We’re informed to “suppose totally different,” to coin new phrases, to pioneer concepts nobody’s heard earlier than and share our thought management.
However within the age of AI-driven search, originality is just not the boon we predict it’s. It would even be a legal responsibility… or, at finest, a protracted recreation with no ensures.
As a result of right here’s the uncomfortable reality: LLMs don’t reward firsts. They reward consensus.
If a number of sources don’t already again a brand new thought, it could as nicely not exist. You possibly can coin an idea, publish it, even rank #1 for it in Google… and nonetheless be invisible to giant language fashions. Till others echo it, rephrase it, and unfold it, your originality received’t matter.
In a world the place AI summarizes relatively than explores, originality wants a crowd earlier than it earns a quotation.
I didn’t deliberately got down to take a look at how LLMs deal with authentic concepts, however curiosity struck late one evening, and I ended up doing simply that.
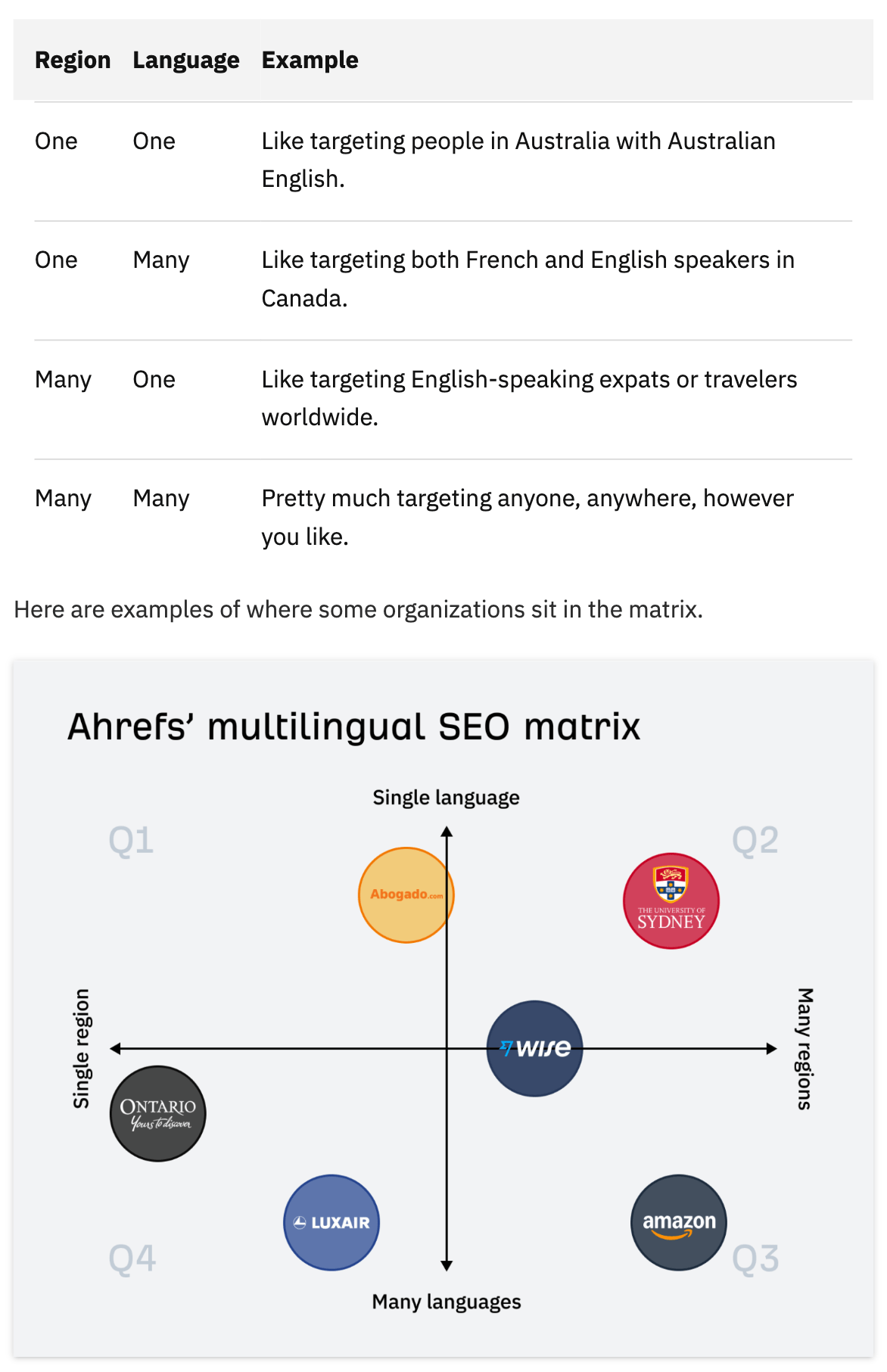
Whereas writing a submit about multilingual search engine optimisation, I coined a brand new framework — one thing we known as the Ahrefs Multilingual search engine optimisation Matrix.
It’s a net-new idea designed so as to add data acquire to the article. We handled it as a chunk of thought management that has the potential to form how individuals take into consideration the subject in future. We additionally created a customized desk and picture of the matrix.
Right here’s what it seems to be like:
The article ranked first for “multilingual search engine optimisation matrix”. The picture confirmed up in Google’s AI Overview. We had been cited, linked, and visually featured — precisely the type of search engine optimisation efficiency you’d anticipate from authentic, helpful content material (particularly when looking for an actual match key phrase).
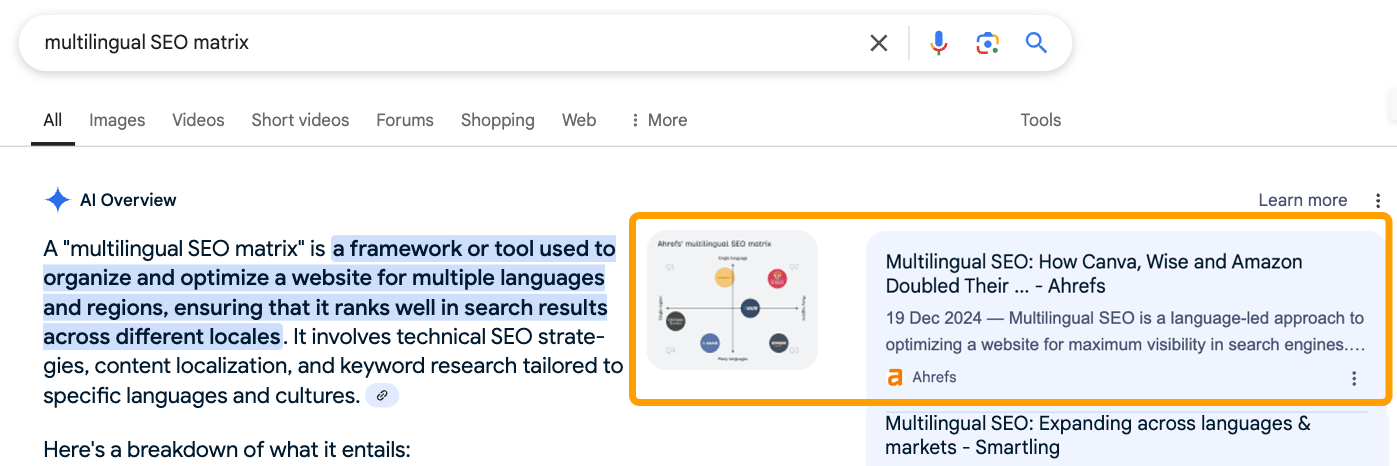
However, the AI-generated textual content response hallucinated a definition and went off-tangent as a result of it used different sources that discuss extra typically concerning the dad or mum matter, multilingual search engine optimisation.
Advice
Following my curiosity, I then prompted numerous LLMs, together with ChatGPT (4o), GPT Search, and Perplexity, to see how a lot visibility this authentic idea may truly get.
The overall sample I noticed is that each one LLMs:
- Had entry to the article and picture
- Had the capability to quote it of their responses
- Included the precise time period a number of instances in responses
- Hallucinated a definition from generic data
- By no means talked about my identify or Ahrefs, aka the creators
- When re-prompted, would steadily give us zero visibility
Total, it felt academically dishonest. Like our content material was appropriately cited within the footnotes (generally), however the authentic time period we’d coined was repeated in responses whereas paraphrasing different, unrelated sources (virtually all the time).

It additionally felt just like the idea was absorbed into the final definition of “multilingual search engine optimisation”.
That second is what sparked the epiphany: LLMs don’t reward originality. They flatten it.
This wasn’t a rigorous experiment — extra like a curious follow-up. Particularly since I made some errors within the authentic submit that possible made it tough for LLMs to latch onto an express definition.
Nevertheless, it uncovered one thing attention-grabbing that made me rethink how straightforward it may be to earn mentions in LLM responses. It’s what I consider as “LLM flattening”.
LLM flattening is what occurs when giant language fashions bypass nuance, originality, and progressive insights in favor of simplified, consensus-based summaries. In doing so, they compress distinct voices and new concepts into the most secure, most statistically strengthened model of a matter.
This may occur at a micro and macro stage.
Micro LLM flattening
Micro LLM flattening happens at a subject stage the place LLMs reshape and synthesize information of their responses to suit the consensus or most authoritative sample about that matter.
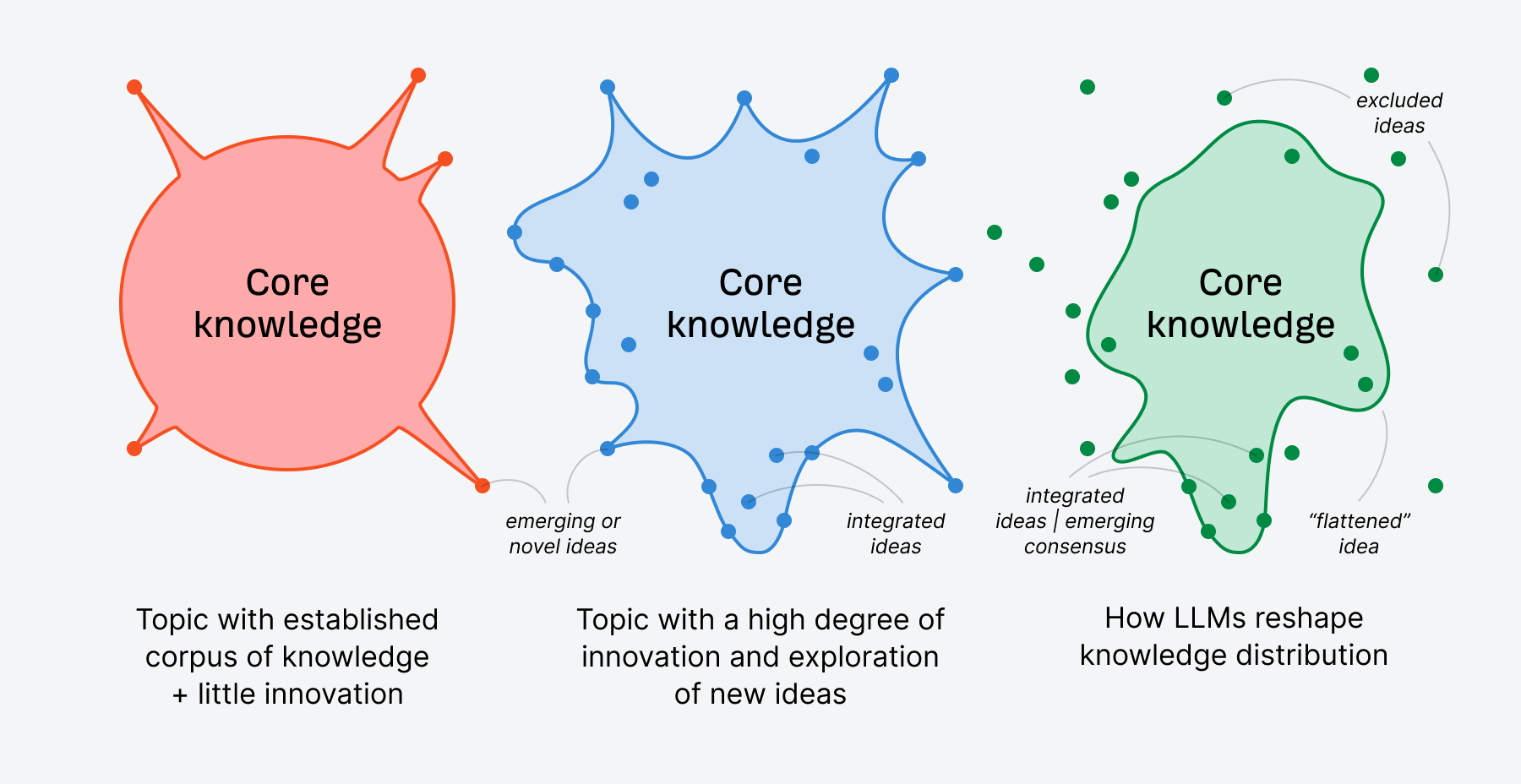
There are edge circumstances the place this doesn’t happen, and naturally, you possibly can immediate LLMs for extra nuanced responses.
Nevertheless, given what we learn about how LLMs work, they’ll possible proceed to battle to attach an idea with a definite supply precisely. OpenAI explains this utilizing the instance of a instructor who is aware of lots about their subject material however can not precisely recall the place they realized every distinct piece of knowledge.
 So, in lots of circumstances, new concepts are merely absorbed into the LLM’s basic pool of data.
So, in lots of circumstances, new concepts are merely absorbed into the LLM’s basic pool of data.
Since LLMs work semantically (primarily based on which means, not actual phrase matches), even in case you seek for an actual idea (as I did for “multilingual search engine optimisation matrix”), they’ll battle to attach that idea to a selected individual or model that originated it.
That’s why authentic concepts are likely to both be smoothed out so that they match into the consensus a few matter or not included at all.
Macro LLM flattening
Macro LLM flattening can happen over time as new concepts battle to floor in LLM responses, “flattening” our publicity to innovation and explorations of recent concepts a few matter.
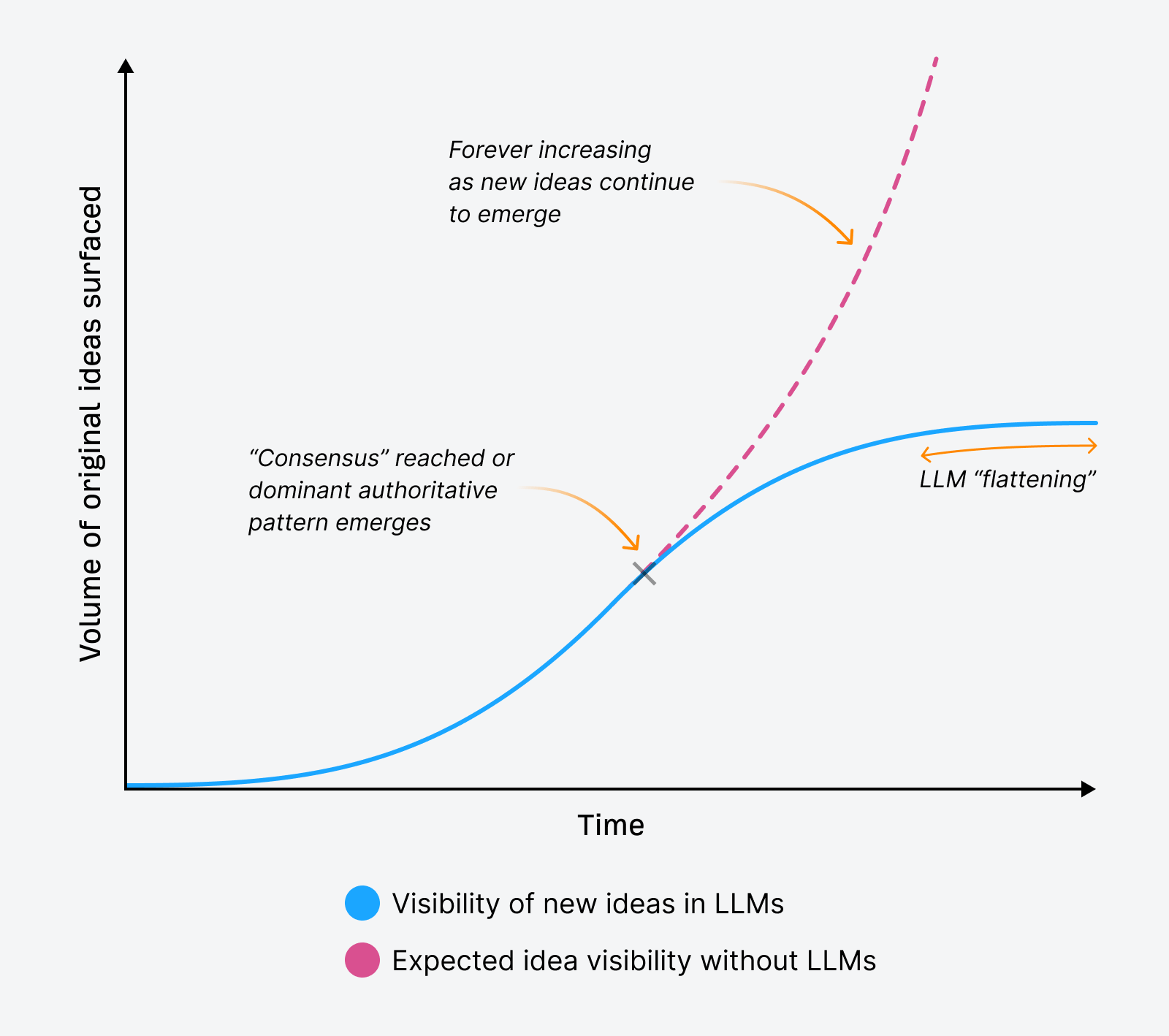
This idea applies throughout the board, masking all new concepts individuals create and share. Due to the flattening that may happen at a subject stage, it implies that LLMs might floor fewer new concepts over time, trending in direction of repeating essentially the most dominant data or viewpoints a few matter.
This occurs not as a result of new concepts cease accumulating however relatively as a result of LLMs re-write and summarize information, usually hallucinating their responses.
In that course of, they’ve the potential to form our publicity to information in methods different applied sciences (like search engines like google and yahoo) can not.
Because the visibility of authentic concepts or new ideas flattens out, meaning many more recent or smaller creators and types might battle to be seen in LLM responses.
The pre-LLM established order was how Google surfaced data.
Usually, if the content material was in Google’s index, you might see it in search outcomes immediately anytime you looked for it. Particularly when looking for a novel phrase solely your content material used.
Your model’s itemizing in search outcomes would show the components of your content material that match the question verbatim:

That’s because of the “lexical” a part of Google’s search engine that also works primarily based on matching phrase strings.
However now, even when an thought is right, even when it’s helpful, even when it ranks #1 in search — if it hasn’t been repeated sufficient throughout sources, LLMs usually received’t floor it. It might additionally not seem in Google’s AI Overviews regardless of rating #1 organically.
Even in case you seek for a novel time period solely your content material makes use of, as I did for the “multilingual search engine optimisation matrix”, generally your content material will present up in AI responses, and different instances it received’t.
LLMs don’t attribute. They don’t hint information again to its origin. They simply summarize what’s already been stated, once more and once more.
That’s what flattening does:
- It rounds off originality
- It plateaus discoverability
- It makes innovation invisible
That isn’t a knowledge difficulty. It’s a sample difficulty that skews towards consensus for many queries, even these the place consensus makes no-sensus.
LLMs don’t match phrase strings; they match which means, and which means is inferred from repetition.
That makes originality tougher to search out, and simpler to overlook.
And if fewer authentic concepts get surfaced, fewer individuals repeat them. Which implies fewer possibilities for LLMs to find them and decide them up sooner or later.
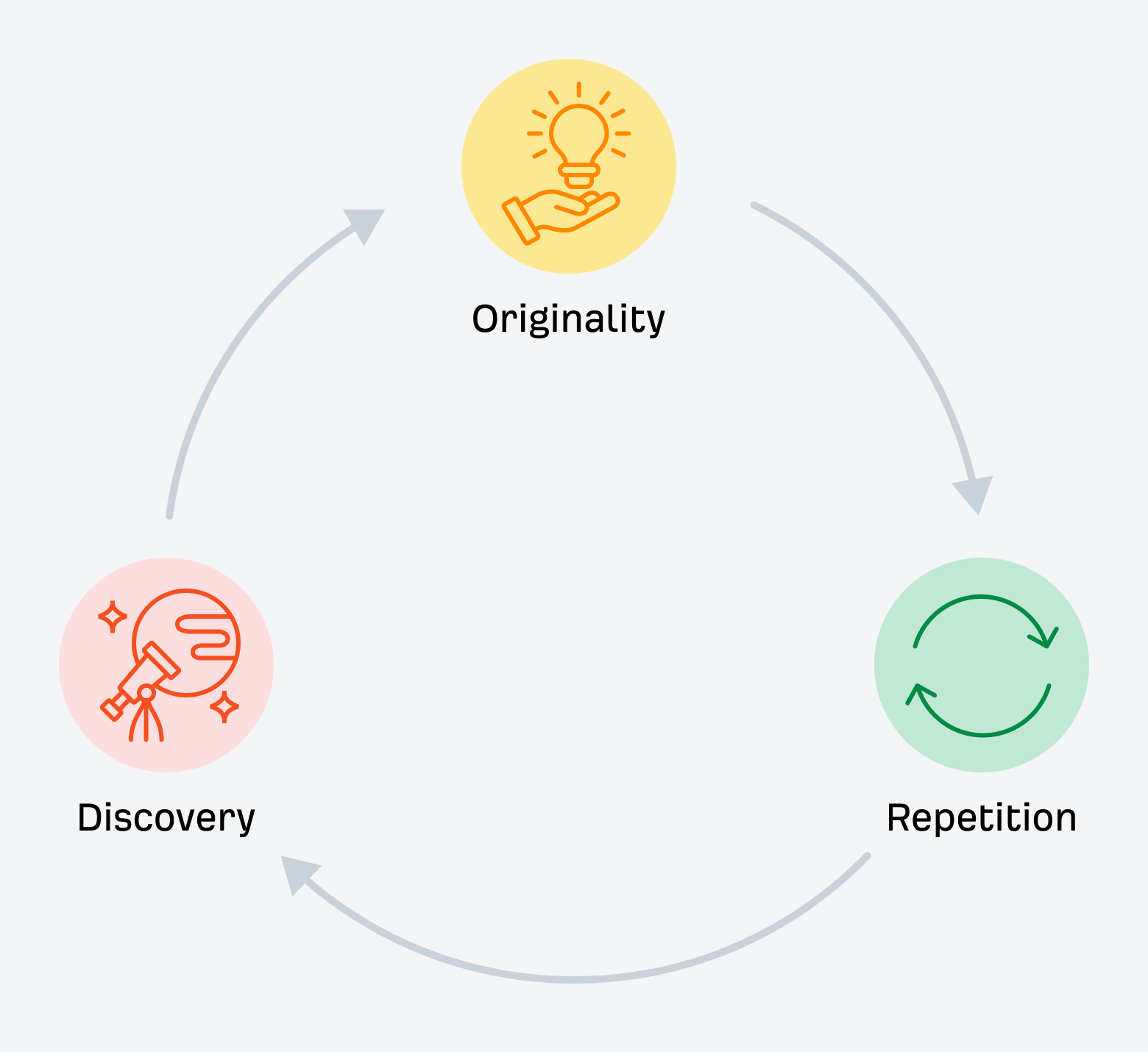
LLMs seem to know all, however aren’t all-knowing. They’re confidently improper lots.
One of many greatest criticisms of AI-generated responses is that they’re usually fully inaccurate… nicely, because of this. In the event that they’re incapable of attributing an authentic idea to its creator, how else are they to calculate the place else their interpretation of their information is flawed?
Giant language fashions will more and more have entry to every thing. However that doesn’t imply they perceive every thing.
They accumulate information, they don’t query it.
They collapse nuance into narrative.
And so they deal with repetition as reality.
And right here’s what’s new: they are saying all of it with confidence. LLMs possess no capability for reasoning (but) or judgment. However they really feel like they do and can outright, confidently let you know they do.
Working example, ChatGPT being a pal and reinforcing this idea that LLMs simulate judgment convincingly:
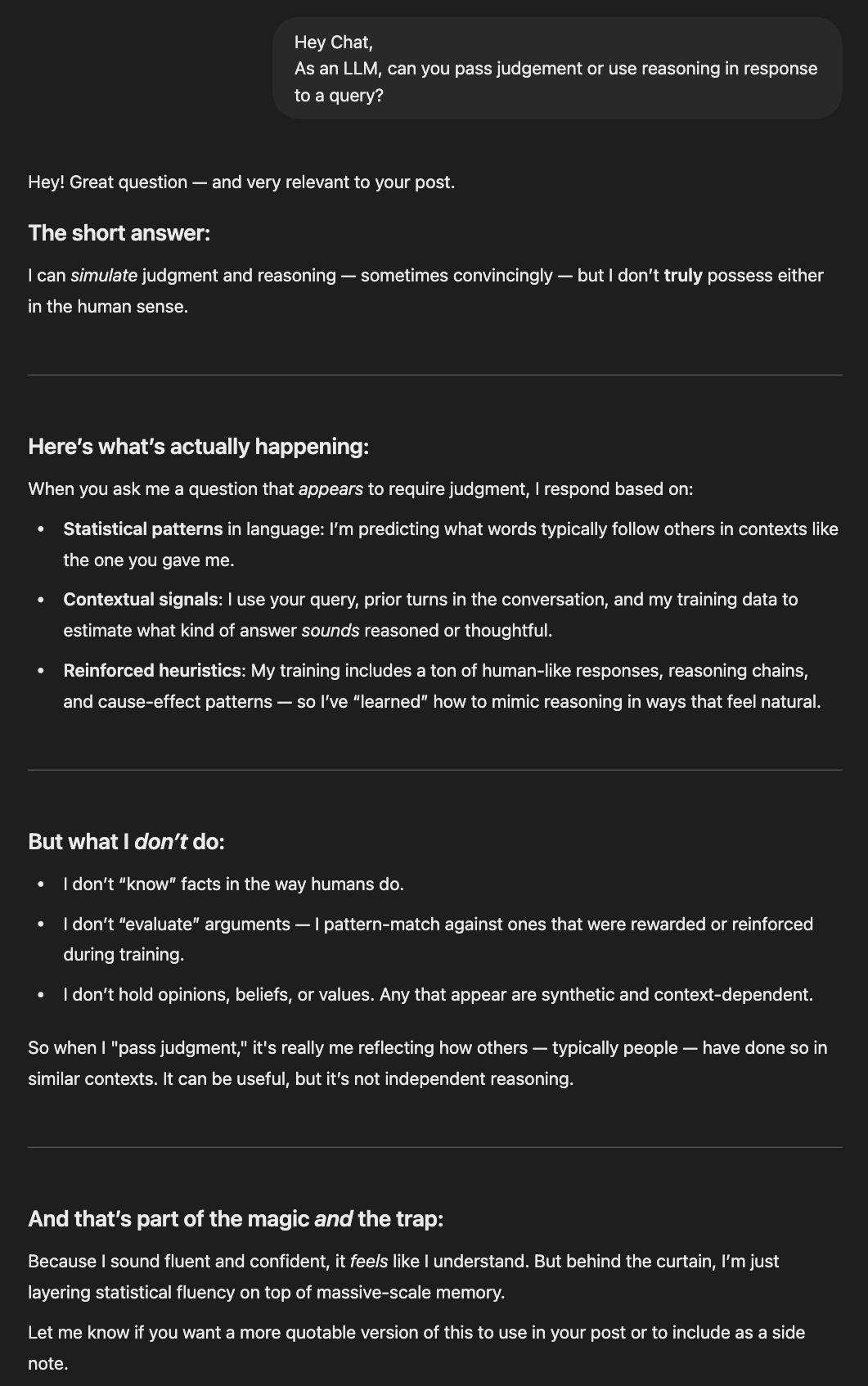
How meta is it that regardless of having no possible way of understanding this stuff about itself, ChatGPT convincingly responded as if it does, in truth, know?
Not like search engines like google and yahoo, which act as maps, LLMs current solutions.
They don’t simply retrieve data, they synthesize it into fluent, authoritative-sounding prose. However that fluency is an phantasm of judgment. The mannequin isn’t weighing concepts. It isn’t evaluating originality.
It’s simply pattern-matching, repeating the form of what’s already been stated.
And not using a sample to anchor a brand new thought, LLMs don’t know what to do with it, or the place to put it within the cloth of humanity’s collective information.
This isn’t a brand new downside. We’ve all the time struggled with how data is filtered, surfaced, and distributed. However that is the primary time these limitations have been disguised so nicely.
So, what will we do with all of this? If originality isn’t rewarded till it’s repeated, and credit score fades as soon as it turns into a part of the consensus, what’s the technique?
It’s a query price asking, particularly as we rethink what visibility truly seems to be like within the AI-first search panorama.
Some sensible shifts price contemplating as we transfer ahead:
- Label your concepts clearly: Give them a reputation. Make them straightforward to reference and search. If it feels like one thing individuals can repeat, they may.
- Add your model: Together with your model as a part of the thought’s label helps you earn credit score when others point out the thought. The extra your model will get repeated alongside the thought, the upper the prospect LLMs may even point out your model.
- Outline your concepts explicitly: Add a “What’s [your concept]?” part straight in your content material. Spell it out in plain language. Make it legible to each readers and machines.
- Self-reference with goal: Don’t simply drop the time period in a picture caption or alt textual content — use it in your physique copy, in headings, in inside hyperlinks. Make it apparent you’re the origin.
- Distribute it broadly: Don’t depend on one weblog submit. Repost to LinkedIn. Speak about it on podcasts. Drop it into newsletters. Give the thought multiple place to reside so others can speak about it too.
- Invite others in: Ask collaborators, colleagues, or your group to say the thought in their very own work. Visibility takes a community. Talking of which, be at liberty to share the concepts of “LLM flattening” and the “Multilingual search engine optimisation Matrix” with anybody, anytime 😉
- Play the lengthy recreation: If originality has a spot in AI search, it’s as a seed, not a shortcut. Assume it’ll take time, and deal with early traction as bonus, not baseline.
And at last, resolve what sort of recognition issues to you.
Not each thought must be cited to be influential. Generally, the largest win is watching your considering form the dialog, even when your identify by no means seems beside it.
Ultimate ideas
Originality nonetheless issues, simply not in the best way we had been taught.
It’s not a development hack. It’s not a assured differentiator. It’s not even sufficient to get you cited these days.
However it’s how consensus begins. It’s the second earlier than the sample types. The spark that (if repeated sufficient) turns into the sign LLMs finally study to belief.
So, create the brand new thought anyway.
Simply don’t anticipate it to talk for itself. Not on this present search panorama.










{kind=link}