Most end-to-end OCR fashions decelerate as output grows. Every generated token provides to the KV cache. Reminiscence rises and era drags. Parsing dozens of pages turns into impractical. Baidu’s Limitless OCR addresses this immediately. It swaps the decoder’s consideration for a design that retains reminiscence fixed.
TL;DR
- Limitless OCR is a 3B-parameter Combination-of-Specialists mannequin, with solely 500M parameters lively.
- It replaces decoder consideration with Reference Sliding Window Consideration (R-SWA), preserving the KV cache fixed.
- The mannequin parses dozens of pages in a single ahead move underneath a 32K most size.
- It scores 93.23 on OmniDocBench v1.5, beating the DeepSeek OCR baseline by 6.22 factors.
- It builds on DeepSeek OCR through continue-training, not a from-scratch run.
What’s Limitless OCR?
Limitless OCR takes DeepSeek OCR as its baseline. It retains the DeepEncoder and the Combination-of-Specialists decoder. The MoE design holds 3B complete parameters however prompts solely 500M at inference.
The DeepEncoder is the compression engine. It cascades a SAM-ViT underneath window consideration with a CLIP-ViT underneath world consideration. On the bridge, it applies 16× token compression. A 1024×1024 PDF picture turns into simply 256 visible tokens. Fewer enter tokens imply a smaller prefill.
DeepEncoder natively helps 5 decision modes, and Limitless OCR retains two. ‘Base’ mode runs at 1024×1024 for multi-page work. ‘Gundam’ mode makes use of dynamic decision for single pages.
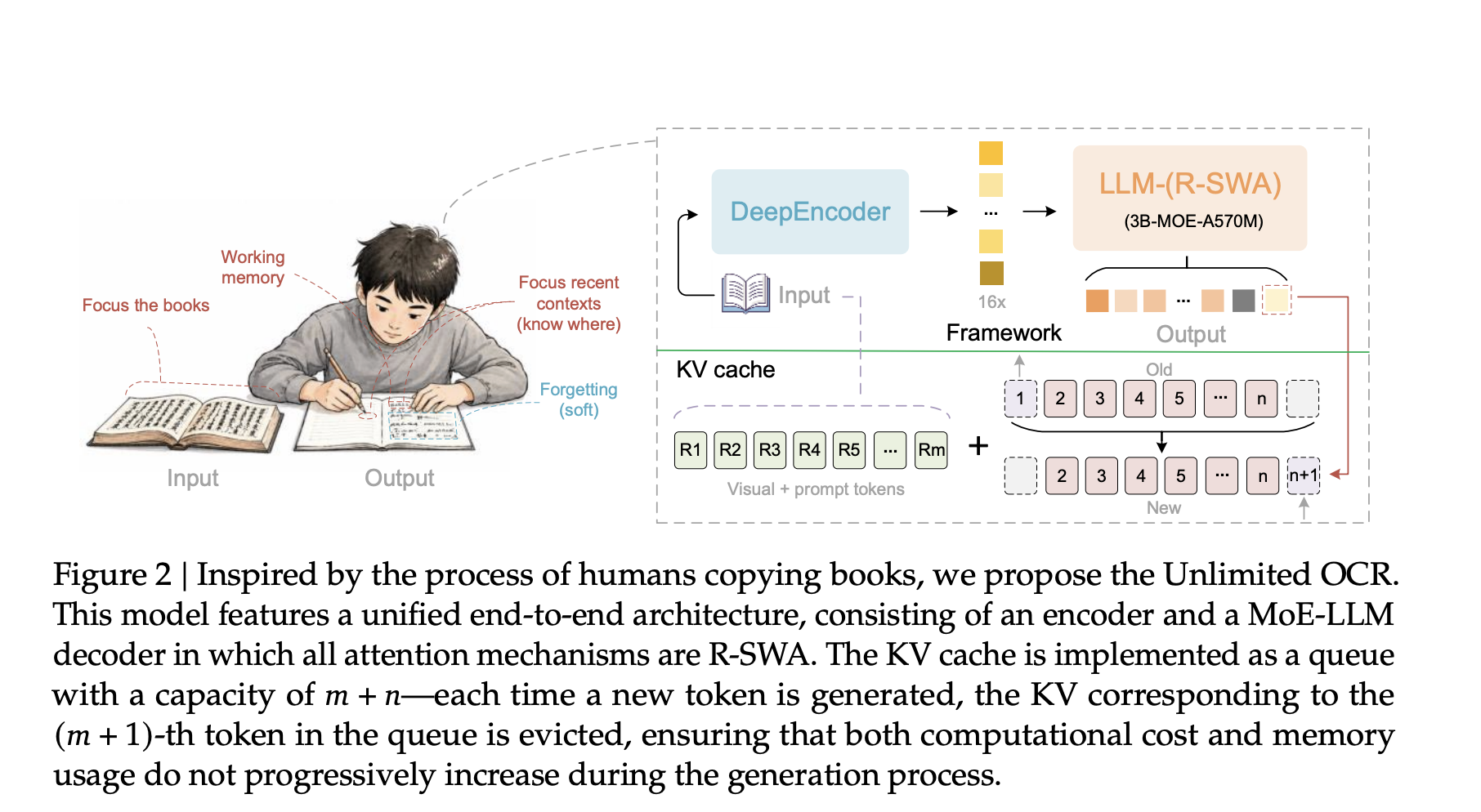
How R-SWA Retains the Cache Fixed
The contribution is Reference Sliding Window Consideration. Customary Multi-Head Consideration shops a key and worth for each token. As output size T grows, the cache grows with it. The scale is CMHA(T) = Lm + T. Reminiscence and latency climb with out certain.
R-SWA breaks that hyperlink. Every generated token attends to all reference tokens, which means the visible tokens and the immediate. It additionally attends to the previous n output tokens, the place n defaults to 128. All the things older is evicted. The cache turns into a set queue of dimension m + n.
The scale is CR-SWA(T) = Lm + min(n, T) ≤ Lm + n. It’s bounded by a continuing. As T grows far past n, the cache ratio traits towards zero. So reminiscence stays flat and per-step latency stays flat.
The analysis staff evaluate this to delicate forgetting. An individual copying a e-book glances on the supply and the previous few phrases. They don’t re-read every thing transcribed to date. Visible tokens by no means endure state updates. That avoids the progressive blurring seen in linear consideration. The interactive simulator under allows you to differ T and watch each caches reply.






![How creators and entrepreneurs are utilizing AI to hurry up & succeed [data]](https://blog.aimactgrow.com/wp-content/uploads/2025/06/Untitled20design-Apr-07-2023-08-24-35-4586-PM-120x86.png)




{kind=link}