
What Is ProRLv2?
ProRLv2 is the newest model of NVIDIA’s Extended Reinforcement Studying (ProRL), designed particularly to push the boundaries of reasoning in massive language fashions (LLMs). By scaling reinforcement studying (RL) steps from 2,000 as much as 3,000, ProRLv2 systematically checks how prolonged RL can unlock new answer areas, creativity, and high-level reasoning that had been beforehand inaccessible—even with smaller fashions just like the 1.5B-parameter Nemotron-Analysis-Reasoning-Qwen-1.5B-v2.
Key Improvements in ProRLv2
ProRLv2 incorporates a number of improvements to beat frequent RL limitations in LLM coaching:
- REINFORCE++- Baseline: A sturdy RL algorithm that permits long-horizon optimization over 1000’s of steps, dealing with the instability typical in RL for LLMs.
- KL Divergence Regularization & Reference Coverage Reset: Periodically refreshes the reference mannequin with the present finest checkpoint, permitting secure progress and continued exploration by stopping the RL goal from dominating too early.
- Decoupled Clipping & Dynamic Sampling (DAPO): Encourages numerous answer discovery by boosting unlikely tokens and focusing studying alerts on prompts of intermediate problem.
- Scheduled Size Penalty: Cyclically utilized, serving to preserve range and stop entropy collapse as coaching lengthens.
- Scaling Coaching Steps: ProRLv2 strikes the RL coaching horizon from 2,000 to three,000 steps, instantly testing how for much longer RL can develop reasoning skills.
How ProRLv2 Expands LLM Reasoning
Nemotron-Analysis-Reasoning-Qwen-1.5B-v2, skilled with ProRLv2 for 3,000 RL steps, units a brand new commonplace for open-weight 1.5B fashions on reasoning duties, together with math, code, science, and logic puzzles:
- Efficiency surpasses earlier variations and rivals like DeepSeek-R1-1.5B.
- Sustained positive factors with extra RL steps: Longer coaching results in continuous enhancements, particularly on duties the place base fashions carry out poorly, demonstrating real growth in reasoning boundaries.
- Generalization: Not solely does ProRLv2 increase move@1 accuracy, nevertheless it additionally permits novel reasoning and answer methods on duties not seen throughout coaching.
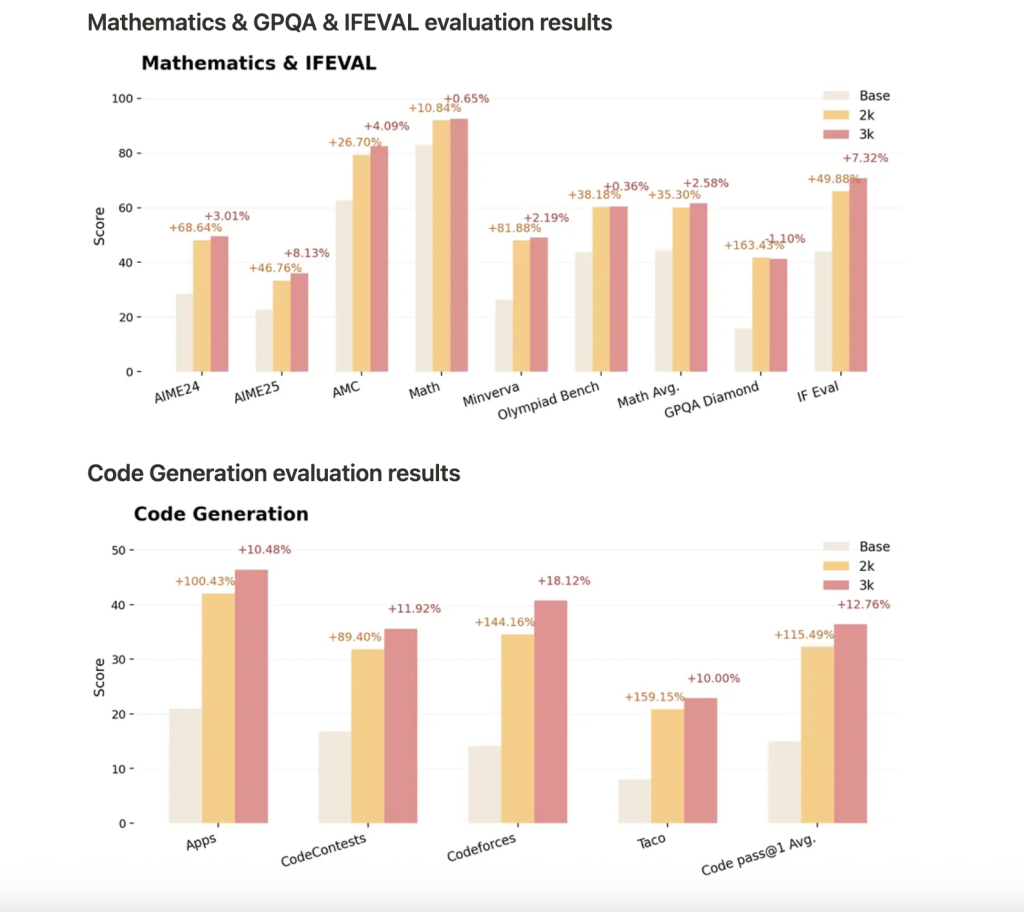
- Benchmarks: Positive aspects embody common move@1 enhancements of 14.7% in math, 13.9% in coding, 54.8% in logic puzzles, 25.1% in STEM reasoning, and 18.1% in instruction-following duties, with additional enhancements in v2 on unseen and more durable benchmarks.
Why It Issues
The main discovering of ProRLv2 is that continued RL coaching, with cautious exploration and regularization, reliably expands what LLMs can be taught and generalize. Somewhat than hitting an early plateau or overfitting, extended RL permits smaller fashions to rival a lot bigger ones in reasoning—demonstrating that scaling RL itself is as essential as mannequin or dataset dimension.
Utilizing Nemotron-Analysis-Reasoning-Qwen-1.5B-v2
The most recent checkpoint is offered for testing on Hugging Face. Loading the mannequin:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("nvidia/Nemotron-Analysis-Reasoning-Qwen-1.5B")
mannequin = AutoModelForCausalLM.from_pretrained("nvidia/Nemotron-Analysis-Reasoning-Qwen-1.5B")
Conclusion
ProRLv2 redefines the boundaries of reasoning in language fashions by exhibiting that RL scaling legal guidelines matter as a lot as dimension or knowledge. By superior regularization and good coaching schedules, it permits deep, artistic, and generalizable reasoning even in compact architectures. The long run lies in how far RL can push—not simply how large fashions can get.
Take a look at the Unofficial Weblog and Mannequin on Hugging Face right here. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Publication.
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.






![How creators and entrepreneurs are utilizing AI to hurry up & succeed [data]](https://blog.aimactgrow.com/wp-content/uploads/2025/06/Untitled20design-Apr-07-2023-08-24-35-4586-PM-120x86.png)




{kind=link}