Advanced prediction issues typically result in ensembles as a result of combining a number of fashions improves accuracy by lowering variance and capturing numerous patterns. Nonetheless, these ensembles are impractical in manufacturing on account of latency constraints and operational complexity.
As a substitute of discarding them, Information Distillation gives a better method: hold the ensemble as a instructor and prepare a smaller pupil mannequin utilizing its tender likelihood outputs. This enables the scholar to inherit a lot of the ensemble’s efficiency whereas being light-weight and quick sufficient for deployment.
On this article, we construct this pipeline from scratch — coaching a 12-model instructor ensemble, producing tender targets with temperature scaling, and distilling it right into a pupil that recovers 53.8% of the ensemble’s accuracy edge at 160× the compression.
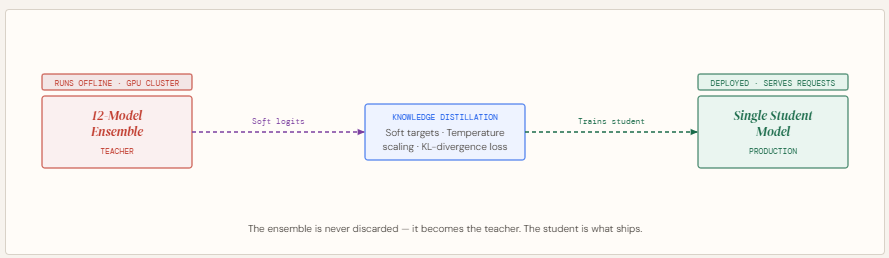

What’s Information Distillation?
Information distillation is a mannequin compression approach wherein a big, pre-trained “instructor” mannequin transfers its realized habits to a smaller “pupil” mannequin. As a substitute of coaching solely on ground-truth labels, the scholar is skilled to imitate the instructor’s predictions—capturing not simply ultimate outputs however the richer patterns embedded in its likelihood distributions. This method permits the scholar to approximate the efficiency of advanced fashions whereas remaining considerably smaller and sooner. Originating from early work on compressing giant ensemble fashions into single networks, information distillation is now extensively used throughout domains like NLP, speech, and pc imaginative and prescient, and has develop into particularly essential in cutting down huge generative AI fashions into environment friendly, deployable programs.
Information Distillation: From Ensemble Instructor to Lean Scholar
Establishing the dependencies
pip set up torch scikit-learn numpyimport torch
import torch.nn as nn
import torch.nn.useful as F
from torch.utils.knowledge import DataLoader, TensorDataset
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import numpy as nptorch.manual_seed(42)
np.random.seed(42)Creating the dataset
This block creates and prepares an artificial dataset for a binary classification process (like predicting whether or not a person clicks an advert). First, make_classification generates 5,000 samples with 20 options, of which some are informative and a few redundant to simulate real-world knowledge complexity. The dataset is then break up into coaching and testing units to guage mannequin efficiency on unseen knowledge.
Subsequent, StandardScaler normalizes the options so that they have a constant scale, which helps neural networks prepare extra effectively. The info is then transformed into PyTorch tensors so it may be utilized in mannequin coaching. Lastly, a DataLoader is created to feed the info in mini-batches (measurement 64) throughout coaching, enhancing effectivity and enabling stochastic gradient descent.
X, y = make_classification(
n_samples=5000, n_features=20, n_informative=10,
n_redundant=5, random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.rework(X_test)
# Convert to tensors
X_train_t = torch.tensor(X_train, dtype=torch.float32)
y_train_t = torch.tensor(y_train, dtype=torch.lengthy)
X_test_t = torch.tensor(X_test, dtype=torch.float32)
y_test_t = torch.tensor(y_test, dtype=torch.lengthy)
train_loader = DataLoader(
TensorDataset(X_train_t, y_train_t), batch_size=64, shuffle=True
)Mannequin Structure
This part defines two neural community architectures: a TeacherModel and a StudentModel. The instructor represents one of many giant fashions within the ensemble—it has a number of layers, wider dimensions, and dropout for regularization, making it extremely expressive however computationally costly throughout inference.
The coed mannequin, then again, is a smaller and extra environment friendly community with fewer layers and parameters. Its aim is to not match the instructor’s complexity, however to study its habits by distillation. Importantly, the scholar nonetheless retains sufficient capability to approximate the instructor’s choice boundaries—too small, and it received’t have the ability to seize the richer patterns realized by the ensemble.
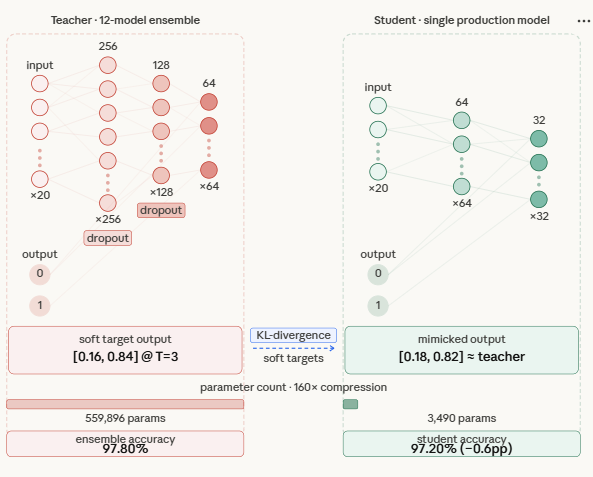
class TeacherModel(nn.Module):
"""Represents one heavy mannequin contained in the ensemble."""
def __init__(self, input_dim=20, num_classes=2):
tremendous().__init__()
self.internet = nn.Sequential(
nn.Linear(input_dim, 256), nn.ReLU(), nn.Dropout(0.3),
nn.Linear(256, 128), nn.ReLU(), nn.Dropout(0.3),
nn.Linear(128, 64), nn.ReLU(),
nn.Linear(64, num_classes)
)
def ahead(self, x):
return self.internet(x)
class StudentModel(nn.Module):
"""
The lean manufacturing mannequin that learns from the ensemble.
Two hidden layers -- sufficient capability to soak up distilled
information, nonetheless ~30x smaller than the total ensemble.
"""
def __init__(self, input_dim=20, num_classes=2):
tremendous().__init__()
self.internet = nn.Sequential(
nn.Linear(input_dim, 64), nn.ReLU(),
nn.Linear(64, 32), nn.ReLU(),
nn.Linear(32, num_classes)
)
def ahead(self, x):
return self.internet(x)Helpers
This part defines two utility features for coaching and analysis.
train_one_epoch handles one full cross over the coaching knowledge. It places the mannequin in coaching mode, iterates by mini-batches, computes the loss, performs backpropagation, and updates the mannequin weights utilizing the optimizer. It additionally tracks and returns the typical loss throughout all batches to observe coaching progress.
consider is used to measure mannequin efficiency. It switches the mannequin to analysis mode (disabling dropout and gradients), makes predictions on the enter knowledge, and computes the accuracy by evaluating predicted labels with true labels.
def train_one_epoch(mannequin, loader, optimizer, criterion):
mannequin.prepare()
total_loss = 0
for xb, yb in loader:
optimizer.zero_grad()
loss = criterion(mannequin(xb), yb)
loss.backward()
optimizer.step()
total_loss += loss.merchandise()
return total_loss / len(loader)
def consider(mannequin, X, y):
mannequin.eval()
with torch.no_grad():
preds = mannequin(X).argmax(dim=1)
return (preds == y).float().imply().merchandise()Coaching the Ensemble
This part trains the instructor ensemble, which serves because the supply of information for distillation. As a substitute of a single mannequin, 12 instructor fashions are skilled independently with totally different random initializations, permitting every one to study barely totally different patterns from the info. This range is what makes ensembles highly effective.
Every instructor is skilled for a number of epochs till convergence, and their particular person take a look at accuracies are printed. As soon as all fashions are skilled, their predictions are mixed utilizing tender voting—by averaging their output logits reasonably than taking a easy majority vote. This produces a stronger, extra secure ultimate prediction, supplying you with a high-performing ensemble that may act because the “instructor” within the subsequent step.
print("=" * 55)
print("STEP 1: Coaching the 12-model Instructor Ensemble")
print(" (this occurs offline, not in manufacturing)")
print("=" * 55)
NUM_TEACHERS = 12
lecturers = []
for i in vary(NUM_TEACHERS):
torch.manual_seed(i) # totally different init per instructor
mannequin = TeacherModel()
optimizer = torch.optim.Adam(mannequin.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
for epoch in vary(30): # prepare till convergence
train_one_epoch(mannequin, train_loader, optimizer, criterion)
acc = consider(mannequin, X_test_t, y_test_t)
print(f" Instructor {i+1:02d} -> take a look at accuracy: {acc:.4f}")
mannequin.eval()
lecturers.append(mannequin)
# Tender voting: common logits throughout all lecturers (stronger than majority vote)
with torch.no_grad():
avg_logits = torch.stack([t(X_test_t) for t in teachers], dim=0).imply(dim=0)
ensemble_preds = avg_logits.argmax(dim=1)
ensemble_acc = (ensemble_preds == y_test_t).float().imply().merchandise()
print(f"n Ensemble (tender vote) accuracy: {ensemble_acc:.4f}")Producing Tender Targets from the Ensemble
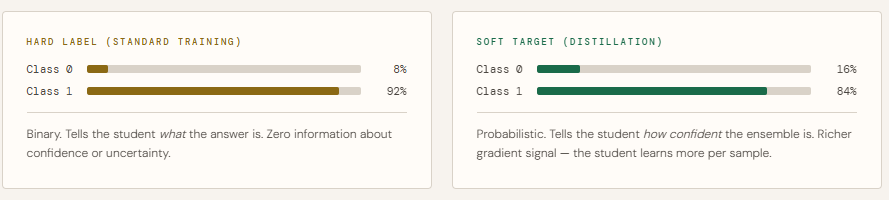
This step generates tender targets from the skilled instructor ensemble, that are the important thing ingredient in information distillation. As a substitute of utilizing onerous labels (0 or 1), the ensemble’s averaged predictions are transformed into likelihood distributions, capturing how assured the mannequin is throughout all lessons.
The operate first averages the logits from all lecturers (tender voting), then applies temperature scaling to clean the possibilities. A better temperature (like 3.0) makes the distribution softer, revealing refined relationships between lessons that arduous labels can not seize. These tender targets present richer studying indicators, permitting the scholar mannequin to higher approximate the ensemble’s habits.
TEMPERATURE = 3.0 # controls how "tender" the instructor's output is
def get_ensemble_soft_targets(lecturers, X, T):
"""
Common logits from all lecturers, then apply temperature scaling.
Tender targets carry richer sign than onerous 0/1 labels.
"""
with torch.no_grad():
logits = torch.stack([t(X) for t in teachers], dim=0).imply(dim=0)
return F.softmax(logits / T, dim=1) # tender likelihood distribution
soft_targets = get_ensemble_soft_targets(lecturers, X_train_t, TEMPERATURE)
print(f"n Pattern onerous label : {y_train_t[0].merchandise()}")
print(f" Pattern tender goal: [{soft_targets[0,0]:.4f}, {soft_targets[0,1]:.4f}]")
print(" -> Tender goal carries confidence data, not simply class identification.")Distillation: Coaching the Scholar
This part trains the scholar mannequin utilizing information distillation, the place it learns from each the instructor ensemble and the true labels. A brand new dataloader is created that gives inputs together with onerous labels and tender targets collectively.
Throughout coaching, two losses are computed:
- Distillation loss (KL-divergence) encourages the scholar to match the instructor’s softened likelihood distribution, transferring the ensemble’s “information.”
- Exhausting label loss (cross-entropy) ensures the scholar nonetheless aligns with the bottom fact.
These are mixed utilizing a weighting issue (ALPHA), the place a better worth provides extra significance to the instructor’s steerage. Temperature scaling is utilized once more to maintain consistency with the tender targets, and a rescaling issue ensures secure gradients. Over a number of epochs, the scholar steadily learns to approximate the ensemble’s habits whereas remaining a lot smaller and environment friendly for deployment.
print("n" + "=" * 55)
print("STEP 2: Coaching the Scholar through Information Distillation")
print(" (this produces the only manufacturing mannequin)")
print("=" * 55)
ALPHA = 0.7 # weight on distillation loss (0.7 = principally tender targets)
EPOCHS = 50
pupil = StudentModel()
optimizer = torch.optim.Adam(pupil.parameters(), lr=1e-3, weight_decay=1e-4)
ce_loss_fn = nn.CrossEntropyLoss()
# Dataloader that yields (inputs, onerous labels, tender targets) collectively
distill_loader = DataLoader(
TensorDataset(X_train_t, y_train_t, soft_targets),
batch_size=64, shuffle=True
)
for epoch in vary(EPOCHS):
pupil.prepare()
epoch_loss = 0
for xb, yb, soft_yb in distill_loader:
optimizer.zero_grad()
student_logits = pupil(xb)
# (1) Distillation loss: match the instructor's tender distribution
# KL-divergence between pupil and instructor outputs at temperature T
student_soft = F.log_softmax(student_logits / TEMPERATURE, dim=1)
distill_loss = F.kl_div(student_soft, soft_yb, discount='batchmean')
distill_loss *= TEMPERATURE ** 2 # rescale: retains gradient magnitude
# secure throughout totally different T values
# (2) Exhausting label loss: additionally study from floor fact
hard_loss = ce_loss_fn(student_logits, yb)
# Mixed loss
loss = ALPHA * distill_loss + (1 - ALPHA) * hard_loss
loss.backward()
optimizer.step()
epoch_loss += loss.merchandise()
if (epoch + 1) % 10 == 0:
acc = consider(pupil, X_test_t, y_test_t)
print(f" Epoch {epoch+1:02d}/{EPOCHS} loss: {epoch_loss/len(distill_loader):.4f} "
f"pupil accuracy: {acc:.4f}")Scholar skilled on on Exhausting Labels solely
This part trains a baseline pupil mannequin with out information distillation, utilizing solely the bottom fact labels. The structure is equivalent to the distilled pupil, making certain a good comparability.
The mannequin is skilled in the usual approach with cross-entropy loss, studying straight from onerous labels with none steerage from the instructor ensemble. After coaching, its accuracy is evaluated on the take a look at set.
This baseline acts as a reference level—permitting you to obviously measure how a lot efficiency achieve comes particularly from distillation, reasonably than simply the scholar mannequin’s capability or coaching course of.
print("n" + "=" * 55)
print("BASELINE: Scholar skilled on onerous labels solely (no distillation)")
print("=" * 55)
baseline_student = StudentModel()
b_optimizer = torch.optim.Adam(
baseline_student.parameters(), lr=1e-3, weight_decay=1e-4
)
for epoch in vary(EPOCHS):
train_one_epoch(baseline_student, train_loader, b_optimizer, ce_loss_fn)
baseline_acc = consider(baseline_student, X_test_t, y_test_t)
print(f" Baseline pupil accuracy: {baseline_acc:.4f}")Comparability
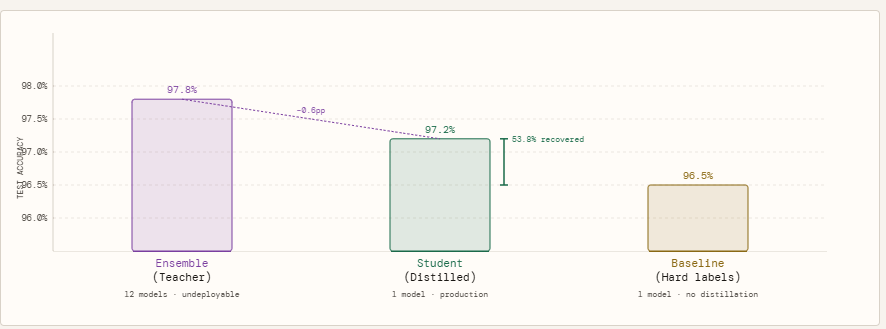
To measure how a lot the ensemble’s information really transfers, we run three fashions in opposition to the identical held-out take a look at set. The ensemble — all 12 lecturers voting collectively through averaged logits — units the accuracy ceiling at 97.80%. That is the quantity we are attempting to approximate, not beat. The baseline pupil is a similar single-model structure skilled the standard approach, on onerous labels solely: it sees every pattern as a binary 0 or 1, nothing extra. It lands at 96.50%. The distilled pupil is identical structure once more, however skilled on the ensemble’s tender likelihood outputs at temperature T=3, with a mixed loss weighted 70% towards matching the instructor’s distribution and 30% towards floor fact labels. It reaches 97.20%.
The 0.70 share level hole between the baseline and the distilled pupil shouldn’t be a coincidence of random seed or coaching noise — it’s the measurable worth of the tender targets. The coed didn’t get extra knowledge, a greater structure, or extra computation. It acquired a richer coaching sign, and that alone recovered 53.8% of the hole between what a small mannequin can study by itself and what the total ensemble is aware of. The remaining hole of 0.60 share factors between the distilled pupil and the ensemble is the sincere price of compression — the portion of the ensemble’s information {that a} 3,490-parameter mannequin merely can not maintain, no matter how nicely it’s skilled.
distilled_acc = consider(pupil, X_test_t, y_test_t)
print("n" + "=" * 55)
print("RESULTS SUMMARY")
print("=" * 55)
print(f" Ensemble (12 fashions, production-undeployable) : {ensemble_acc:.4f}")
print(f" Scholar (distilled, production-ready) : {distilled_acc:.4f}")
print(f" Baseline (pupil, onerous labels solely) : {baseline_acc:.4f}")
hole = ensemble_acc - distilled_acc
restoration = (distilled_acc - baseline_acc) / max(ensemble_acc - baseline_acc, 1e-9)
print(f"n Accuracy hole vs ensemble : {hole:.4f}")
print(f" Information recovered vs baseline: {restoration*100:.1f}%")def count_params(m):
return sum(p.numel() for p in m.parameters())
single_teacher_params = count_params(lecturers[0])
student_params = count_params(pupil)
print(f"n Single instructor parameters : {single_teacher_params:,}")
print(f" Full ensemble parameters : {single_teacher_params * NUM_TEACHERS:,}")
print(f" Scholar parameters : {student_params:,}")
print(f" Dimension discount : {single_teacher_params * NUM_TEACHERS / student_params:.0f}x")
Take a look at the Full Codes right here. Additionally, be at liberty to comply with us on Twitter and don’t overlook to affix our 120k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be a part of us on telegram as nicely.
Must associate with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and many others.? Join with us

I’m a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I’ve a eager curiosity in Information Science, particularly Neural Networks and their utility in numerous areas.










{kind=link}