Serving Giant Language Fashions (LLMs) at scale is a large engineering problem due to Key-Worth (KV) cache administration. As fashions develop in measurement and reasoning functionality, the KV cache footprint will increase and turns into a significant bottleneck for throughput and latency. For contemporary Transformers, this cache can occupy a number of gigabytes.
NVIDIA researchers have launched KVTC (KV Cache Remodel Coding). This light-weight remodel coder compresses KV caches for compact on-GPU and off-GPU storage. It achieves as much as 20x compression whereas sustaining reasoning and long-context accuracy. For particular use instances, it might attain 40x or increased.
The Reminiscence Dilemma in LLM Inference
In manufacturing, inference frameworks deal with native KV caches like databases. Methods like prefix sharing promote the reuse of caches to hurry up responses. Nonetheless, stale caches eat scarce GPU reminiscence. Builders at present face a troublesome selection:
- Hold the cache: Occupies reminiscence wanted for different customers.
- Discard the cache: Incurs the excessive price of recomputation.
- Offload the cache: Strikes information to CPU DRAM or SSDs, resulting in switch overheads.
KVTC largely mitigates this dilemma by decreasing the price of on-chip retention and lowering the bandwidth required for offloading.

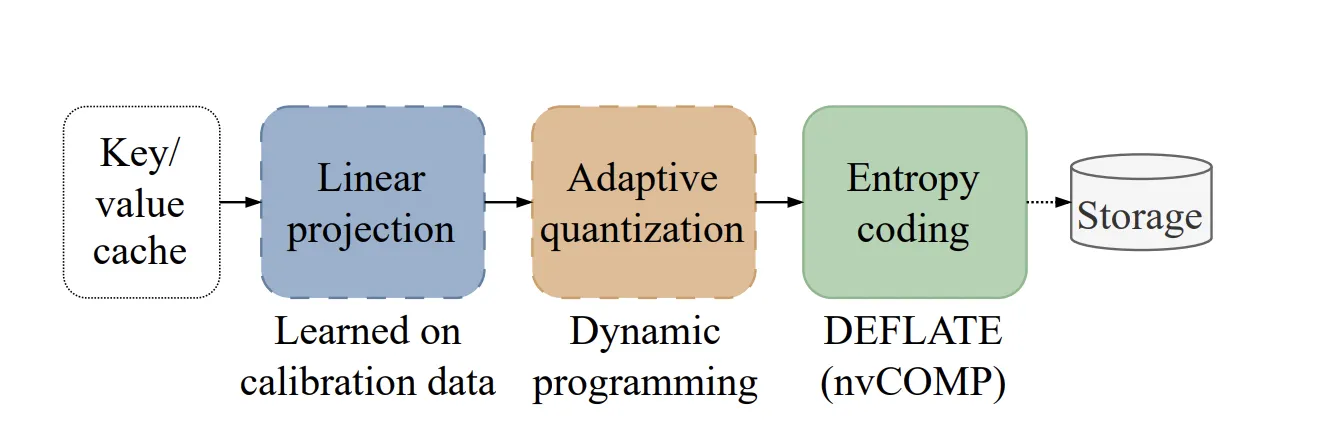
How the KVTC Pipeline Works?
The tactic is impressed by classical media compression. It applies a realized orthonormal remodel, adopted by adaptive quantization and entropy coding.
1. Characteristic Decorrelation (PCA)
Completely different consideration heads usually present related patterns and a excessive diploma of correlation. KVTC makes use of Principal Element Evaluation (PCA) to linearly decorrelate options. Not like different strategies that calculate a separate decomposition for each immediate, KVTC computes the PCA foundation matrix V as soon as on a calibration dataset. This matrix is then reused for all future caches at inference time.
2. Adaptive Quantization
The system exploits the PCA ordering to allocate a hard and fast bit funds throughout coordinates. Excessive-variance parts obtain extra bits, whereas others obtain fewer. KVTC makes use of a dynamic programming (DP) algorithm to search out the optimum bit allocation that minimizes reconstruction error. Crucially, the DP usually assigns 0 bits to trailing principal parts, permitting for early dimensionality discount and quicker efficiency.
3. Entropy Coding
The quantized symbols are packed and compressed utilizing the DEFLATE algorithm. To keep up pace, KVTC leverages the nvCOMP library, which permits parallel compression and decompression straight on the GPU.
Defending Important Tokens
Not all tokens are compressed equally. KVTC avoids compressing two particular forms of tokens as a result of they contribute disproportionately to consideration accuracy:
- Consideration Sinks: The 4 oldest tokens within the sequence.
- Sliding Window: The 128 most up-to-date tokens.
Ablation research present that compressing these particular tokens can considerably decrease and even collapse accuracy at excessive compression ratios.
Benchmarks and Effectivity
The analysis workforce examined KVTC with fashions like Llama-3.1, Mistral-NeMo, and R1-Qwen-2.5.
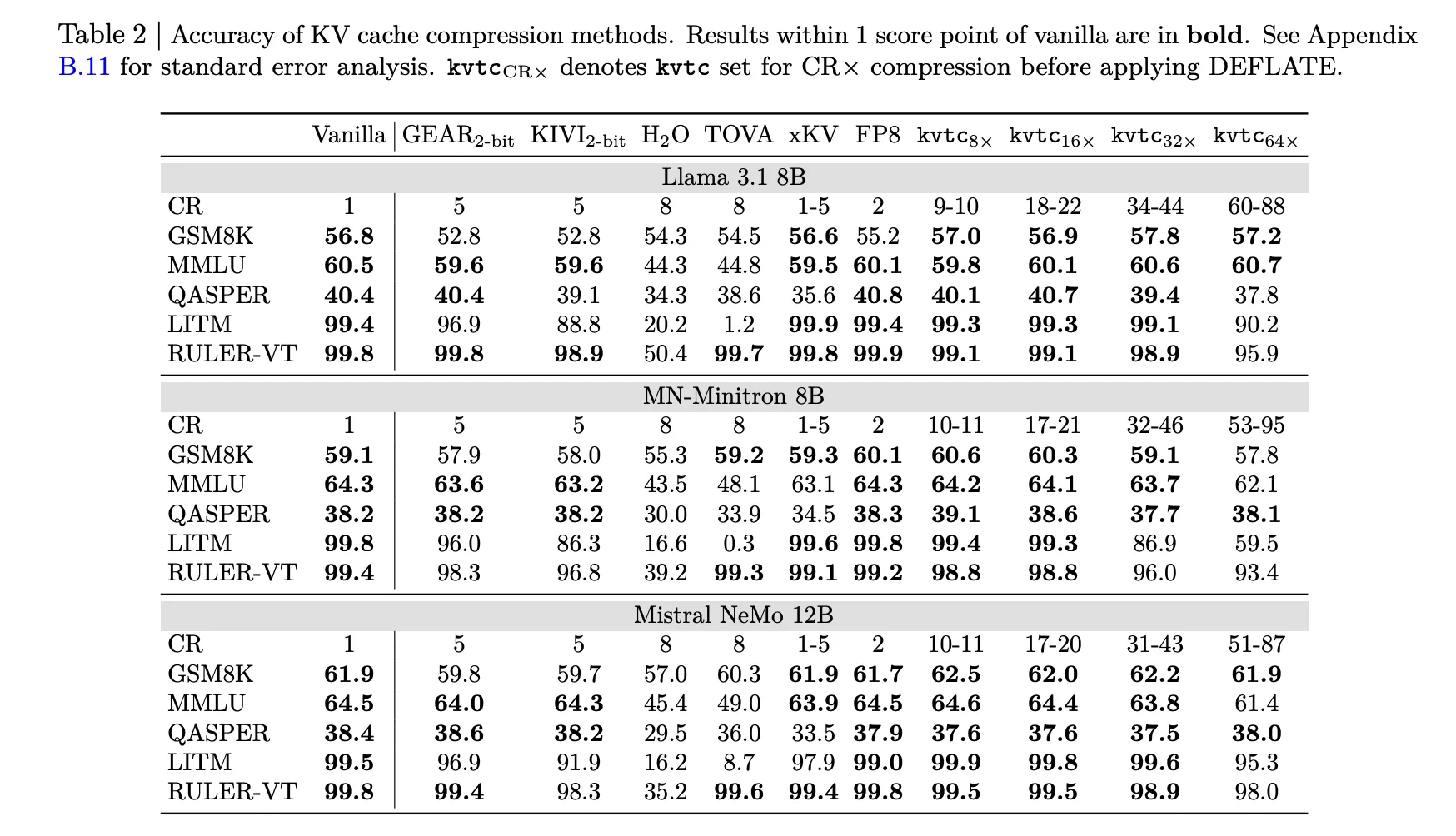
- Accuracy: At 16x compression (roughly 20x after DEFLATE), the mannequin persistently maintains outcomes inside 1 rating level of vanilla fashions.
- TTFT Discount: For an 8K context size, kvtc can scale back Time-To-First-Token (TTFT) by as much as 8x in comparison with full recomputation.
- Pace: Calibration is quick; for a 12B mannequin, it may be accomplished inside 10 minutes on an NVIDIA H100 GPU.
- Storage Overhead: The additional information saved per mannequin is small, representing solely 2.4% of mannequin parameters for Llama-3.3-70B.
KVTC is a sensible constructing block for memory-efficient LLM serving. It doesn’t modify mannequin weights and is straight suitable with different token eviction strategies.
Key Takeaways
- Excessive Compression with Low Accuracy Loss: KVTC achieves a regular 20x compression ratio whereas sustaining outcomes inside 1 rating level of vanilla (uncompressed) fashions throughout most reasoning and long-context benchmarks.
- Remodel Coding Pipeline: The tactic makes use of a pipeline impressed by classical media compression, combining PCA-based characteristic decorrelation, adaptive quantization through dynamic programming, and lossless entropy coding (DEFLATE).
- Important Token Safety: To keep up mannequin efficiency, KVTC avoids compressing the 4 oldest ‘consideration sink’ tokens and a ‘sliding window’ of the 128 most up-to-date tokens.
- Operational Effectivity: The system is ‘tuning-free,’ requiring solely a short preliminary calibration (below 10 minutes for a 12B mannequin) that leaves mannequin parameters unchanged and provides minimal storage overhead—solely 2.4% for a 70B mannequin.
- Vital Latency Discount: By lowering the amount of knowledge saved and transferred, KVTC can scale back Time-To-First-Token (TTFT) by as much as 8x in comparison with the total recomputation of KV caches for lengthy contexts.
Try the Paper right here. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be part of us on telegram as properly.







![How creators and entrepreneurs are utilizing AI to hurry up & succeed [data]](https://blog.aimactgrow.com/wp-content/uploads/2025/06/Untitled20design-Apr-07-2023-08-24-35-4586-PM-120x86.png)




{kind=link}