On this article, you’ll be taught sensible methods for constructing helpful machine studying options when you might have restricted compute, imperfect information, and little to no engineering help.
Subjects we are going to cowl embody:
- What “low-resource” actually seems like in observe.
- Why light-weight fashions and easy workflows usually outperform complexity in constrained settings.
- Methods to deal with messy and lacking information, plus easy switch studying tips that also work with small datasets.
Let’s get began.

Constructing Sensible Machine Studying in Low-Useful resource Settings
Picture by Creator
Most individuals who need to construct machine studying fashions do not need highly effective servers, pristine information, or a full-stack workforce of engineers. Particularly for those who reside in a rural space and run a small enterprise (or you’re simply beginning out with minimal instruments), you in all probability do not need entry to many sources.
However you possibly can nonetheless construct highly effective, helpful options.
Many significant machine studying tasks occur in locations the place computing energy is proscribed, the web is unreliable, and the “dataset” seems extra like a shoebox stuffed with handwritten notes than a Kaggle competitors. However that’s additionally the place a few of the most intelligent concepts come to life.
Right here, we are going to speak about the best way to make machine studying work in these environments, with classes pulled from real-world tasks, together with some good patterns seen on platforms like StrataScratch.

What Low-Useful resource Actually Means
In abstract, working in a low-resource setting possible seems like this:
- Outdated or sluggish computer systems
- Patchy or no web
- Incomplete or messy information
- A one-person “information workforce” (in all probability you)
These constraints would possibly really feel limiting, however there’s nonetheless a whole lot of potential to your options to be good, environment friendly, and even progressive.
Why Light-weight Machine Studying Is Really a Energy Transfer
The reality is that deep studying will get a whole lot of hype, however in low-resource environments, light-weight fashions are your finest pal. Logistic regression, choice timber, and random forests could sound old-school, however they get the job achieved.
They’re quick. They’re interpretable. They usually run superbly on fundamental {hardware}.
Plus, once you’re constructing instruments for farmers, shopkeepers, or neighborhood staff, readability issues. Individuals must belief your fashions, and easy fashions are simpler to elucidate and perceive.
Frequent wins with traditional fashions:
- Crop classification
- Predicting inventory ranges
- Gear upkeep forecasting
So, don’t chase complexity. Prioritize readability.
Turning Messy Knowledge into Magic: Function Engineering 101
In case your dataset is somewhat (or rather a lot) chaotic, welcome to the membership. Damaged sensors, lacking gross sales logs, handwritten notes… we’ve all been there.
Right here’s how one can extract which means from messy inputs:
1. Temporal Options
Even inconsistent timestamps might be helpful. Break them down into:
- Day of week
- Time since final occasion
- Seasonal flags
- Rolling averages
2. Categorical Grouping
Too many classes? You possibly can group them. As a substitute of monitoring each product title, strive “perishables,” “snacks,” or “instruments.”
3. Area-Primarily based Ratios
Ratios usually beat uncooked numbers. You possibly can strive:
- Fertilizer per acre
- Gross sales per stock unit
- Water per plant
4. Sturdy Aggregations
Use medians as an alternative of means to deal with wild outliers (like sensor errors or data-entry typos).
5. Flag Variables
Flags are your secret weapon. Add columns like:
- “Manually corrected information”
- “Sensor low battery”
- “Estimate as an alternative of precise”
They provide your mannequin context that issues.
Lacking Knowledge?
Lacking information generally is a drawback, however it’s not all the time. It may be info in disguise. It’s vital to deal with it with care and readability.
Deal with Missingness as a Sign
Typically, what’s not stuffed in tells a narrative. If farmers skip sure entries, it’d point out one thing about their state of affairs or priorities.
Follow Easy Imputation
Go along with medians, modes, or forward-fill. Fancy multi-model imputation? Skip it in case your laptop computer is already wheezing.
Use Area Data
Area specialists usually have good guidelines, like utilizing common rainfall throughout planting season or identified vacation gross sales dips.
Keep away from Complicated Chains
Don’t attempt to impute every thing from every thing else; it simply provides noise. Outline a number of stable guidelines and persist with them.
Small Knowledge? Meet Switch Studying
Right here’s a cool trick: you don’t want large datasets to learn from the large leagues. Even easy types of switch studying can go a good distance.
Textual content Embeddings
Bought inspection notes or written suggestions? Use small, pretrained embeddings. Massive positive aspects with low price.
World to Native
Take a world weather-yield mannequin and regulate it utilizing a number of native samples. Linear tweaks can do wonders.
Function Choice from Benchmarks
Use public datasets to information what options to incorporate, particularly in case your native information is noisy or sparse.
Time Sequence Forecasting
Borrow seasonal patterns or lag buildings from world traits and customise them to your native wants.
A Actual-World Case: Smarter Crop Decisions in Low-Useful resource Farming
A helpful illustration of light-weight machine studying comes from a StrataScratch undertaking that works with actual agricultural information from India.

The purpose of this undertaking is to advocate crops that match the precise situations farmers are working with: messy climate patterns, imperfect soil, all of it.
The dataset behind it’s modest: about 2,200 rows. Nevertheless it covers vital particulars like soil vitamins (nitrogen, phosphorus, potassium) and pH ranges, plus fundamental local weather info like temperature, humidity, and rainfall. Here’s a pattern of the information:

As a substitute of reaching for deep studying or different heavy strategies, the evaluation stays deliberately easy.
We begin with some descriptive statistics:
|
df.select_dtypes(embody=[‘int64’, ‘float64’]).describe() |

Then, we proceed to some visible exploration:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# Setting the aesthetic model of the plots sns.set_theme(model=“whitegrid”)
# Creating visualizations for Temperature, Humidity, and Rainfall fig, axes = plt.subplots(1, 3, figsize=(14, 5))
# Temperature Distribution sns.histplot(df[‘temperature’], kde=True, colour=“skyblue”, ax=axes[0]) axes[0].set_title(‘Temperature Distribution’)
# Humidity Distribution sns.histplot(df[‘humidity’], kde=True, colour=“olive”, ax=axes[1]) axes[1].set_title(‘Humidity Distribution’)
# Rainfall Distribution sns.histplot(df[‘rainfall’], kde=True, colour=“gold”, ax=axes[2]) axes[2].set_title(‘Rainfall Distribution’)
plt.tight_layout() plt.present() |

Lastly, we run a number of ANOVA exams to grasp how environmental components differ throughout crop sorts:
ANOVA Evaluation for Humidity
|
# Outline crop_types primarily based in your DataFrame ‘df’ crop_types = df[‘label’].distinctive()
# Making ready a listing of humidity values for every crop sort humidity_lists = [df[df[‘label’] == crop][‘humidity’] for crop in crop_types]
# Performing the ANOVA take a look at for humidity anova_result_humidity = f_oneway(*humidity_lists)
anova_result_humidity |

ANOVA Evaluation for Rainfall
|
# Outline crop_types primarily based in your DataFrame ‘df’ if not already outlined crop_types_rainfall = df[‘label’].distinctive()
# Making ready a listing of rainfall values for every crop sort rainfall_lists = [df[df[‘label’] == crop][‘rainfall’] for crop in crop_types_rainfall]
# Performing the ANOVA take a look at for rainfall anova_result_rainfall = f_oneway(*rainfall_lists)
anova_result_rainfall |
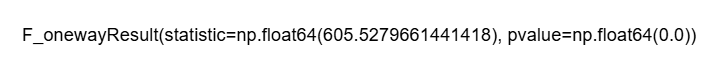
ANOVA Evaluation for Temperature
|
# Guarantee crop_types is outlined out of your DataFrame ‘df’ crop_types_temp = df[‘label’].distinctive()
# Making ready a listing of temperature values for every crop sort temperature_lists = [df[df[‘label’] == crop][‘temperature’] for crop in crop_types_temp]
# Performing the ANOVA take a look at for temperature anova_result_temperature = f_oneway(*temperature_lists)
anova_result_temperature |
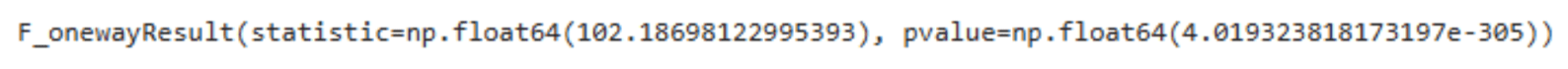
This small-scale, low-resource undertaking mirrors real-life challenges in rural farming. Everyone knows that climate patterns don’t comply with guidelines, and local weather information might be patchy or inconsistent. So, as an alternative of throwing a posh mannequin on the drawback and hoping it figures issues out, we dug into the information manually.
Maybe probably the most helpful side of this strategy is its interpretability. Farmers aren’t on the lookout for opaque predictions; they need steering they’ll act on. Statements like “this crop performs higher below excessive humidity” or “that crop tends to choose drier situations” translate statistical findings into sensible selections.
This complete workflow was tremendous light-weight. No fancy {hardware}, no costly software program, simply trusty instruments like pandas, Seaborn, and a few fundamental statistical exams. Every little thing ran easily on an everyday laptop computer.
The core analytical step used ANOVA to test whether or not environmental situations akin to humidity or rainfall range considerably between crop sorts.
In some ways, this captures the spirit of machine studying in low-resource environments. The methods stay grounded, computationally light, and simple to elucidate, but they nonetheless provide insights that may assist individuals make extra knowledgeable selections, even with out superior infrastructure.
For Aspiring Knowledge Scientists in Low-Useful resource Settings
You may not have a GPU. You is perhaps utilizing free-tier instruments. And your information would possibly appear to be a puzzle with lacking items.
However right here’s the factor: you’re studying abilities that many overlook:
- Actual-world information cleansing
- Function engineering with intuition
- Constructing belief by way of explainable fashions
- Working good, not flashy
Prioritize this:
- Clear, constant information
- Traditional fashions that work
- Considerate options
- Easy switch studying tips
- Clear notes and reproducibility
Ultimately, that is the type of work that makes an incredible information scientist.
Conclusion
Picture by Creator
Working in low-resource machine studying environments is feasible. It asks you to be artistic and obsessed with your mission. It comes right down to discovering the sign within the noise and fixing actual issues that make life simpler for actual individuals.
On this article, we explored how light-weight fashions, good options, sincere dealing with of lacking information, and intelligent reuse of present information may also help you get forward when working in one of these state of affairs.
What are your ideas? Have you ever ever constructed an answer in a low-resource setup?











{kind=link}