Anthropic launched Claude Sonnet 4.5 and units a brand new benchmark for end-to-end software program engineering and real-world pc use. The replace additionally ships concrete product floor adjustments (Claude Code checkpoints, a local VS Code extension, API reminiscence/context instruments) and an Agent SDK that exposes the identical scaffolding Anthropic makes use of internally. Pricing stays unchanged from Sonnet 4 ($3 enter / $15 output per million tokens).
What’s truly new?
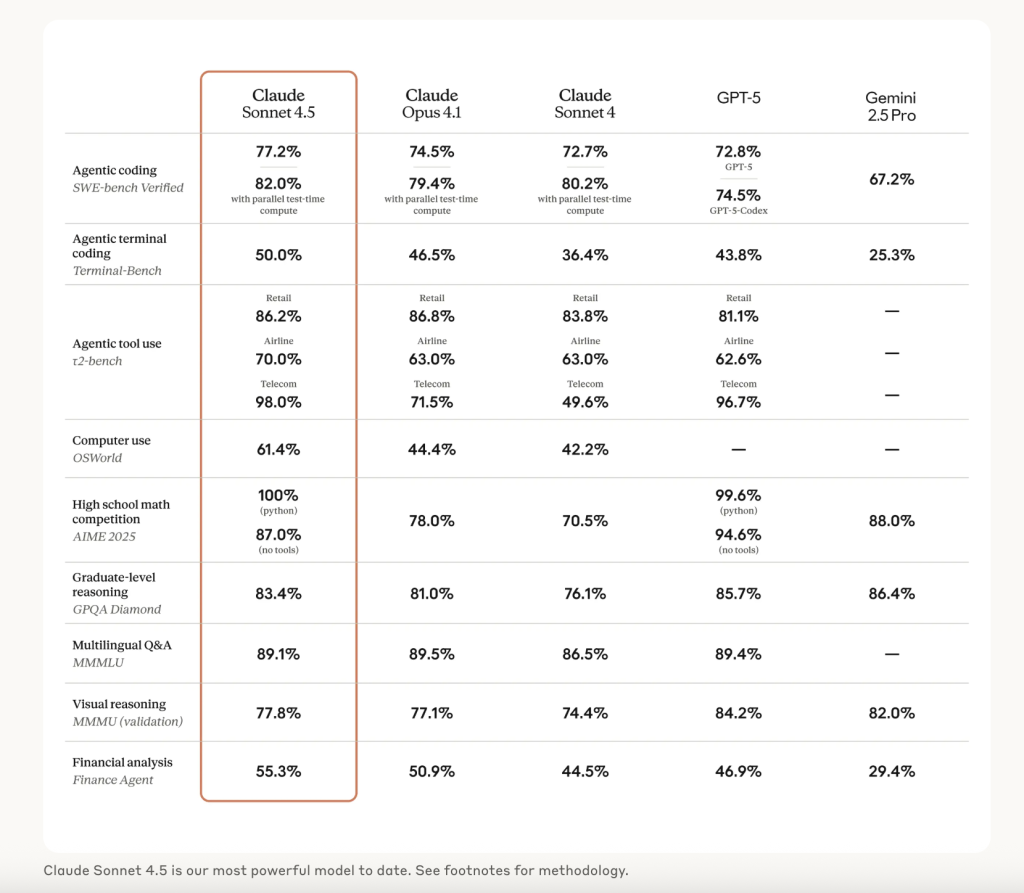
- SWE-bench Verified document. Anthropic experiences 77.2% accuracy on the 500-problem SWE-bench Verified dataset utilizing a easy two-tool scaffold (bash + file edit), averaged over 10 runs, no test-time compute, 200K “pondering” funds. A 1M-context setting reaches 78.2%, and a higher-compute setting with parallel sampling and rejection raises this to 82.0%.
- Laptop-use SOTA. On OSWorld-Verified, Sonnet 4.5 leads at 61.4%, up from Sonnet 4’s 42.2%, reflecting stronger software management and UI manipulation for browser/desktop duties.
- Lengthy-horizon autonomy. The group noticed >30 hours of uninterrupted deal with multi-step coding duties — a sensible leap over earlier limits and immediately related to agent reliability.
- Reasoning/math. The discharge notes “substantial positive factors” throughout widespread reasoning and math evals; precise per-bench numbers (e.g., AIME config). Security posture is ASL-3 with strengthened defenses in opposition to prompt-injection.
What’s there for brokers?
Sonnet 4.5 targets the brittle components of actual brokers: prolonged planning, reminiscence, and dependable software orchestration. Anthropic’s Claude Agent SDK exposes their manufacturing patterns (reminiscence administration for long-running duties, permissioning, sub-agent coordination) reasonably than only a naked LLM endpoint. Which means groups can reproduce the identical scaffolding utilized by Claude Code (now with checkpoints, a refreshed terminal, and VS Code integration) to maintain multi-hour jobs coherent and reversible.
On measured duties that simulate “utilizing a pc,” the 19-point leap on OSWorld-Verified is notable; it tracks with the mannequin’s skill to navigate, fill spreadsheets, and full internet flows in Anthropic’s browser demo. For enterprises experimenting with agentic RPA-style work, larger OSWorld scores normally correlate with decrease intervention charges throughout execution.
The place you may run it?
- Anthropic API & apps. Mannequin ID
claude-sonnet-4-5; value parity with Sonnet 4. File creation and code execution at the moment are out there immediately in Claude apps for paid tiers. - AWS Bedrock. Obtainable by way of Bedrock with integration paths to AgentCore; AWS highlights long-horizon agent periods, reminiscence/context options, and operational controls (observability, session isolation).
- Google Cloud Vertex AI. GA on Vertex AI with assist for multi-agent orchestration by way of ADK/Agent Engine, provisioned throughput, 1M-token evaluation jobs, and immediate caching.
- GitHub Copilot. Public preview rollout throughout Copilot Chat (VS Code, internet, cell) and Copilot CLI; organizations can allow by way of coverage, and BYO secret’s supported in VS Code.
Abstract
With a documented 77.2% SWE-bench Verified rating underneath clear constraints, a 61.4% OSWorld-Verified computer-use lead, and sensible updates (checkpoints, SDK, Copilot/Bedrock/Vertex availability), Claude Sonnet 4.5 is developed for long-running, tool-heavy agent workloads reasonably than brief demo prompts. Impartial replication will decide how sturdy the “finest for coding” declare is, however the design targets (autonomy, scaffolding, and pc management) are aligned with actual manufacturing ache factors at present.

Michal Sutter is an information science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and information engineering, Michal excels at remodeling complicated datasets into actionable insights.










{kind=link}