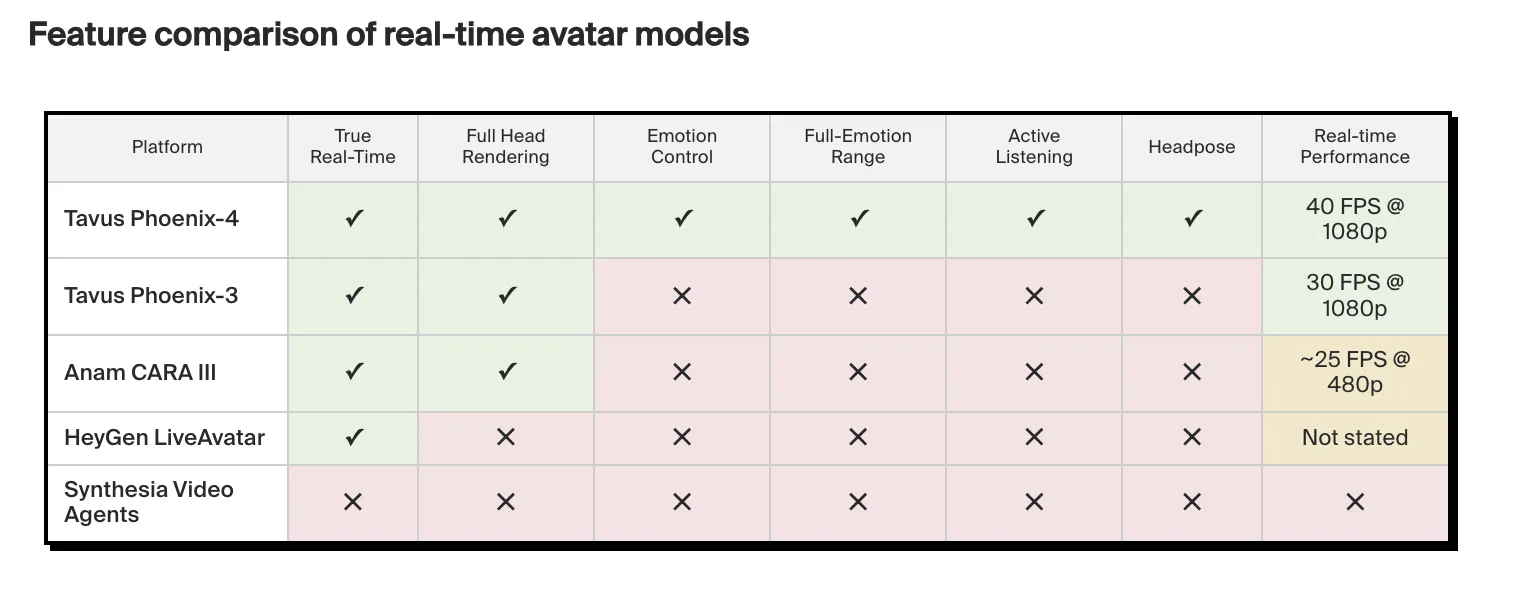
The ‘uncanny valley’ is the ultimate frontier for generative video. We now have seen AI avatars that may speak, however they usually lack the soul of human interplay. They undergo from stiff actions and an absence of emotional context. Tavus goals to repair this with the launch of Phoenix-4, a brand new generative AI mannequin designed for the Conversational Video Interface (CVI).
Phoenix-4 represents a shift from static video era to dynamic, real-time human rendering. It’s not nearly shifting lips; it’s about making a digital human that perceives, occasions, and reacts with emotional intelligence.
The Energy of Three: Raven, Sparrow, and Phoenix
To realize true realism, Tavus makes use of a 3-part mannequin structure. Understanding how these fashions work together is essential for builders seeking to construct interactive brokers.
- Raven-1 (Notion): This mannequin acts because the ‘eyes and ears.’ It analyzes the person’s facial expressions and tone of voice to know the emotional context of the dialog.
- Sparrow-1 (Timing): This mannequin manages the stream of dialog. It determines when the AI ought to interrupt, pause, or await the person to complete, guaranteeing the interplay feels pure.
- Phoenix-4 (Rendering): The core rendering engine. It makes use of Gaussian-diffusion to synthesize photorealistic video in real-time.

Technical Breakthrough: Gaussian-Diffusion Rendering
Phoenix-4 strikes away from conventional GAN-based approaches. As an alternative, it makes use of a proprietary Gaussian-diffusion rendering mannequin. This enables the AI to calculate advanced facial actions, resembling the way in which pores and skin stretching impacts mild or how micro-expressions seem across the eyes.
This implies the mannequin handles spatial consistency higher than earlier variations. If a digital human turns their head, the textures and lighting stay steady. The mannequin generates these high-fidelity frames at a fee that helps 30 frames per second (fps) streaming, which is important for sustaining the phantasm of life.
Breaking the Latency Barrier: Sub-600ms
In a CVI, velocity is all the things. If the delay between a person talking and the AI responding is simply too lengthy, the ‘human’ really feel is misplaced. Tavus has developed the Phoenix 4 pipeline to realize an end-to-end conversational latency of sub-600ms.
That is achieved by way of a ‘stream-first’ structure. The mannequin makes use of WebRTC (Internet Actual-Time Communication) to stream video knowledge on to the shopper’s browser. Relatively than producing a full video file after which taking part in it, Phoenix-4 renders and sends video packets incrementally. This ensures that the time to first body is saved at an absolute minimal.
Programmatic Emotion Management
One of the vital highly effective options is the Emotion Management API. Builders can now explicitly outline the emotional state of a Persona throughout a dialog.
By passing an emotion parameter within the API request, you may set off particular behavioral outputs. The mannequin at present helps main emotional states together with:
- Pleasure
- Disappointment
- Anger
- Shock
When the emotion is ready to pleasure, the Phoenix-4 engine adjusts the facial geometry to create a real smile, affecting the cheeks and eyes, not simply the mouth. It is a type of conditional video era the place the output is influenced by each the text-to-speech phonemes and an emotional vector.
Constructing with Replicas
Making a customized ‘Duplicate’ (a digital twin) requires solely 2 minutes of video footage for coaching. As soon as the coaching is full, the Duplicate could be deployed by way of the Tavus CVI SDK.
The workflow is simple:
- Practice: Add 2 minutes of an individual talking to create a singular
replica_id. - Deploy: Use the
POST /conversationsendpoint to begin a session. - Configure: Set the
persona_idand theconversation_name. - Join: Hyperlink the supplied WebRTC URL to your front-end video element.
Key Takeaways
- Gaussian-Diffusion Rendering: Phoenix-4 strikes past conventional GANs to make use of Gaussian-diffusion, enabling high-fidelity, photorealistic facial actions and micro-expressions that resolve the ‘uncanny valley’ downside.
- The AI Trinity (Raven, Sparrow, Phoenix): The structure depends on three distinct fashions: Raven-1 for emotional notion, Sparrow-1 for conversational timing/turn-taking, and Phoenix-4 for the ultimate video synthesis.
- Extremely-Low Latency: Optimized for the Conversational Video Interface (CVI), the mannequin achieves sub-600ms end-to-end latency, using WebRTC to stream video packets in real-time.
- Programmatic Emotion Management: You should utilize an Emotion Management API to specify states like pleasure, unhappiness, anger, or shock, which dynamically adjusts the character’s facial geometry and expressions.
- Speedy Duplicate Coaching: Making a customized digital twin (‘Duplicate’) is extremely environment friendly, requiring solely 2 minutes of video footage to coach a singular id for deployment by way of the Tavus SDK.
Take a look at the Technical particulars, Docs and Attempt it right here. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be part of us on telegram as nicely.










{kind=link}