How do you exchange advanced, multilingual paperwork—dense layouts, small scripts, formulation, charts, and handwriting—into trustworthy structured Markdown/JSON with state-of-the-art accuracy whereas preserving inference latency and reminiscence low sufficient for actual deployments?Baidu’s PaddlePaddle group has launched PaddleOCR-VL, a 0.9B-parameter vision-language mannequin designed for end-to-end doc parsing throughout textual content, tables, formulation, charts, and handwriting. The core mannequin combines a NaViT-style (Native-resolution ViT) dynamic-resolution imaginative and prescient encoder with the ERNIE-4.5-0.3B decoder. It helps 109 languages.
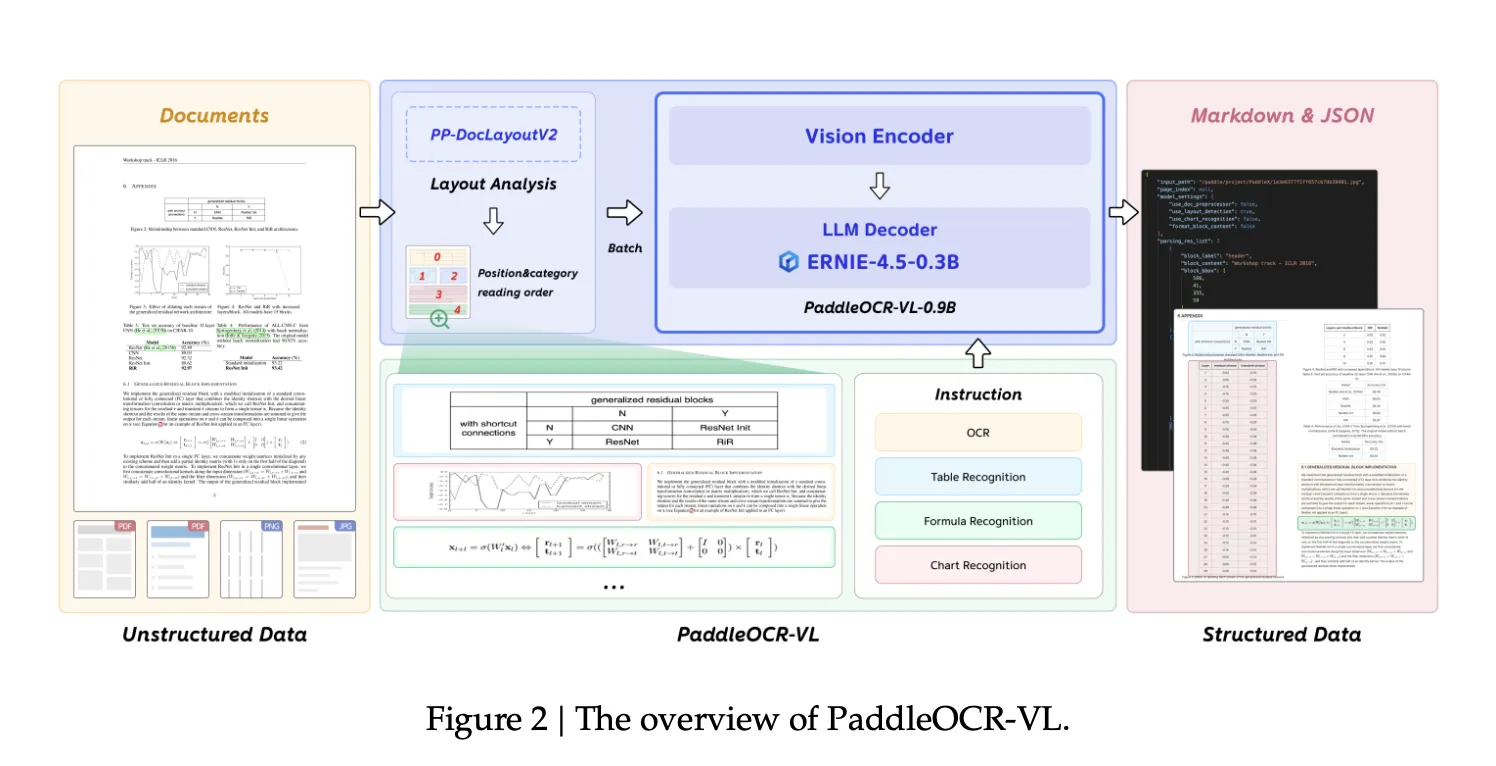
Understanding the system design
PaddleOCR-VL is deployed as a two-stage pipeline. Stage one (PP-DocLayoutV2) performs page-level format evaluation: an RT-DETR detector localizes and classifies areas; a pointer community predicts studying order. Stage two (PaddleOCR-VL-0.9B) conducts element-level recognition conditioned on the detected format. Ultimate outputs are aggregated to Markdown and JSON for downstream consumption. This decoupling mitigates long-sequence decoding latency and instability that end-to-end VLMs face on dense, multi-column, combined textual content–graphic pages.
On the mannequin degree, PaddleOCR-VL-0.9B integrates a NaViT-style dynamic high-resolution encoder (native-resolution sequence packing) with a 2-layer MLP projector and the ERNIE-4.5-0.3B language mannequin; 3D-RoPE is used for positional illustration. The technical report attributes decrease hallucinations and higher text-dense efficiency to native-resolution processing relative to fixed-resize or tiling approaches. The NaViT concept—patch-and-pack variable-resolution inputs with out harmful resizing—originates from prior work exhibiting improved effectivity and robustness; PaddleOCR-VL adopts this encoder model instantly.
Benchmarks
PaddleOCR-VL achieves state-of-the-art outcomes on OmniDocBench v1.5 and aggressive or main scores on v1.0, protecting total high quality in addition to sub-tasks (textual content edit distances, Method-CDM, Desk-TEDS/TEDS-S, and reading-order edit), with complementary energy on olmOCR-Bench and in-house handwriting, desk, formulation, and chart evaluations.
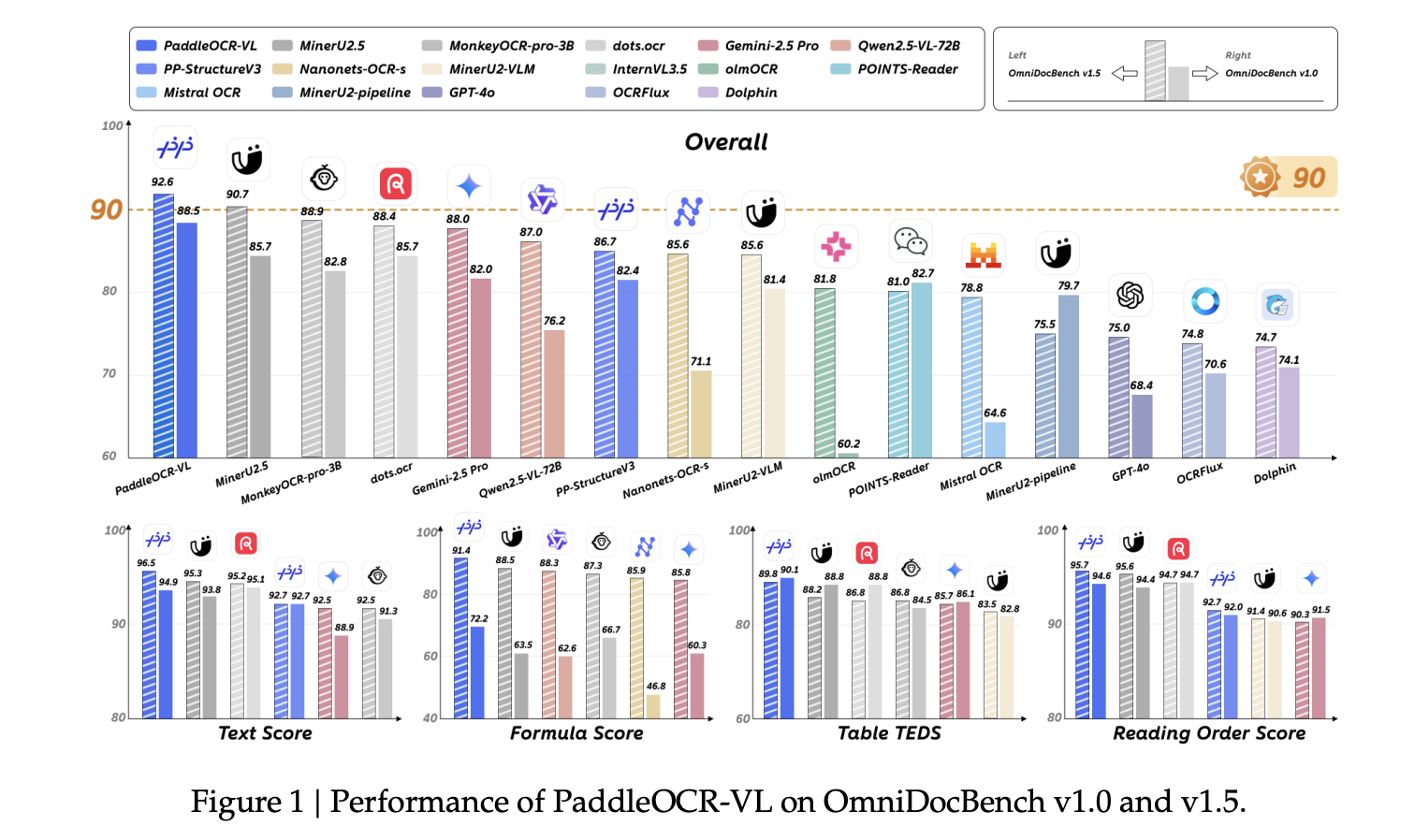
Key Takeaways
- 0.9B-parameter PaddleOCR-VL integrates a NaViT-style dynamic-resolution encoder with ERNIE-4.5-0.3B for doc parsing.
- Targets end-to-end extraction throughout textual content, tables, formulation, charts, and handwriting with structured Markdown/JSON outputs.
- Claims SOTA efficiency on public doc benchmarks with quick inference appropriate for deployment.
- Helps 109 languages, together with small scripts and sophisticated web page layouts.
This launch is significant as a result of it joins a NaViT-style dynamic-resolution visible encoder with the light-weight ERNIE-4.5-0.3B decoder to ship SOTA page-level doc parsing and element-level recognition at sensible inference value. The 2-stage PP-DocLayoutV2 → PaddleOCR-VL-0.9B design stabilizes studying order and preserves native typography cues, which matter for small scripts, formulation, charts, and handwriting throughout 109 languages. Structured Markdown/JSON outputs and elective vLLM/SGLang acceleration make the system operationally clear for manufacturing doc intelligence.
Take a look at the Technical Paper, Mannequin on HF, and Technical particulars . Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as effectively.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.











{kind=link}