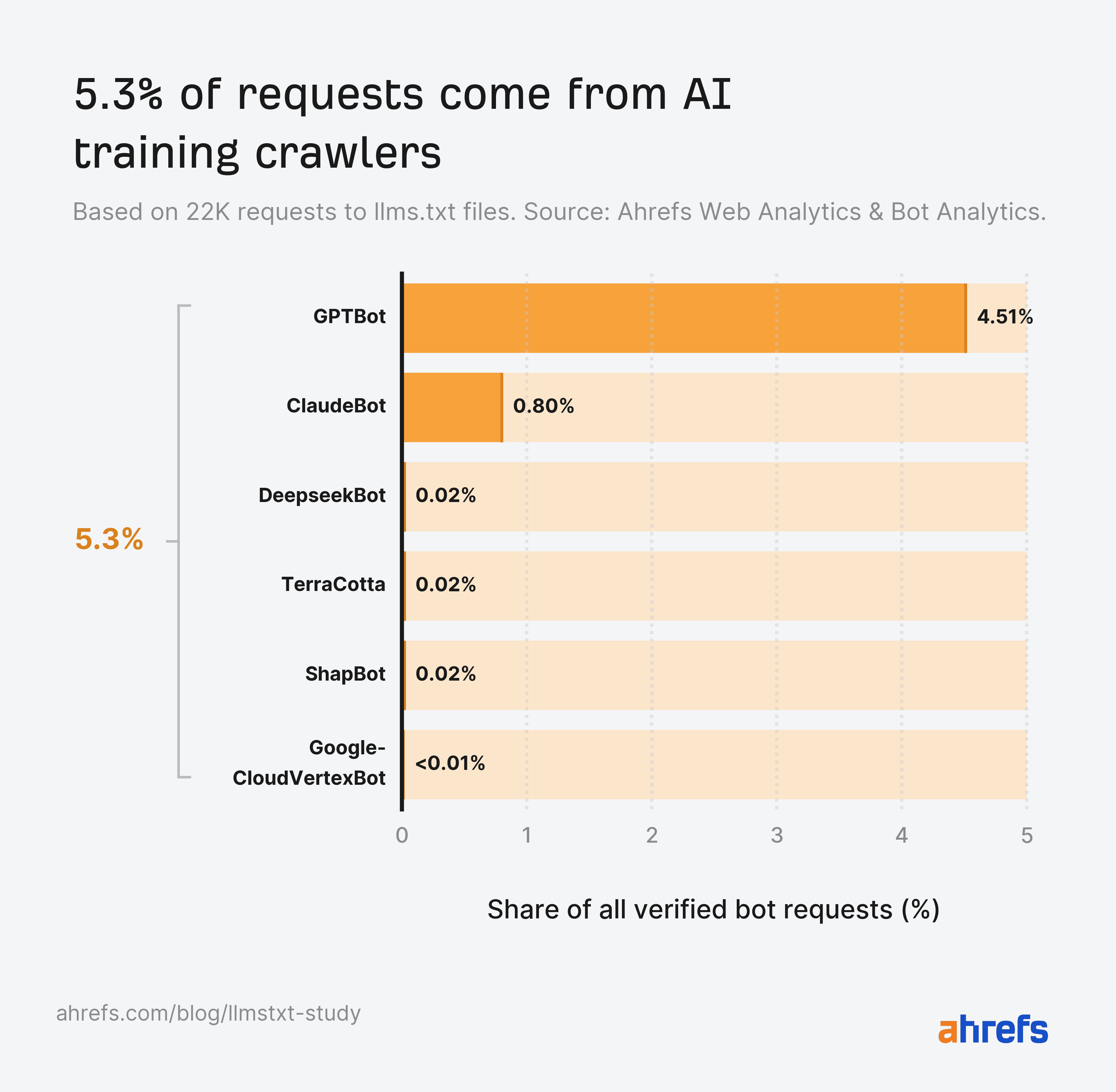
Coaching crawlers are the second-largest AI class at 5.3%
Llms.txt recordsdata feed coaching corpora greater than they feed AI search retrieval.
In reality, AI coaching crawlers fetch llms.txt almost 5X greater than AI retrieval bots.
So if llms.txt had been to in any means affect your model’s AI visibility, it could probably be upstream—not on the level of retrieval.
Of all coaching crawlers, GPTBot is way and away the most important fetcher of llms.txt.
You received’t discover a Gemini crawler on this checklist, as a result of it doesn’t exist.
Google trains and grounds Gemini on content material fetched by common Googlebot, and Google-Prolonged, the opt-out publishers use, is a robots.txt token slightly than a crawler with its personal person agent.
Googlebot did fetch llms.txt recordsdata ~900 instances in Might, however Googlebot routinely fetches any URL it discovers on a web site as a part of regular search indexing, so these fetches don’t point out particular curiosity in llms.txt—it’s crawling the file the identical means it crawls a sitemap or another web page.
Whether or not any of that content material then feeds Gemini is invisible to us.
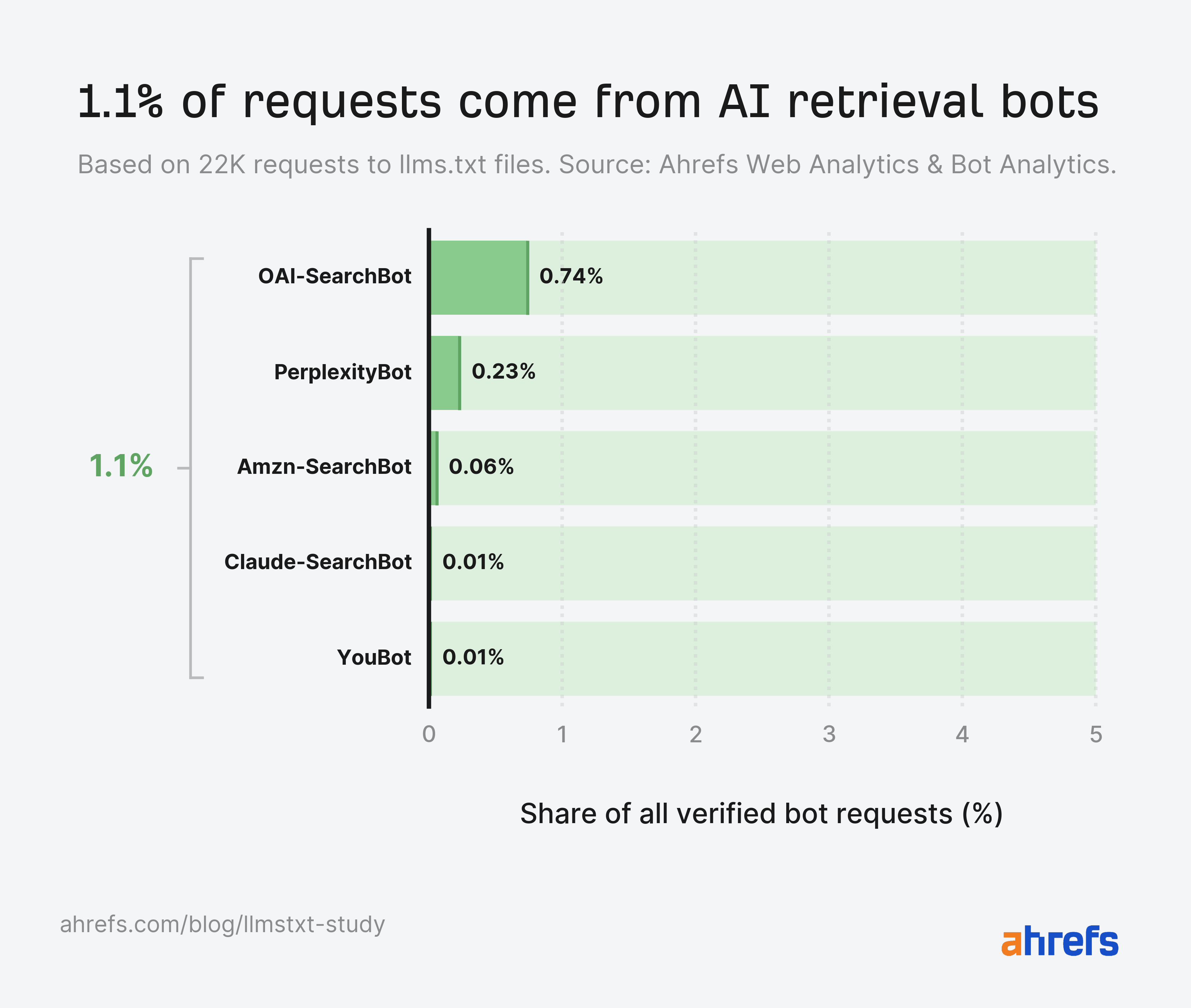
AI retrieval bots barely register, with 1.1% of complete requests
In accordance with our information, AI retrieval bots account for simply 1.1% of AI bot requests.
Even when taken along with AI assistants and AI coaching crawlers, these bots nonetheless depend for under 8.9% of requests (1.6% lower than AI brokers).
OAI-SearchBot, PerplexityBot, and Claude’s search crawler mixed made solely a few hundred fetches throughout hundreds of websites.
In case you are planning on producing an llms.txt in hopes of boosting your AI citations, chances are you’ll need to suppose once more.
A complete ecosystem has fashioned round auditing, scoring, validating, and learning the llms.txt normal, earlier than we’ve even established whether or not any main AI platform really reads it.
Three classes account for 12% of all requests mixed.
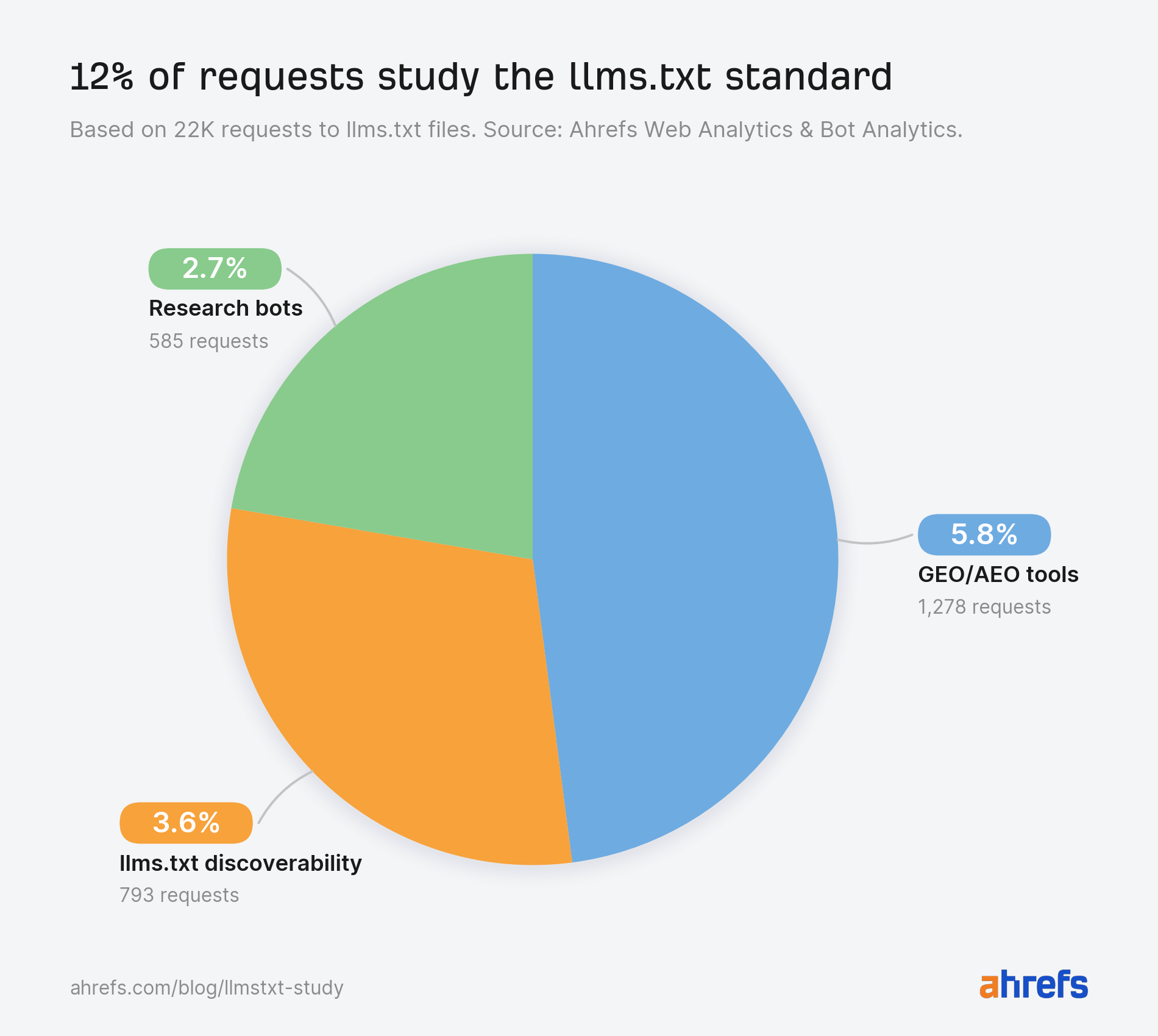
GEO/AEO instruments ship 5.8% of requests
Industrial instruments scan web sites and rating their readiness for AI search and agent discovery, with llms.txt presence as one in every of many alerts.
Essentially the most lively, CairrotReadinessBot, belongs to Cairrot, a WordPress-focused AEO platform launched in late 2025.
Then you might have the mainstream web site builders like Framer, Lovable, and Wix all baking AI-readiness checks into their merchandise.
Lms.txt adoption has develop into a platform default earlier than it’s even develop into a webmaster resolution.
llms.txt discoverability bots cowl 3.6% of requests
There’s an ecosystem of instruments that catalog the llms.txt recordsdata that just about no one else reads.
Devoted scanners, validators, and directories constructed solely for llms.txt recordsdata ship extra requests than AI retrieval bots and AI assistants.
Analysis bots ship 2.7% of requests
The biggest single analysis crawler within the dataset identifies itself as prompt-injection-survey/1.0.
Somebody is systematically learning llms.txt as a immediate injection alternative that AI brokers are designed to ingest and belief.
The safety implications of brokers trusting llms.txt recordsdata at scale have barely been mentioned, and but potential unhealthy actors are already on the case.
AI instruments by no means go in search of llms.txt recordsdata that aren’t there, so publishing one doesn’t put you on any AI radar.
We analyzed each request to /llms.txt paths that returned a 404 and located the cleanest cut up we’ve seen in bot information: the place on the one hand legitimate recordsdata drew 96% bot visitors, lacking recordsdata drew 98% human visitors, and the AI bot share of these 404s was zero.
The folks probing for absent llms.txt recordsdata are people typing the URL right into a browser, presumably SEOs checking on rivals.
This kills the idea that AI techniques actively hunt for llms.txt recordsdata, and {that a} web site with out one is lacking a knock on the door.
AI instruments fetch llms.txt when a hyperlink, an index, or a person instruction tells them it exists.
Easy methods to examine your personal llms.txt bot visitors
If you wish to see which bots are literally hitting your llms.txt file, head to Ahrefs Bot Analytics and add a filter for Web page URL → Accommodates → llms.txt, then hit Apply.
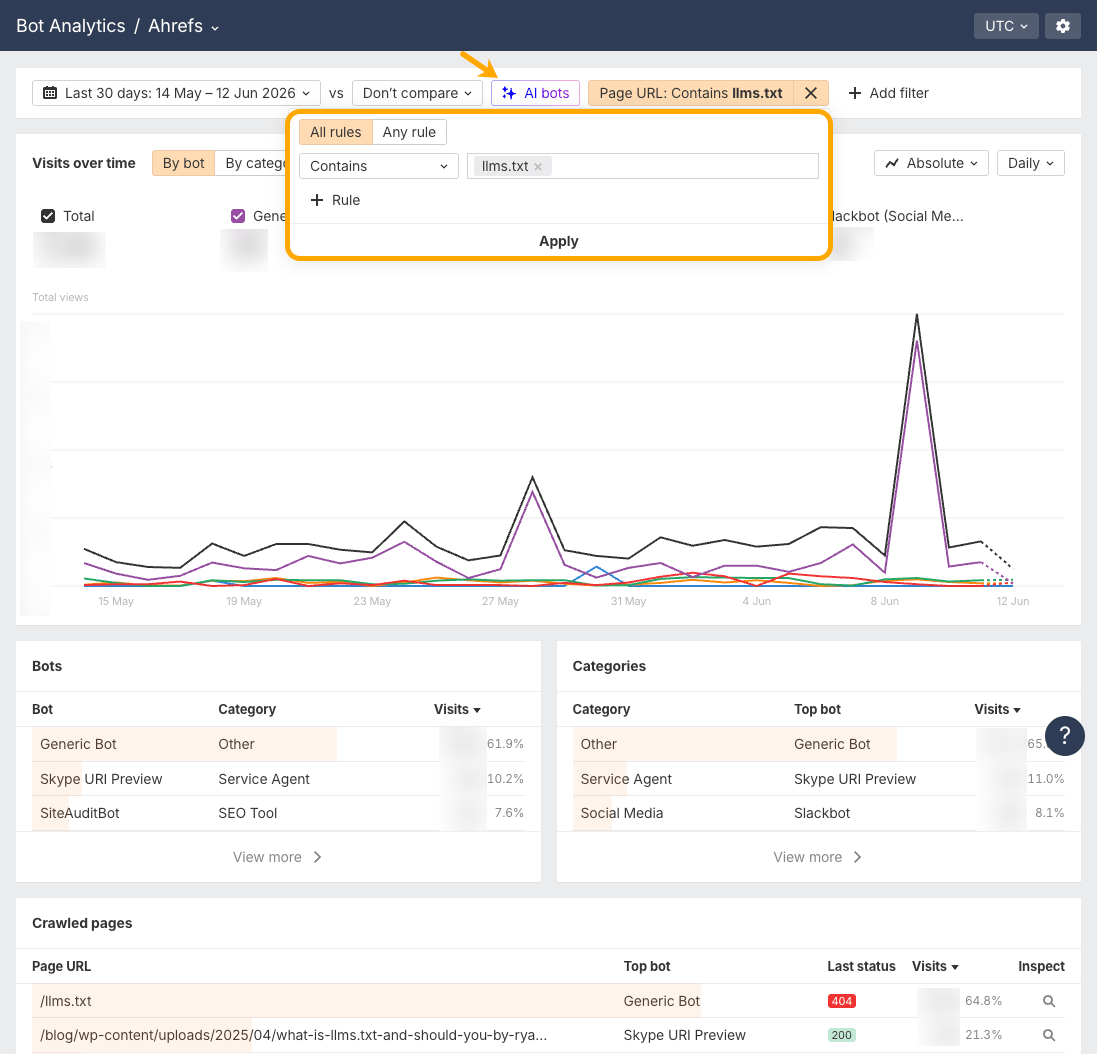
This narrows all the things right down to requests hitting your llms.txt file (or any pages with “llms.txt” within the URL, like weblog posts about it).
We don’t have an llms.txt file on the Ahrefs web site however we’re getting some bots hitting that web page, as indicated by the 404 standing.
From there, you possibly can examine:
- Visits over time. Toggle between By bot and By class to see whether or not visitors is climbing, flat, or spiking.
- The Bots desk. See which precise bots are fetching the file.
- Final standing in Crawled pages. Test the standing code. A
404on/llms.txtmeans bots are asking for a file that isn’t there.
That final level is the helpful gut-check. Loads of websites get bot requests for an llms.txt they by no means printed. The visitors is actual; the file isn’t.
You can too use the AI bots filter at prime of the web page to strip out different crawlers and see solely the LLM-related ones.
And, keep in mind, a bot requesting your llms.txt isn’t proof something learn or acted on it. It solely tells you the file was fetched.
In case your objective is exhibiting up in ChatGPT, Perplexity, or AI Overviews, an llms.txt file is basically ornament.
AI search bots barely fetch them, no AI system goes in search of them, and 97% of present recordsdata entice no readers of any variety.
And do not forget that requests are the beneficiant measure. Whether or not bots act on what they fetch is one other query
Listed here are the professionals and cons, side-by-side.
| PROS | CONS |
|---|---|
| Publishing llms.txt is affordable, and platforms like Wix will more and more do it for you. | The bottom charge is brutal: 97% of present llms.txt recordsdata entice no readers of any variety. |
| The closest factor to an meant viewers in our information is coding brokers. In case your clients use coding brokers, or if brokers act in your web site, the file stands an actual probability of being learn. | It received’t assist your AI search visibility immediately. AI retrieval bots barely fetch these recordsdata, and no AI system goes in search of one you haven’t printed. |
| It might futureproof your technique. Google has made it clear that the way forward for search is agentic. If brokers find yourself mediating AI search, slightly than retrieval bots fetching pages instantly, llms.txt may begin influencing AI visibility via the agent layer. | Publishing is simply half the job. Brokers fetch llms.txt when directed, not speculatively, so an unlinked file is unlikely to get picked up. |
| It’s a safety threat. Brokers are constructed to belief this file, and potential unhealthy actors are already probing llms.txt for immediate injection. A stale or compromised file misleads each agent that reads it. |
My verdict: the cons outweigh the professionals proper now. If you wish to present up in AI search, there are extra dependable methods to enhance your visibility than this file.
However if you happen to’re nonetheless toying with the concept of producing llms.txt, listed here are the steps it is best to take:
- Test your personal logs earlier than investing additional. A 97% probability of zero readership is the bottom charge.
- Get a website-building platform to do it for you. Wix already generates these recordsdata, and Framer and Lovable are scanning for them. Inside a 12 months, having an llms.txt could also be as a lot a CMS default as having a sitemap. If the payoff is unsure, it is smart to maintain the hassle minimal.
- Route brokers to it. Hyperlink the file out of your HTML, reference it in your docs, or point out it anyplace brokers obtain directions about your web site. Brokers fetch llms.txt when directed, not speculatively.
- Offset the immediate injection threat by treating llms.txt like code. Model-control it, limit who can edit it, set an alert for unauthorized modifications, preserve the content material to plain hyperlinks and descriptions (nothing instruction-shaped), solely hyperlink to sources you management, and evaluate something a platform auto-generates in your behalf.
This examine solutions what number of websites publish llms.txt, and who reads it.
However there are a few different questions worthy of additional analysis that had been past the scope of this examine:
- Do brokers fetch developer-docs extra typically? Is Claude-Code’s llms.txt curiosity targeting documentation paths like /docs/ and /api/, as Mueller’s framing predicts?
- Do bots really act on what they learn? When an AI agent fetches llms.txt, does it then fetch the sources the file hyperlinks to? Search engine optimization guide David McSweeney, Founding father of Queryburst, is already working an experiment alongside these strains: he’s serving AI person brokers a compressed, agent-friendly abstract of his take a look at websites, full with directions for requesting deeper content material, and monitoring whether or not any agent really follows via. His outcomes are price following.
Mueller referred to as llms.txt a short lived crutch.
However that crutch appears to have already got its personal provide chain: platforms producing llms.txt recordsdata, an business auditing them, and safety researchers learning them, all earlier than the “readers” really confirmed up.
Both we’re watching the early scaffolding of an actual normal, or we’re watching the Search engine optimization business show it will probably productize something. Our cash is on a little bit of each.










{kind=link}