The outdated natural search measurement mannequin, constructed largely round rankings, clicks, and classes, is changing into much less ample by itself in an AI search setting. And the extra I speak to SEOs, entrepreneurs, and management groups, the clearer it turns into that the majority of us are nonetheless making an attempt to adapt the outdated mannequin fairly than broaden it into one thing match for AI search.
- Conventional search typically gave us a ranked checklist of hyperlinks, extra query-level positional visibility, a largely click-led journey, and a measurement mannequin closely centered on Google.
- AI search offers us one thing totally different: synthesized solutions, outputs that may fluctuate throughout classes, affect that will occur with no click on, and fragmented experiences throughout ChatGPT, Perplexity, Gemini, Claude, Microsoft Copilot, and Google Search options similar to AI Overviews and AI Mode.
Right here’s one of the vital modifications: a model can now be surfaced, really useful, and materially affect a purchase order choice in AI search with out essentially producing a click on.
A consumer asks ChatGPT “what’s the most effective PR alternative instrument for a small company managing B2B SaaS purchasers?”, reads the reply, learns about three choices, varieties a choice, after which searches the model title immediately on Google. Or varieties the URL. Or opens the app. A significant a part of the choice course of could have occurred contained in the AI platform, whereas the eventual conversion was usually attributed elsewhere.
That aligns with considerations raised by respondents in SEOFOMO’s Natural Search Tendencies survey round AI attribution and belief, reflecting how tough it’s to evaluate AI affect when many journeys don’t produce immediately attributable clicks.
So we want a special mannequin. One which doesn’t confuse measurable with significant, and doesn’t throw out business accountability simply because attribution is more durable.
Right here’s a framework that doesn’t declare full attribution, isn’t an alternative choice to CRM or product analytics, and doesn’t promise that AI visibility will all the time translate into measurable enterprise influence. It’s a structured option to measure, diagnose, and prioritize in an setting the place observability is partial, platform habits differs, and affect usually extends past immediately attributable clicks.
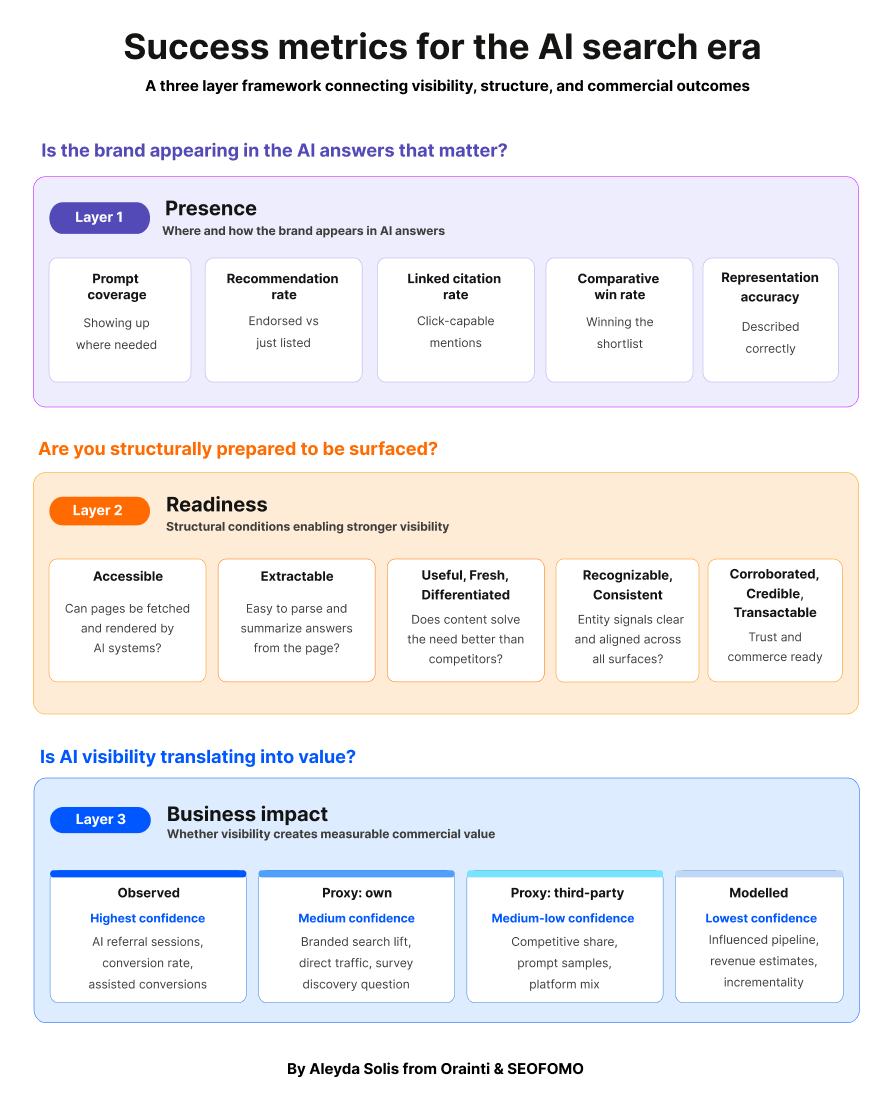
The three layers of AI search success
I’ve been working with this framework throughout shopper engagements and my very own manufacturers, and it has persistently helped produce extra significant selections than a single dashboard strategy.
It has three related metric layers:
| Metric layer | What it measures | Why it issues | KPI function |
|---|---|---|---|
| 1. Presence | Whether or not the model seems within the AI solutions that matter, the way it’s represented, cited, linked, and really useful | Replaces visitors solely considering with visibility and illustration measurement | Visibility KPIs: optimization and monitoring |
| 2. Readiness | Whether or not the structural situations wanted for stronger visibility are in place | Explains why visibility is weak, sturdy, or unstable, the diagnostic layer | Diagnostic KPIs: prognosis and prioritization |
| 3. Enterprise Impression | Whether or not visibility is translating into measurable worth, utilizing noticed, proxy, and modelled indicators | Connects AI search exercise to business outcomes with out overclaiming attribution | Final result KPIs: govt reporting and decision-making |
The purpose isn’t to run three disconnected audits. It’s that:
- Presence tells you the place the model seems,
- Readiness tells you why it seems that manner,
- and Enterprise Impression tells you whether or not that visibility creates measurable worth.
Every layer fingers off a speculation to the subsequent. That’s what turns three stories into one diagnostic.
A number of ideas earlier than we go layer by layer:
- Readiness shouldn’t be the identical as visibility: Robust construction doesn’t assure being surfaced.
- Visibility shouldn’t be the identical as influence: Being talked about doesn’t assure business worth.
- Platforms and surfaces ought to normally be tracked individually: don’t mix Google AI Overviews and AI Mode, and don’t routinely mix ChatGPT, Perplexity, Gemini, Claude, or Copilot both. The interfaces, supply habits, hyperlink therapy, and measurement visibility differ sufficient that mixing can conceal helpful sign.
- Not all prompts matter equally: Business, comparative, and shortlist prompts will have a tendency to hold extra weight than generic instructional queries.
- Not all metrics deserve the identical confidence: Noticed, proxy, and modelled indicators ought to stay separate and labelled.
- Measurement ought to result in motion: If a metric can’t change a call, it shouldn’t be on the dashboard.
Let’s undergo every layer.
Layer 1. Presence: Is the model really showing, and the way?
Presence solutions essentially the most speedy query: is the model really showing within the AI solutions that matter, and the way is it being represented when it does?
With out this layer, groups run broad audits and ship generic optimizations with out understanding what’s really suppressing visibility. Presence is the place the weak point turns into seen, by platform, immediate group, persona, product line, market, or supply ecosystem.
How you can arrange your AI presence measuring protocol
Begin slender and deliberate. The objective is a measuring protocol centered on business worth and motion, not a large immediate library that’s not consultant and significant:
- Prioritize the highest 2 – 3 AI platforms primarily based on a mixture of measurable AI referral visitors in your vertical, viewers utilization, and business relevance. Moreover making an allowance for your personal website’s observable AI visitors, you need to use instruments like Similarweb, Semrush, and related platforms to estimate which AI platforms look like driving extra visitors in your sector and competitor set.
- Create immediate libraries that replicate the constraints actual consumers really use in AI platforms, not conventional search key phrases stretched into prompts.
- Prioritize evaluation round excessive business intent and excessive affect immediate teams. Discovery prompts matter, however shortlist and choice prompts are the place offers are gained or misplaced.
- Search for patterns over time, not single-run outcomes, as a result of AI outputs fluctuate by session and platform. A single run is an anecdote; a pattern is a sign.
- Translate every visibility hole into a probable readiness prognosis: so Layer 1 fingers off on to Layer 2 fairly than producing a scorecard that simply sits there.
Construct immediate libraries that replicate actual purchaser habits
The commonest immediate library errors I see appear to be this:
- Treating prompts like key phrases with out context.
- Solely monitoring “finest X” prompts.
- Monitoring too few prompts to get a secure learn.
- Not monitoring every market, language, product line, stage of buyer journey and persona individually.
A poorly consultant immediate library distorts what you measure and produces work that doesn’t drive worth. A superb one displays how consumers really uncover, examine, validate, and select, not what a key phrase instrument surfaces.
The place to supply prompts from:
- Non-brand demand knowledge.
- Gross sales name transcripts and help conversations.
- Opinions and group language (Reddit, Slack teams, business boards).
- AI analysis instruments’ pattern knowledge (Profound, Semrush).
- Similarweb immediate and AI visitors samples in your website and rivals, the place out there.
- Bing Webmaster Instruments AI Efficiency report knowledge, together with citations, cited pages, and sampled grounding queries throughout supported Microsoft AI experiences.
- Your prime ranked underperforming long-tail queries from Google Search Console.
Then group them by goal market/language, services or products line, buyer journey stage, viewers/persona, and purchaser constraint, and add real looking persona, product-line, market, and constraint variants.
Use constraints actual consumers really use in your prompts
That is the half most immediate libraries miss. For instance, actual AI prompts in B2B and client classes carry particular purchaser constraints and in case your immediate set doesn’t, you’re measuring a model of the market that doesn’t exist.
| Constraint dimension | Examples |
|---|---|
| Worth band | free, beneath $X, enterprise |
| Staff or firm dimension | freelancer, small workforce, mid-market, enterprise |
| Trade or vertical | B2B SaaS, ecommerce, healthcare, monetary companies |
| Integration wants | instruments the client already makes use of (Slack, HubSpot, Salesforce, and so forth.) |
| Geography and market | nation, area, language |
| Use case or job-to-be-done | the particular downside being solved |
| Compliance or belief necessities | SOC 2, GDPR, HIPAA, business certifications |
Now apply these constraints throughout every product line, persona, and journey stage. Right here’s the way it seems for Finchling:
| Stage | Persona | Key constraints | Instance immediate |
|---|---|---|---|
| High of funnel | PR companies | Staff dimension, shopper depend, business focus, integration wants, worth band | “What are the most effective PR alternative instruments for a 10-person digital PR company managing 15 B2B tech purchasers that wants Slack integration?” |
| High of funnel | In-house PR groups | Firm dimension, business, geography, integration, compliance | “Which instruments assist an in-house PR workforce at a healthcare firm discover well timed media alternatives whereas supporting stricter compliance wants?” |
| Mid funnel | PR companies | Staff dimension, vertical, integration, price range, workflow | “Finchling vs Google Alerts for a small PR company managing a number of B2B SaaS purchasers: which is healthier for locating related alternatives quicker?” |
| Mid funnel | In-house PR groups | Trade, firm dimension, geography, workflow, belief | “What’s the finest PR instrument for an in-house communications workforce that wants reliable, related story alternatives for a mid-market SaaS model in Europe?” |
| and so forth … | … | … | … |
High of funnel prompts are class discovery and broad answer prompts. Mid funnel prompts are comparative, analysis, use-case, and belief prompts. Each tracked individually.
Apply immediate pragmatic sampling, not exhaustive protection
When you add constraints throughout personas, product traces, and buyer journey levels, the immediate set expands quick. Don’t attempt to cowl every part, prioritize highest worth combos and doc what you’re not monitoring so gaps are specific.
| Model profile | Tough library dimension |
|---|---|
| Single product, unfastened persona segmentation | 30–60 prompts throughout key journey levels with a small set of high-priority constraints |
| Single product, sturdy persona segmentation | 50–100 prompts throughout personas, journey levels, and chosen purchaser constraints |
| Multi-product or multi-service model | 100–250+ prompts segmented by line, persona, stage, and prioritized constraints |
| Enterprise or holdco with a number of verticals | 250+ prompts throughout a number of traces, personas, markets, levels, and constraints |
It’s vital to group prompts by matters to trace and assess your visibility share at a topical degree, not on the particular person immediate degree. AI outputs are dynamic. Matter-level aggregation is what offers you a dependable trendline.
The 5 Presence KPIs you want
As soon as your immediate set is prepared, measure your AI presence utilizing these 5 core Presence KPIs.
They’re the minimal as a result of each solutions a special key query to know your model AI search presence. You possibly can calculate a few of them immediately in immediate monitoring instruments, however others require a customized scoring framework or outlined guide assessment protocol.
| KPI | Query it solutions | How you can calculate |
|---|---|---|
| 1. Immediate protection | Are we displaying up the place we have to? | (Tracked prompts the place the model seems ÷ Complete tracked prompts) × 100 |
| 2. Advice fee | Are we being endorsed, or simply included? | (Appearances the place the AI explicitly recommends the model ÷ Prompts the place the model seems) × 100 |
| 3. Linked quotation fee | On platforms and immediate varieties the place hyperlinks are surfaced, is the visibility able to driving visits or purchases? | (Appearances with a clickable hyperlink to the model ÷ Prompts the place the model seems) × 100 |
| 4. Comparative win fee | Are we successful the shortlist when customers examine choices? | (Comparability prompts the place the model is the popular choice ÷ Comparability prompts the place the model seems towards rivals) × 100 |
| 5. Illustration accuracy | Are we being understood correctly, or misrepresented? | (Appearances with factually right positioning ÷ Prompts the place the model seems) × 100 |
Methodology be aware: not each KPI on this framework is equally goal. Some are immediately measurable from platform or analytics knowledge; others require a documented scoring protocol, repeated sampling, and human assessment. Deal with advice fee, comparative win fee, and illustration accuracy as structured choice help metrics fairly than platform native floor fact. Report them individually and label confidence clearly.
For any scored KPI, doc the rubric, pattern dimension, assessment cadence, and whether or not the outputs have been assessed by one reviewer or calibrated throughout a number of reviewers.
Right here’s an instance of how they work:
- Immediate protection: For those who monitor 100 related prompts and the model seems in 42, immediate protection = 42%.
- Advice fee: Out of 40 prompts the place the model seems, the AI explicitly recommends it in 18, advice fee = 45%.
- Linked quotation fee: The model seems in 30 solutions, and in 12 the AI features a clickable hyperlink to the location, linked quotation fee = 40%.
- Comparative win fee: Throughout 20 comparability prompts like “What’s higher for digital PR groups, Finchling or Google Alerts?”, the AI favors Finchling in 11 responses, comparative win fee = 55%.
- Illustration accuracy: The AI mentions Finchling in 25 solutions with 20 of them being correct (platform for reactive and proactive PR alternatives), 5 incorrect (generic media monitoring instrument), illustration accuracy = 80%.
Measured on their very own, every quantity is fascinating. Learn collectively, they’re a prognosis.
Which presence KPIs ought to lead your dashboard? It depends upon what you are promoting mannequin
Not each enterprise ought to lead with the identical metric. The identical visibility hole has a special business that means for a writer than for a SaaS platform than for an ecommerce model.
- Transactional websites (ecommerce, marketplaces, bookings): Typically lead with linked quotation fee and comparative win fee, particularly on platforms and immediate varieties the place hyperlinks are surfaced clearly sufficient to help click-out habits. Income depends upon click-capable mentions and successful selection-stage prompts like “finest trainers beneath $150” or “least expensive flights to Lisbon”.
- Lead gen and repair websites (companies, native companies, consultancies): Lead with advice fee and comparative win fee. The customer journey is consultative: being actively endorsed for provider-selection prompts like “finest PR companies for SaaS” is the sign that issues.
- SaaS and product-led companies: Lead with advice fee, comparative win fee, and illustration accuracy. Crowded, comparison-heavy classes the place being framed appropriately is as vital as being surfaced.
- Publications and media websites: Lead with linked quotation fee and immediate protection. The enterprise mannequin depends upon referral visitors and being handled as an authoritative supply.
- Informational, instructional, or nonprofit websites: Lead with immediate protection and illustration accuracy. Success is being reliably surfaced for the appropriate matters with the appropriate data.
For those who’re not sure which KPI ought to lead, ask your self these questions:
- Does income require a click on, or can worth be created by the AI point out alone?
- Is the class comparability heavy, or discovery heavy?
- Are business and choice stage prompts the place the cash is, or do informational and discovery prompts drive many of the pipeline?
- Is the model offered immediately on-site, by way of companions, by way of marketplaces, or offline; and subsequently how a lot does linked quotation fee really matter?
- Is being described appropriately commercially important, or is any point out a web optimistic?
- Which metric, if it moved by 20% subsequent quarter, would most plausibly change the enterprise consequence: classes, pipeline, income, recall, or authority?
That final query is the one which issues most.
The metric that solutions “sure, shifting this might change the enterprise consequence” is the one which belongs on the prime of your dashboard. Every thing else is secondary.
Construct the AI search presence dashboard and use it to reply actual questions
You possibly can construct your personal Presence dashboard utilizing AI monitoring platforms similar to Similarweb, Profound, Peec AI, Semrush, Sistrix, Waikay, or your personal inner monitoring setup. Select primarily based on which platforms, prompts, exports, quotation knowledge, and scoring workflows they really help, since instrument protection and methodology differ.
What issues isn’t the instrument. What issues is whether or not the dashboard solutions these questions:
- The place does the model seem, and the place is it silent? Which platforms, journey levels, personas, product traces, or markets present the widest gaps?
- When the model seems, is it genuinely really useful or merely listed amongst alternate options?
- Are mentions click-capable, or do they keep trapped contained in the AI reply with no hyperlink?
- In head-to-head or shortlist prompts, does the model win, tie, or lose — and towards whom persistently?
- Is the model being described precisely, or is it misframed, outdated, or confused with one other product?
- Which third-party domains form the outcomes, and the place is the supply ecosystem working towards the model?
And every presence KPI ought to map to a particular motion:
| KPI | How you can report | What to be taught / motion |
|---|---|---|
| 1. Immediate protection | Month-to-month, segmented by platform, stage, persona, product line, market | Low values level to visibility or distribution gaps |
| 2. Advice fee | Month-to-month with competitor benchmark | Low values level to belief, corroboration, or differentiation gaps |
| 3. Linked quotation fee | Month-to-month by platform and immediate group | Low values level to extractability or web page construction gaps |
| 4. Comparative win fee | Month-to-month vs. 3 to five key rivals | Low values level to positioning or proof gaps |
| 5. Illustration accuracy | Month-to-month, with examples of misrepresentation | Low values level to entity readability or consistency points |
That final column is the handoff to Layer 2.
AI search presence stops being a report the second every weak metric maps to a structural speculation to check.
Layer 2. Readiness: Are you structurally ready to be surfaced?
Readiness explains the structural causes behind the visibility patterns surfaced in Layer 1 and identifies which points are most certainly limiting stronger AI search efficiency.
With out this layer, groups reply to visibility gaps with generic content material or technical work that doesn’t deal with the actual bottleneck. Readiness turns Presence findings into structural priorities that may really transfer the needle.
Begin from Presence findings, not from a clean audit
The primary rule of Readiness evaluation: don’t run a blanket audit. Begin from the particular patterns Layer 1 surfaced.
- Mentions with out hyperlinks usually level to Accessible, Extractable, or Recent gaps.
- Weak class visibility usually factors to Corroborated, Differentiated, or Helpful gaps.
- Weak advice fee usually factors to Credible, Corroborated, or Differentiated gaps.
- Poor illustration accuracy usually factors to Recognizable or Constant gaps.
- Weak business visibility usually factors to Transactable, Extractable, or Helpful gaps.
For this reason Layer 1 fingers off to Layer 2: You’re not auditing every part, you’re testing the structural hypotheses Presence surfaced.
The ten traits of AI search successful manufacturers
The ten traits I’ve recognized for AI search successful manufacturers on this information are your Readiness dimensions. They are often scored and tracked over time as diagnostic measures.
| Attribute | Core query to evaluate |
|---|---|
| Accessible | Can the related pages be reached, rendered, listed, and fetched reliably by the techniques that make them eligible to seem in search and AI mediated search experiences? |
| Extractable | Are key solutions, positioning, and differentiators simple to parse and summarize from the web page? |
| Helpful | Does the content material resolve the consumer want competitively — higher than what else is on the primary web page of AI solutions? |
| Recent | Is the content material latest sufficient (publish/replace dates, present info, reside pricing) to stay credible and citable? |
| Differentiated | Is the positioning clear, particular, and ownable — or is the language interchangeable with rivals? |
| Recognizable | Are model and entity indicators specific (title, class, founder, HQ, funding, product traces) and machine-readable? |
| Constant | Do these entity indicators match throughout website, Wikipedia/Wikidata, LinkedIn, assessment websites, and press? |
| Corroborated | Do a number of impartial third-party sources reinforce the identical positioning and claims? |
| Credible | Do the sources that reinforce the model carry weight (acknowledged publications, analyst protection, peer-reviewed or main knowledge)? |
| Transactable | Are pricing, plan logic, characteristic comparisons, and analysis surfaces clear sufficient that AI techniques can reply “which plan suits my case” questions? |
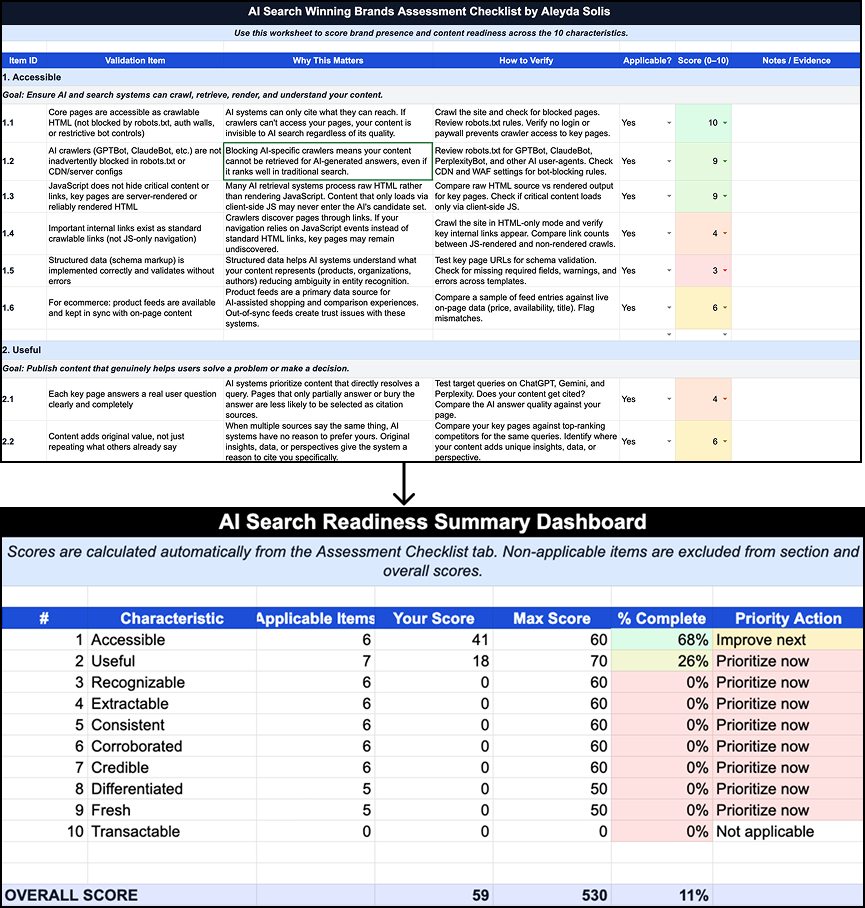
I’ve revealed a fuller AI Search Readiness Guidelines protecting every attribute, why it issues, how you can confirm it, and which instruments might help assess it. You need to use that as your audit reference fairly than reinventing one.
Tie the AI search readiness audit to the visibility hole
The AI search readiness audit turns into helpful if you focus it on the traits most certainly to clarify your Presence sample. For reporting, group the ten traits into 5 themes, as they share root causes and have a tendency to maneuver collectively.
| Theme | When to prioritize | How you can report | What to be taught / motion |
|---|---|---|---|
| Accessible | Content material seems exhausting to fetch or pages are lacking from cited outcomes | Quarterly, with proof and proprietor | Crawl, fetch, rendering, or entry limitations suppressing visibility |
| Extractable | Model is talked about however not often linked or summarized cleanly | Quarterly, tied to key touchdown pages | Content material exhausting for AI techniques to parse, summarize, or cite |
| Helpful / Recent / Differentiated | Class visibility or advice is weak | Quarterly by precedence phase | Content material doesn’t resolve the query properly sufficient, is stale, or lacks clear positioning |
| Recognizable / Constant | Model is misdescribed or inconsistently framed | Quarterly with examples | Entity readability and message consistency issues throughout surfaces |
| Corroborated / Credible / Transactable | Belief, shortlist, and business prompts are weak | Quarterly, linked to supply ecosystem and business pages | Typically clarify weak advice, weak comparability, and weak business visibility |
Use your Presence knowledge to focus the evaluation on the websites which are really influencing your visibility. Instruments like Profound, Similarweb and Semrush floor which third-party domains AI techniques cite in your prompts. That’s the place your corroboration work ought to go, not a generic “get extra mentions” program.
An AI search readiness evaluation consequence instance
Say your Presence dashboard exhibits the model seems in 70% of “finest PM instruments for engineering” prompts however in solely 12% of “[brand] vs rivals” head-to-head prompts, and in that 12% it’s framed as “a more moderen different” fairly than on its precise differentiators.
That’s not a distribution downside since visibility exists upstream. It’s a Differentiated + Corroborated + Credible hole.
The model is surfaceable however not positioned strongly sufficient within the third-party sources AI platforms weigh on the comparability stage. So Layer 2 work ought to give attention to comparison-site pages, analyst protection, and positioning consistency throughout G2/Capterra/assessment websites.
Prioritize with effort, not simply influence
When you document the evaluation consequence rating, proof, affected phase, proprietor, effort, and sure impact on Stage 1 KPIs for every hole, you possibly can then prioritize utilizing:
Probably influence on key visibility hole × business significance ÷ ease of implementation
The trouble denominator is what makes the roadmap real looking:
- An outdated pricing web page inflicting Transactable failures on “least expensive PM instrument” prompts ought to ship this week.
- A weak analyst protection program decreasing Credible sign on shortlist prompts ought to get funded and deliberate over 6-12 months, however it doesn’t block short-term wins.
That’s how you find yourself with roadmaps that by no means ship.
Layer 3. Enterprise Impression: Is AI visibility translating into worth?
The objective of this layer shouldn’t be excellent attribution. It’s an trustworthy reporting mannequin to help price range, planning, and prioritization selections with out over-claiming.
No present measurement stack delivers full, clear AI search attribution throughout platforms, surfaces, and journeys.
Google and Microsoft now present partial, however nonetheless incomplete, visibility into AI search habits. Google paperwork that AI Overviews and AI Mode are included inside Search Console’s total Net Efficiency reporting fairly than damaged out as separate standalone stories. Microsoft now supplies AI Efficiency reporting in Bing Webmaster Instruments public preview with quotation counts, cited pages, and sampled grounding queries.
What this layer delivers is a layered studying of noticed knowledge, directional proxies, and modelled estimates: stored separate, labelled by confidence, and reviewed on a cadence the enterprise can act on.
If I may put one sentence in entrance of each CFO on this:
Measured AI referral visitors is the ground, not the ceiling, of AI’s contribution. In different phrases, noticed AI-referred classes are a measurable subset of AI affect, not a whole measure of it.
A big share of AI influenced conversions return by way of branded search or direct visitors after a consumer noticed the model in an AI reply and didn’t click on. Reporting solely noticed AI referral classes systematically understates influence.
That’s not an excuse, it’s a design constraint, and the three-layer confidence mannequin under is the way you report round it truthfully.
4 Enterprise Impression confidence layers that shouldn’t be blended
The only most typical reporting failure in AI search measurement is collapsing direct proof, directional proxies, and modelled estimates into one undifferentiated “AI influence” quantity. As soon as these layers blur collectively, a CFO asks one query about methodology and the entire assemble falls aside.
Label each metric in your dashboard with its confidence layer:
| Enterprise Impression Layer | What it’s | Query it solutions |
|---|---|---|
| Noticed | Metrics from platforms passing a referrer or UTM. Highest confidence, lowest protection. E.g. AI-referred classes, AI conversion fee, income per AI go to, AI-assisted conversions. |
What number of customers clicked and transformed from an AI reply? |
| Proxy: personal | Directional indicators from your personal analytics. Medium confidence, broader protection. E.g. branded search raise, direct/unattributed raise, demand for cited pages, survey-based discovery. |
Is there proof customers are seeing us in AI solutions even once they don’t click on? |
| Proxy: third-party | Exterior knowledge from instruments that pattern or mannequin AI visitors throughout the online. Medium-to-low confidence, however the one window onto rivals and prompt-level habits. E.g. Similarweb AI visitors habits vs. rivals, immediate samples per web page. |
How does our AI presence examine to rivals and which prompts are driving AI visitors? |
| Modelled | Estimates from making use of assumptions to noticed and proxy knowledge. Lowest confidence. E.g. influenced pipeline, influenced income. |
If we assume X% of branded search raise is AI attributable, what’s the implied pipeline? |
Every layer solutions a special query. Treating them as one quantity makes all 4 much less helpful, no more.
What this seems like in apply: a Finchling month-to-month report:
- Noticed: 1,820 AI-referred classes, 6.1% trial begin fee, 2.4x the natural benchmark.
- Proxy – personal: Branded “Finchling” search +22% QoQ; direct visitors to /options/reactive-pr +38% QoQ.
- Proxy – third get together: Similarweb estimates roughly 4,200 AI classes for the interval, versus 1,820 noticed in GA4; inside the PR instruments peer set, estimated AI visitors share is 6% for Finchling versus 41% for Muck Rack and 22% for Prowly.
- Modelled: Based mostly on estimated incremental branded demand above baseline for the quarter, a 30% AI affect assumption, and historic branded search to pipeline conversion charges, estimated influenced pipeline ~€14K ARR. Caveat band connected.
It’s vital to notice how every line is reported individually with its confidence label, and by no means collapsed right into a single “AI influence” determine.
Construct the enterprise influence noticed layer
The noticed layer begins in your net analytics stack and, the place attainable, extends by way of to CRM or downstream income reporting. The setup itself is manageable, however it isn’t enabled by default, and it loses usefulness shortly if no person maintains the monitoring guidelines, channel definitions, and reporting logic over time.
For those who’re setting this up in GA4, Dana DiTomaso’s guides on How you can Monitor and Report on Visitors from AI Instruments and AI Visitors Evaluation: Constructing GA4 Audiences That Drive Selections are sturdy sensible references to start out.
In GA4, the cleanest strategy is to create a devoted customized channel group for AI visitors.
Go to Admin → Knowledge show → Channel teams → Create new, duplicate your current grouping, and add a channel similar to AI Search or AI Assistants utilizing a Supply matches regex rule. Google explicitly paperwork utilizing a GA4 customized channel group with regex-based guidelines to group AI assistant visitors for reporting.
The channel order issues. GA4 consists of visitors within the first channel whose definition it matches, so an AI assistants channel ought to sit above Referral and any broader matching guidelines. If Referral seems first, eligible AI visitors could also be labeled there earlier than your customized AI rule ever fires.
For the regex, use a maintained starter sample, not a set “last” checklist. Google’s documentation supplies an instance regex for AI assistants, however your model must be up to date over time primarily based on the precise referrers and URL patterns your property receives.
A sensible model can embrace platforms similar to ChatGPT, Perplexity, Claude, Gemini, Copilot, DeepSeek, Grok, You.com, Phind, and Mistral, however the precise protection will rely upon the referrers and URL patterns your personal property is definitely receiving. Google’s instance makes use of broader sample matching fairly than relying solely on a slender set of actual hosts.
What this layer captures properly:
- Visitors from AI platforms that move a usable referrer or supply parameter could be measured immediately in GA4 by way of the customized channel group.
- Some AI platforms are extra observable than others in GA4 as a result of referrer habits varies by product, browser, app handoff, and click on path. Deal with platform-level observability as variable, not assured.
What this layer doesn’t seize cleanly:
- Some AI pushed visits will nonetheless collapse into Direct, Referral, or different channels due to app handoffs, copied URLs, privateness controls, or lacking referrer knowledge. So the noticed layer is beneficial, however incomplete by definition.
- Google AI Overviews and AI Mode should not cleanly uncovered in GA4 as their very own native standalone visitors supply. Google paperwork that AI Overviews and AI Mode are included in Search Console’s total search outcomes efficiency reporting, however that also doesn’t make them cleanly separable as a definite visitors supply in GA4.
What to trace within the noticed layer:
- AI Periods by platform, touchdown web page, system.
- Engagement fee and common engagement time versus the natural benchmark. Google has stated that clicks from search outcomes pages with AI options could be larger high quality, for instance by customers spending extra time on website, however that must be validated towards your personal benchmarks fairly than assumed throughout all platforms or experiences. If it persistently underperforms your benchmark, that may point out a touchdown web page mismatch, weak immediate match, or lower-quality visibility than anticipated.
- AI conversion fee and income per go to, segmented by platform the place quantity permits.
- AI assisted conversions (data-driven attribution in GA4, or multi-touch within the CRM).
- High AI touchdown pages: The pages which are really being cited. This checklist is probably going essentially the most helpful perception for informing Layer 2 work.
Add enterprise influence proxy indicators and interpret them collectively
The noticed layer is the ground. Proxy indicators fill in among the ceiling.
None of those metrics show AI affect on their very own. The worth comes from studying them as a set and asking whether or not the sample is in line with an AI pushed story:
- Personal-site proxies have larger belief however are inward-looking.
- Third-party instruments indicators have decrease belief however are the one window onto rivals and prompt-level habits.
You want each.
Personal website proxy indicators to trace
Right here’s an inventory of key “Personal proxy” enterprise influence indicators to trace:
| Sign | How you can seize |
|---|---|
| Branded search pattern | GSC question report filtered to model phrases, or the native branded/non-branded toggle. Monitor WoW and MoM. |
| Direct and unattributed visitors pattern | GA4 Direct and different unattributed visitors, particularly to pages not actively being pushed by way of e-mail, paid, or different identified campaigns. Deal with this as a weak corroborative proxy solely, since GA4 direct means visitors with no clear referral supply. |
| Demand for frequently-surfaced pages | Impressions and direct/natural visitors to pages you’ve verified are cited in AI solutions. |
| Survey primarily based discovery | One query added to signup, demo, or post-purchase flows. |
| Bing Webmaster Instruments AI Efficiency | First-party quotation counts, cited URLs, and grounding queries for Copilot and Bing AI. At present the clearest first-party quotation reporting publicly out there from a serious AI search ecosystem. |
| Social listening on model mentions | Reddit, LinkedIn, Slack communities the place “has anybody used X?” conversations occur. |
An vital, simple to set survey primarily based discovery proxy sign
There’s one survey query that earns its place and I like to recommend to add to your signup circulation, demo request, or post-trial onboarding:
“Earlier than signing up, did you come throughout [brand] in an AI assistant or AI search expertise, similar to ChatGPT, Perplexity, Claude, Gemini, Copilot, or Google’s AI options?”
Choices: Sure / No / Unsure.
Place it after the core signup fields, not earlier than. Elective. One query, no follow-up (the second it turns into a mini-survey, completion charges collapse and also you need to keep away from that).
Why it issues disproportionately: a rising “Sure” fee amongst customers attributed to Direct or Branded Natural is likely one of the strongest first-party proxies that AI affect exists past what analytics can immediately observe.
- Customers who arrive by way of branded search with a excessive “Sure” fee are the invisible AI affect. They’re attributed to Natural in GA4 however wouldn’t have searched the model with out an AI point out.
- Customers who arrive by way of Direct with a excessive “Sure” fee are the mobile-ChatGPT copy-paste cohort. GA4 attribution is solely blind to them.
- Customers who arrive by way of the AI Search channel itself however reply “No” could embrace misattributed visitors: company visitors, inner workforce members, secondary clicks.
Third-party proxy reads price working month-to-month
Similarweb, Semrush and equal instruments can fill gaps your personal analytics can’t cowl immediately, though imperfectly. Knowledge comes from panels, clickstream samples, and modelling, not out of your logs. Use them for relative reads (us vs. rivals, this month vs. final, immediate A vs. immediate B) fairly than absolute claims.
Listed below are 3 particular reads to run month-to-month:
1. Immediate samples driving visitors to your prime AI touchdown pages.
Similarweb surfaces a pattern of the prompts that produced AI referred visits to particular URLs. Use it to increase your Presence immediate set, diagnose touchdown web page mismatch, and inform Readiness work.
2. Aggressive benchmarking of AI visitors share, prime touchdown pages, and prime prompts per web page.
Monitor your estimated share of AI-referred classes throughout an outlined peer set over time. A rising share is normally a optimistic sign; a flat share throughout class development could point out relative loss. Establish which pages each competitor is getting AI visitors to (commodity pages) and that are distinctively yours (your moat).
3. AI platform combine over time, benchmarked.
Spot platform particular decay (your ChatGPT share flat whereas a competitor’s doubles), platform particular wins (your Perplexity share disproportionately excessive, reverse-engineer what earned it), and class shifts (the entire competitor set shedding ChatGPT share whereas AI Mode rises).
Studying the proxies collectively: three frequent patterns
Proxies solely change into helpful when interpreted as a sample. Listed below are 3 readings that come up usually:
State of affairs A: Hidden success.
AI referral classes flat. Branded search +18%. Direct +9%. Survey “how did you hear about us” exhibits rising AI mentions. Third-party AI visitors share rising relative to friends.
- Studying: visibility is working; customers see the model in AI solutions however arrive by way of model title or direct. Impression is actual however hidden. Most typical sample for established manufacturers.
- Transfer: maintain investing, and lean on survey knowledge, branded search proof, and aggressive share in reporting fairly than noticed classes alone.
State of affairs B: Visitors with out match.
AI referral classes up. Branded search flat. Conversion fee from AI under natural benchmark. Third-party immediate samples present prompts driving visitors to pages not constructed for these prompts.
- Studying: visitors is arriving however not certified. Probably advice high quality or touchdown web page mismatch.
- Transfer: audit the sampled prompts towards their touchdown pages, and both redirect cited URLs to extra particular pages or rewrite pages to match intent. Most fixable of the three and infrequently the quickest QoQ enchancment.
State of affairs C: Clear case.
AI referral classes up. Branded search up. AI-assisted conversions seen. Survey sign rising. Third-party share up, platform combine diversifying.
- Studying: noticed, own-proxy, and third-party indicators all level in the identical route. That is in line with share achieve fairly than merely benefiting from class development.
- Transfer: scale funding, broaden immediate protection to adjoining clusters, and maintain testing the estimate towards future survey, branded-demand, and noticed conversion developments.
Construct the enterprise influence modelled layer
The noticed layer measures what you possibly can see. The proxy layer indicators what you possibly can infer. The modelled layer estimates what you possibly can’t measure immediately however should want a planning quantity for, usually when management asks “what’s AI search really price to us?” and noticed classes alone understate the reply.
Modelled metrics aren’t a substitute for noticed and proxy knowledge. They’re a principled manner of mixing them right into a planning quantity. The rigor comes from making the assumptions specific, preserving the boldness band broad, and by no means presenting the output as proof.
The baseline modelled estimate
The best model applies an assumption to a proxy sign:
(Incremental branded clicks, visits, leads, or pipeline above baseline) × (said AI affect assumption %) = modelled influenced worth
For instance, utilized to Finchling: first estimate the incremental branded demand above baseline for the quarter, then apply a 30% AI affect assumption to that increment, then translate that influenced share into ARR utilizing historic branded-search-to-pipeline or branded-search-to-ARR charges. That yields the modelled influenced pipeline vary.
Inputs to mix:
- Branded search raise from GSC: the clearest proxy most manufacturers can have.
- Direct visitors raise to cited pages: helpful the place cell to direct AI journeys are frequent.
- Survey AI discovery fee: usually the strongest first-party anchor for the AI affect assumption, as a result of it grounds the estimate in noticed consumer reported habits.
- Historic conversion worth per go to or lead: to translate classes into business phrases.
How to decide on and justify the attribution assumption:
- Begin from the survey “Sure” fee amongst customers arriving by way of branded search or direct. If roughly 30% of related new signups report seeing the model in an AI assistant, that can be utilized as an inexpensive beginning assumption, offered the pattern dimension, response fee, and wording are secure sufficient to match over time.
- Cross-check towards third-party AI visitors share. If branded search, survey-based AI discovery, and exterior AI visitors indicators rise collectively, confidence within the assumption will increase. In the event that they diverge, confidence decreases and the estimate must be discounted.
- Doc what you excluded. Product launches, paid campaigns, or PR moments in the identical window ought to come off the highest.
How you can report it:
- All the time as a variety, by no means a single quantity.
- All the time with the said attribution assumption, inputs, exclusions, and timeframe clearly documented.
- All the time under the noticed and proxy numbers within the dashboard, not above them.
A reportable line seems like:
“Modelled influenced pipeline for Q1: €12–16K ARR, primarily based on an estimated increment in branded demand above baseline for the quarter, a 30% AI-influence assumption utilized to that increment, and historic branded-search-to-pipeline conversion charges, cross-checked towards rising survey discovery fee (27% → 34%) and secure third-party AI share.”
What the modelled layer captures properly
- A planning quantity that accounts for AI affect invisible to noticed monitoring.
- A option to translate directional proxy indicators into business phrases management can use for price range conversations.
- A disciplined different to both ignoring AI affect as a result of it could’t be measured cleanly, or overclaiming it by crediting AI for each branded search raise.
What the modelled layer doesn’t seize cleanly
- A modelled estimate must be handled as a planning assemble, not as attributed income.
- Platform-specific attribution. The idea applies throughout AI search as an entire.
- Brief-term actions. Modelled estimates stabilize over quarters, not weeks.
What to trace
- Modelled influenced pipeline or income, said as a variety with inputs documented.
- Attribution proportion utilized over time, tracked alongside survey discovery fee so the 2 transfer collectively.
- Sensitivity band: What the quantity seems like at ±10 proportion factors of attribution %, so management sees how a lot depends upon the idea.
Refresh quarterly, not month-to-month: The inputs are too noisy under that cadence. Re-validate the attribution proportion each two quarters towards the survey response fee, and retire the estimate solely if the inputs change into unreliable. A modelled quantity constructed on a damaged enter is worse than no quantity in any respect.
One thing to remind: that is for planning, by no means for proof.
The second it will get cited as a defensible attribution determine fairly than a working assumption, it stops being helpful and begins eroding belief in the entire dashboard.
The Enterprise Impression metrics abstract
Right here’s a abstract of the noticed, personal proxy, third get together proxy and modelled enterprise influence metrics shared within the information, and what they inform you:
| Enterprise Impression Metric | Confidence layer | What it tells you |
|---|---|---|
| AI-referred classes | Noticed | Whether or not identified AI visitors is rising or shrinking. The ground, not the ceiling. |
| AI conversion fee / income per go to | Noticed | High quality sign vs. natural benchmark. Beneath-benchmark = landing-page or prompt-match challenge. |
| AI-assisted conversions | Noticed | Whether or not AI contributes to conversion paths even when not the ultimate click on. |
| Branded search / direct / surfaced-page demand | Personal proxy | Detects recall and downstream demand results past measurable referrals. |
| Survey AI discovery fee | Personal proxy | Surfaces AI affect on customers who arrive by way of branded or direct — in any other case invisible. |
| BWT AI Efficiency citations and grounding queries | Personal proxy | Helpful first-party sign for understanding quotation readiness and AI supply visibility throughout Microsoft supported AI experiences. |
| Third-party AI visitors share vs. friends | Third-party proxy | Exhibits whether or not noticed development is share-taking or category-riding. Flat share throughout class development means loss. |
| Third-party immediate samples per prime touchdown web page | Third-party proxy | What query triggered the visitors. Drives prompt-set updates and web page fixes. |
| Third-party AI platform combine vs. peer common | Third-party proxy | Platform-specific dangers and alternatives. Over-indexing on one platform is a fragility sign. |
| Modelled influenced pipeline / income | Modelled | A planning estimate, not attributed proof. Overclaiming right here erodes belief in the entire dashboard. |
Tying the three AI search Presence, Readiness and Enterprise Impression metric layers collectively: the place this turns into strategic
That is the half that issues most: a related prognosis is what drives motion. The matrix under exhibits how the three AI search metric layers could be learn collectively as a single diagnostic:
| Sample | What it normally means | Probably subsequent transfer |
|---|---|---|
| Low readiness + low visibility | Structural situations are holding the model again. Most typical early-stage sample. | Prioritize entry, extractability, entity readability, corroboration. |
| Excessive readiness + low visibility | Model is underdistributed or underrepresented within the supply ecosystem. Widespread for mature manufacturers in crowded classes. | Deal with supply presence, distribution, belief ecosystem, aggressive drawback. |
| Visibility enhancing + influence flat | Model is showing however not memorably, persuasively, or on the appropriate pages. The commercially harmful center state. | Enhance advice high quality, linked citations, memorability, touchdown web page match. |
| Robust informational + weak business visibility | Seen early within the journey however not successful shortlist or choice moments. Traditional SaaS sample at scale. | Enhance business immediate protection and transaction-ready surfaces. |
| Excessive visibility + sturdy advice + weak illustration accuracy | Being talked about however described mistaken. Typically essentially the most commercially damaging sample — actively prices offers. | Entity and supply correction: Wikipedia / Wikidata, schema consistency, assessment websites, analyst briefings. |
| One phase sturdy, one other weak | Problem is segment-specific, not brand-wide. Straightforward to overlook in combination dashboards. | Run a segment-specific readiness and source-ecosystem assessment. |
An instance with Finchling insights
- Base studying:
- Presence dashboard exhibits 58% immediate protection in ChatGPT for discovery prompts however 11% advice fee in shortlist prompts.
- Readiness exhibits Differentiated and Credible scoring properly, however Corroborated scoring low (few third-party critiques, restricted presence on roundup websites).
- Enterprise Impression exhibits flat AI referral visitors and barely rising branded search.
- Matrix learn: “excessive readiness + low visibility” on the business finish of the funnel.
- Prognosis: a lot of the structural work seems to be in place. The bottleneck is supply ecosystem presence on the comparability stage. AI fashions have nowhere to study Finchling within the context of choice prompts as a result of Finchling shouldn’t be within the sources they cite for these prompts.
- Transfer: There must be a concentrated effort on getting Finchling onto software program roundup pages, G2 and Capterra class pages, and reactive PR instrument comparisons. No more content material. No more technical optimization. The lever on this case is exterior corroboration.
That’s what tying the layers collectively offers you: focused suggestions and actions to shut the present AI search gaps that may drive enterprise influence.
The place to start out: the three layer framework minimal viable setup
The framework scales to a full enterprise program, however a lean model can usually be made operational in about two weeks.
Week 1: Baseline.
- Outline precedence platforms, rivals, personas, product traces, markets.
- Construct 50-70 precedence prompts throughout Discovery, Analysis, Choice, Publish-purchase.
- Run the primary visibility baseline (5–7 runs per immediate per platform).
- Establish prime cited domains and largest source-ecosystem gaps.
- Outline Layer 1 KPI set and dashboard shell.
Week 2: Join the layers.
- Translate the three largest Layer 1 gaps into Readiness hypotheses.
- Run a focused readiness audit on these hypotheses solely.
- Arrange the GA4 AI referrer channel group.
- Add the one AI discovery query to signup, demo, or post-purchase flows.
- Outline the weekly, month-to-month, quarterly assessment rhythm.
- Assign first actions and house owners.
You need to finish week two with:
- A visibility baseline by platform and stage (one quantity per cell, pattern dimension documented)
- A prime 10 checklist of third-party domains shaping class solutions
- Three Readiness hypotheses with house owners and goal dates
- A functioning AI channel group in GA4
- A reside discovery query in not less than one acquisition circulation
- A scheduled month-to-month assessment with the appropriate three or 4 folks within the room.
The framework scales from right here.
The takeaway
Redefining success metrics for the AI search period means measuring efficiency throughout three layers:
- Presence tells you whether or not and the way the model seems.
- Readiness tells you whether or not the structural situations for stronger visibility are in place.
- Enterprise Impression tells you whether or not that visibility is creating measurable worth.
Measurement in AI search isn’t about extra dashboards. It’s about connecting the place the model seems, why it seems that manner, and whether or not it issues commercially, and being prepared to behave on what that connection reveals.
Groups that run the three layers in isolation usually tend to ship disconnected work. Groups that run them collectively will know which lever to drag subsequent.
Choose your metrics primarily based on enterprise significance. Report them with the appropriate segmentation and confidence degree. Interpret them with the appropriate questions. And act on them by closing the structural, supply, illustration, or conversion gaps they expose.
It’s time to measure AI search in a manner that helps higher selections.











{kind=link}