How do you get GPT-5-level reasoning on actual long-context, tool-using workloads with out paying the quadratic consideration and GPU price that normally makes these programs impractical? DeepSeek analysis introduces DeepSeek-V3.2 and DeepSeek-V3.2-Speciale. They’re reasoning-first fashions constructed for brokers and targets prime quality reasoning, lengthy context and agent workflows, with open weights and manufacturing APIs. The fashions mix DeepSeek Sparse Consideration (DSA), a scaled GRPO reinforcement studying stack and an agent native device protocol, and report efficiency similar to GPT 5, with DeepSeek-V3.2-Speciale reaching Gemini 3.0 Professional degree reasoning on public benchmarks and competitions.
Sparse Consideration with Close to Linear Lengthy Context Value
Each DeepSeek-V3.2 and DeepSeek-V3.2-Speciale use the DeepSeek-V3 Combination of Specialists transformer with about 671B complete parameters and 37B energetic parameters per token, inherited from V3.1 Terminus. The one structural change is DeepSeek Sparse Consideration, launched via continued pre-training.
DeepSeek Sparse Consideration splits consideration into 2 parts. A lightning indexer runs a small variety of low precision heads over all token pairs and produces relevance scores. A fantastic grained selector retains the top-k-key worth positions per question, and the principle consideration path runs Multi-Question-Consideration and Multi-Head-Latent-Consideration on this sparse set.
This adjustments the dominant complexity from O(L²) to O(kL), the place L is sequence size and ok is the variety of chosen tokens and far smaller than L. Based mostly on the benchmarks, DeepSeek-V3.2 matches the dense Terminus baseline on accuracy whereas decreasing lengthy context inference price by about 50 %, with quicker throughput and decrease reminiscence use on H800 class {hardware} and on vLLM and SGLang backends.

Continued Pre Coaching for DeepSeek Sparse Consideration
DeepSeek Sparse Consideration (DSA) is launched by continued pre-training on high of DeepSeek-V3.2 Terminus. Within the dense heat up stage, dense consideration stays energetic, all spine parameters are frozen and solely the lightning indexer is skilled with a Kullback Leibler loss to match the dense consideration distribution on 128K context sequences. This stage makes use of a small variety of steps and about 2B tokens, sufficient for the indexer to study helpful scores.
Within the sparse stage, the selector retains 2048 key-value entries per question, the spine is unfrozen and the mannequin continues coaching on about 944B tokens. Gradients for the indexer nonetheless come solely from the alignment loss with dense consideration on the chosen positions. This schedule makes DeepSeek Sparse Consideration (DSA) behave as a drop in alternative for dense consideration with related high quality and decrease lengthy context price.

GRPO with greater than 10 P.c RL Compute
On high of the sparse structure, DeepSeek-V3.2 makes use of Group Relative Coverage Optimization (GRPO) as the principle reinforcement studying technique. The analysis staff state that publish coaching reinforcement studying RL compute exceeds 10 % of pre coaching compute.
RL is organized round specialist domains. The analysis staff trains devoted runs for arithmetic, aggressive programming, normal logical reasoning, looking and agent duties and security, then distills these specialists into the shared 685B parameter base for DeepSeek-V3.2 and DeepSeek-V3.2-Speciale. GRPO is applied with an unbiased KL estimator, off coverage sequence masking and mechanisms that hold Combination of Specialists (MoE) routing and sampling masks constant between coaching and sampling.

Agent Knowledge, Considering Mode and Software Protocol
DeepSeek analysis staff builds a big artificial agent dataset by producing greater than 1,800 environments and greater than 85,000 duties throughout code brokers, search brokers, normal instruments and code interpreter setups. Duties are constructed to be arduous to resolve and simple to confirm, and are used as RL targets along with actual coding and search traces.
At inference time, DeepSeek-V3.2 introduces express considering and non considering modes. The deepseek-reasoner endpoint exposes considering mode by default, the place the mannequin produces an inside chain of thought earlier than the ultimate reply. The considering with instruments information describes how reasoning content material is saved throughout device calls and cleared when a brand new consumer message arrives, and the way device calls and power outcomes keep within the context even when reasoning textual content is trimmed for funds.
The chat template is up to date round this conduct. The DeepSeek-V3.2 Speciale repository ships Python encoder and decoder helpers as a substitute of a Jinja template. Messages can carry a reasoning_content subject alongside content material, managed by a considering parameter. A developer position is reserved for search brokers and isn’t accepted normally chat flows by the official API, which protects this channel from unintentional misuse.

Benchmarks, Competitions And Open Artifacts
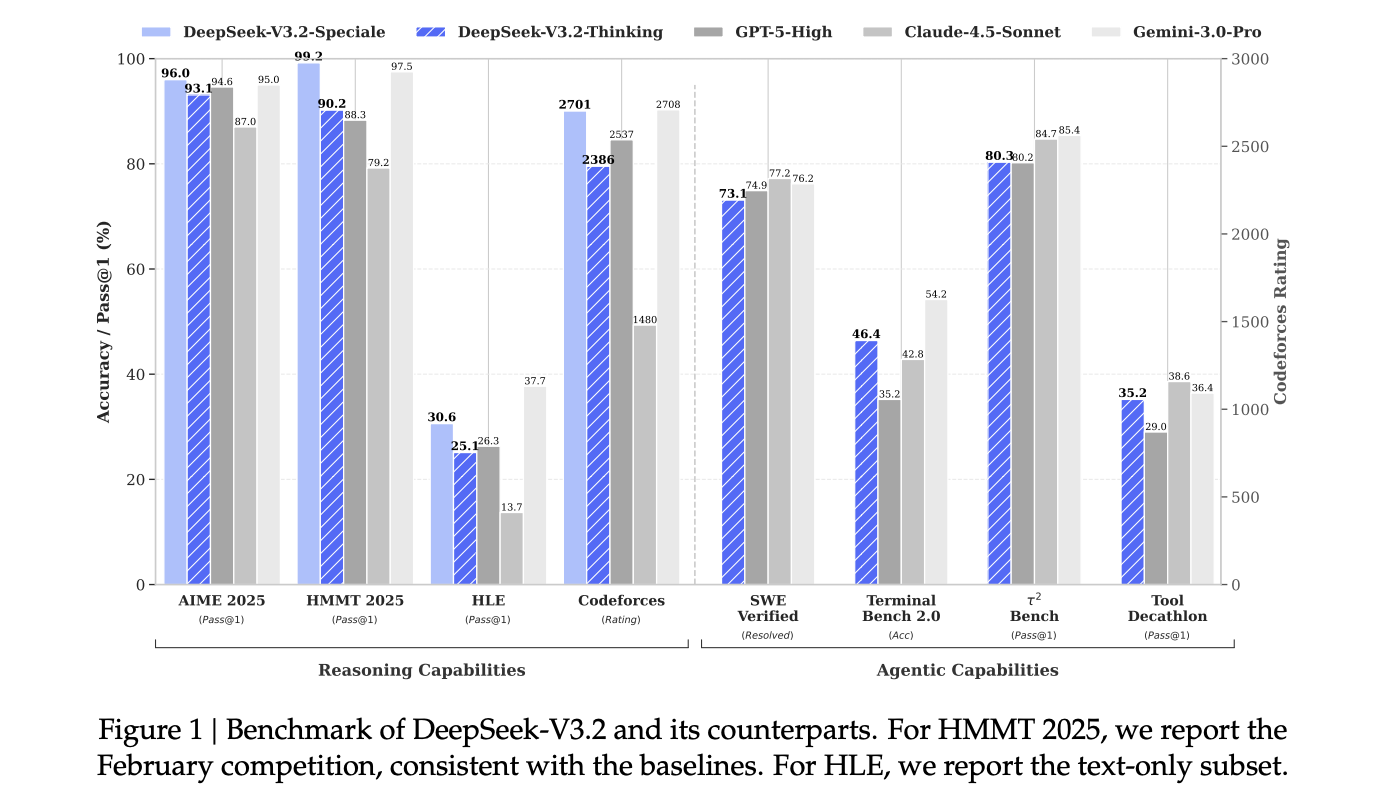
On customary reasoning and coding benchmarks, DeepSeek-V3.2 and particularly DeepSeek-V3.2 Speciale are reported as similar to GPT-5 and near Gemini-3.0 Professional on suites reminiscent of AIME 2025, HMMT 2025, GPQA and LiveCodeBench, with improved price effectivity on lengthy context workloads.
For formal competitions, DeepSeek analysis staff states that DeepSeek-V3.2 Speciale achieves gold medal degree efficiency on the Worldwide Mathematical Olympiad 2025, the Chinese language Mathematical Olympiad 2025 and the Worldwide Olympiad in Informatics 2025, and aggressive gold medal degree efficiency on the ICPC World Finals 2025.
Key Takeaways
- DeepSeek-V3.2 provides DeepSeek Sparse Consideration, which brings close to linear O(kL) consideration price and delivers round 50% decrease lengthy context API price in comparison with earlier dense DeepSeek fashions, whereas maintaining high quality just like DeepSeek-V3.1 Terminus.
- The mannequin household retains the 671B parameter MoE spine with 37B energetic parameters per token and exposes a full 128K context window in manufacturing APIs, which makes lengthy paperwork, multi step chains and enormous device traces sensible moderately than a lab solely characteristic.
- Publish coaching makes use of Group Relative Coverage Optimization (GRPO) with a compute funds that’s greater than 10 % of pre-training, targeted on math, code, normal reasoning, looking or agent workloads and security, together with contest fashion specialists whose circumstances are launched for exterior verification.
- DeepSeek-V3.2 is the primary mannequin within the DeepSeek household to combine considering instantly into device use, supporting each considering and non considering device modes and a protocol the place inside reasoning persists throughout device calls and is reset solely on new consumer messages.
Try the Paper and Mannequin weights. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as effectively.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.










{kind=link}