Alibaba has launched Qwen3-Max, a trillion-parameter Combination-of-Specialists (MoE) mannequin positioned as its most succesful basis mannequin so far, with a direct public on-ramp through Qwen Chat and Alibaba Cloud’s Mannequin Studio API. The launch strikes Qwen’s 2025 cadence from preview to manufacturing and facilities on two variants: Qwen3-Max-Instruct for traditional reasoning/coding duties and Qwen3-Max-Considering for tool-augmented “agentic” workflows.
What’s new on the mannequin stage?
- Scale & structure: Qwen3-Max crosses the 1-trillion-parameter mark with an MoE design (sparse activation per token). Alibaba positions the mannequin as its largest and most succesful so far; public briefings and protection constantly describe it as a 1T-parameter class system fairly than one other mid-scale refresh.
- Coaching/runtime posture: Qwen3-Max makes use of a sparse Combination-of-Specialists design and was pretrained on ~36T tokens (~2× Qwen2.5). The corpus skews towards multilingual, coding, and STEM/reasoning information. Put up-training follows Qwen3’s four-stage recipe: lengthy CoT cold-start → reasoning-focused RL → pondering/non-thinking fusion → general-domain RL. Alibaba confirms >1T parameters for Max; deal with token counts/routing as team-reported till a proper Max tech report is revealed.
- Entry: Qwen Chat showcases the general-purpose UX, whereas Mannequin Studio exposes inference and “pondering mode” toggles (notably,
incremental_output=trueis required for Qwen3 pondering fashions). Mannequin listings and pricing sit beneath Mannequin Studio with regioned availability.
Benchmarks: coding, agentic management, math
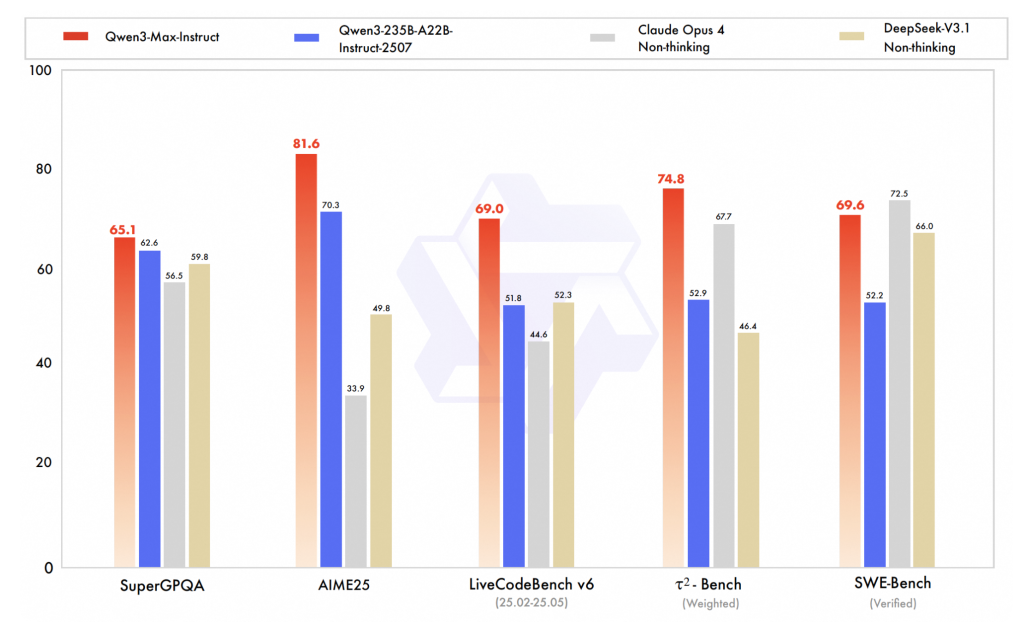
- Coding (SWE-Bench Verified). Qwen3-Max-Instruct is reported at 69.6 on SWE-Bench Verified. That locations it above some non-thinking baselines (e.g., DeepSeek V3.1 non-thinking) and barely under Claude Opus 4 non-thinking in a minimum of one roundup. Deal with these as point-in-time numbers; SWE-Bench evaluations transfer rapidly with harness updates.
- Agentic device use (Tau2-Bench). Qwen3-Max posts 74.8 on Tau2-Bench—an agent/tool-calling analysis—beating named friends in the identical report. Tau2 is designed to check decision-making and gear routing, not simply textual content accuracy, so positive factors listed here are significant for workflow automation.
- Math & superior reasoning (AIME25, and so on.). The Qwen3-Max-Considering observe (with device use and a “heavy” runtime configuration) is described as near-perfect on key math benchmarks (e.g., AIME25) in a number of secondary sources and earlier preview protection. Till an official technical report drops, deal with “100%” claims as vendor-reported or community-replicated, not peer-reviewed.

Why two tracks—Instruct vs. Considering?
Instruct targets standard chat/coding/reasoning with tight latency, whereas Considering permits longer deliberation traces and specific device calls (retrieval, code execution, looking, evaluators), geared toward higher-reliability “agent” use instances. Critically, Alibaba’s API docs formalize the runtime swap: Qwen3 pondering fashions solely function with streaming incremental output enabled; industrial defaults are false, so callers should explicitly set it. It is a small however consequential contract element in the event you’re instrumenting instruments or chain-of-thought-like rollouts.
How you can motive in regards to the positive factors (sign vs. noise)?
- Coding: A 60–70 SWE-Bench Verified rating vary sometimes displays non-trivial repository-level reasoning and patch synthesis beneath analysis harness constraints (e.g., setting setup, flaky exams). In case your workloads hinge on repo-scale code modifications, these deltas matter greater than single-file coding toys.
- Agentic: Tau2-Bench emphasizes multi-tool planning and motion choice. Enhancements right here often translate into fewer brittle hand-crafted insurance policies in manufacturing brokers, supplied your device APIs and execution sandboxes are sturdy.
- Math/verification: “Close to-perfect” math numbers from heavy/thinky modes underscore the worth of prolonged deliberation plus instruments (calculators, validators). Portability of these positive factors to open-ended duties is dependent upon your evaluator design and guardrails.
Abstract
Qwen3-Max will not be a teaser—it’s a deployable 1T-parameter MoE with documented thinking-mode semantics and reproducible entry paths (Qwen Chat, Mannequin Studio). Deal with day-one benchmark wins as directionally sturdy however proceed native evals; the exhausting, verifiable details are scale (≈36T tokens, >1T params) and the API contract for tool-augmented runs (incremental_output=true). For groups constructing coding and agentic programs, that is prepared for hands-on trials and inside gating towards SWE-/Tau2-style suites.
Try the Technical particulars, API and Qwen Chat. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Publication.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.











{kind=link}