Introduction
Within the quickly evolving panorama of Synthetic Intelligence, Retrieval-Augmented Technology (RAG) has emerged as a pivotal approach for enhancing the factual accuracy and relevance of Giant Language Fashions (LLMs). By enabling LLMs to retrieve data from exterior information bases earlier than producing responses, RAG mitigates frequent points similar to hallucination and outdated data.
Nevertheless, conventional RAG approaches usually depend on vector-based similarity searches, which, whereas efficient for broad retrieval, can typically fall quick in capturing the intricate relationships and contextual nuances current in complicated information. This limitation can result in the retrieval of fragmented data, hindering the LLM’s means to synthesize actually complete and contextually applicable solutions.
Enter Graph RAG, a groundbreaking development that addresses these challenges by integrating the ability of data graphs straight into the retrieval course of. In contrast to standard RAG methods that deal with data as remoted chunks, Graph RAG dynamically constructs and leverages information graphs to grasp the interconnectedness of entities and ideas.
This enables for a extra clever and exact retrieval mechanism, the place the system can navigate relationships inside the information to fetch not simply related data, but in addition the encircling context that enriches the LLM’s understanding. By doing so, Graph RAG ensures that the retrieved information is just not solely correct but in addition deeply contextual, resulting in considerably improved response high quality and a extra strong AI system.
This text will delve into the core rules of Graph RAG, discover its key options, exhibit its sensible functions with code examples, and focus on the way it represents a major leap ahead in constructing extra clever and dependable AI functions.
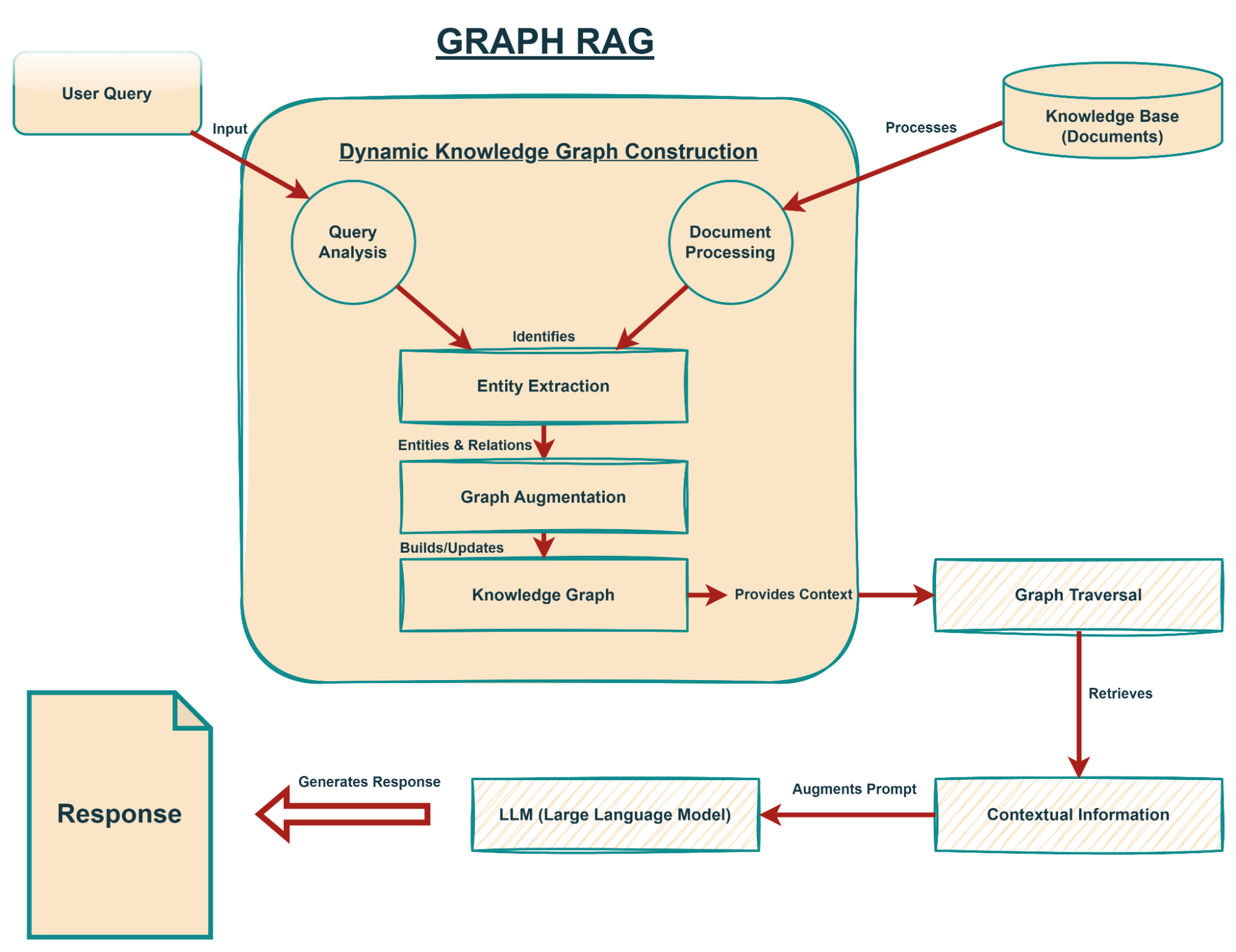
Key Options of Graph RAG
Graph RAG distinguishes itself from conventional RAG architectures via a number of revolutionary options that collectively contribute to its enhanced retrieval capabilities and contextual understanding. These options should not merely additive however essentially reshape how data is accessed and utilized by LLMs.
Dynamic Data Graph Development
One of the vital vital developments of Graph RAG is its means to assemble a information graph dynamically through the retrieval course of.
Conventional information graphs are sometimes pre-built and static, requiring in depth handbook effort or complicated ETL (Extract, Rework, Load) pipelines to take care of and replace. In distinction, Graph RAG builds or expands the graph in actual time primarily based on the entities and relationships recognized from the enter question and preliminary retrieval outcomes.
This on-the-fly development ensures that the information graph is at all times related to the instant context of the consumer’s question, avoiding the overhead of managing a large, all-encompassing graph. This dynamic nature permits the system to adapt to new data and evolving contexts with out requiring fixed re-indexing or graph reconstruction.
As an illustration, if a question mentions a newly found scientific idea, Graph RAG can incorporate this into its short-term information graph, linking it to current associated entities, thereby offering up-to-date and related data.
Clever Entity Linking
On the coronary heart of dynamic graph development lies clever entity linking.
As data is processed, Graph RAG identifies key entities (e.g., individuals, organizations, places, ideas) and establishes relationships between them. This goes past easy key phrase matching; it includes understanding the semantic connections between totally different items of knowledge.
For instance, if a doc mentions “GPT-4” and one other mentions “OpenAI,” the system can hyperlink these entities via a “developed by” relationship. This linking course of is essential as a result of it permits the RAG system to traverse the graph and retrieve not simply the direct reply to a question, but in addition associated data that gives richer context.
That is notably useful in domains the place entities are extremely interconnected, similar to medical analysis, authorized paperwork, or monetary studies. By linking related entities, Graph RAG ensures a extra complete and interconnected retrieval, enhancing the depth and breadth of the knowledge offered to the LLM.
Contextual Choice-Making with Graph Traversal
In contrast to vector search, which retrieves data primarily based on semantic similarity in an embedding house, Graph RAG leverages the specific relationships inside the information graph for contextual decision-making.
When a question is posed, the system does not simply pull remoted paperwork; it performs graph traversals, following paths between nodes to establish essentially the most related and contextually applicable data.
This implies the system can reply complicated, multi-hop questions that require connecting disparate items of knowledge.
For instance, to reply “What are the primary analysis areas of the lead scientist at DeepMind?”, a standard RAG may wrestle to attach “DeepMind” to its “lead scientist” after which to their “analysis areas” if these items of knowledge are in separate paperwork. Graph RAG, nonetheless, can navigate these relationships straight inside the graph, guaranteeing that the retrieved data is just not solely correct but in addition deeply contextualized inside the broader information community.
This functionality considerably improves the system’s means to deal with nuanced queries and supply extra coherent and logically structured responses.
Confidence Rating Utilization for Refined Retrieval
To additional optimize the retrieval course of and forestall the inclusion of irrelevant or low-quality data, Graph RAG makes use of confidence scores derived from the information graph.
These scores may be primarily based on varied components, such because the energy of relationships between entities, the recency of knowledge, or the perceived reliability of the supply. By assigning confidence scores, the framework can intelligently determine when and the way a lot exterior information to retrieve.
This mechanism acts as a filter, serving to to prioritize high-quality, related data whereas minimizing the addition of noise.
As an illustration, if a specific relationship has a low confidence rating, the system may select to not increase retrieval alongside that path, thereby avoiding the introduction of doubtless deceptive or unverified information.
This selective enlargement ensures that the LLM receives a compact and extremely related set of details, bettering each effectivity and response accuracy by sustaining a centered and pertinent information graph for every question.
How Graph RAG Works: A Step-by-Step Breakdown
Understanding the theoretical underpinnings of Graph RAG is crucial, however its true energy lies in its sensible implementation.
This part will stroll via the standard workflow of a Graph RAG system, illustrating every stage with conceptual code examples to offer a clearer image of its operational mechanics.
Whereas the precise implementation might differ relying on the chosen graph database, LLM, and particular use case, the core rules stay constant.
Step 1: Question Evaluation and Preliminary Entity Extraction
The method begins when a consumer submits a question.
Step one for the Graph RAG system is to investigate this question to establish key entities and potential relationships. This usually includes Pure Language Processing (NLP) strategies similar to Named Entity Recognition (NER) and dependency parsing.
Conceptual Code Instance (Python):
import spacy
from sklearn.feature_extraction.textual content import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import networkx as nx
nlp = spacy.load("en_core_web_sm")
def extract_entities(question):
doc = nlp(question)
return [(ent.text.strip(), ent.label_) for ent in doc.ents]
question = "Who's the CEO of Google and what's their internet price?"
extracted_entities = extract_entities(question)
print(f"🧠 Extracted Entities: {extracted_entities}"

Step 2: Preliminary Retrieval and Candidate Doc Identification
As soon as entities are extracted, the system performs an preliminary retrieval from an unlimited corpus of paperwork.
This may be accomplished utilizing conventional vector search (e.g., cosine similarity on embeddings) or key phrase matching. The objective right here is to establish a set of candidate paperwork which are doubtlessly related to the question.
Conceptual Code Instance (Python – simplified vector search):
corpus = [
"Sundar Pichai is the CEO of Google.",
"Google is a multinational technology company.",
"The net worth of many tech CEOs is in the billions.",
"Larry Page and Sergey Brin founded Google."
]
vectorizer = TfidfVectorizer()
corpus_embeddings = vectorizer.fit_transform(corpus)
def retrieve_candidate_documents(question, corpus, vectorizer, corpus_embeddings, top_k=2):
query_embedding = vectorizer.remodel([query])
similarities = cosine_similarity(query_embedding, corpus_embeddings).flatten()
top_indices = similarities.argsort()[-top_k:][::-1]
return [corpus[i] for i in top_indices]
candidate_docs = retrieve_candidate_documents(question, corpus, vectorizer, corpus_embeddings)
print(f"📄 Candidate Paperwork: {candidate_docs}")

Step 3: Dynamic Data Graph Development and Augmentation
That is the core of Graph RAG.
Take a look at our hands-on, sensible information to studying Git, with best-practices, industry-accepted requirements, and included cheat sheet. Cease Googling Git instructions and truly study it!
The extracted entities from the question and the content material of the candidate paperwork are used to dynamically assemble or increase a information graph. This includes figuring out new entities and relationships inside the textual content and including them as nodes and edges to the graph. If a base information graph already exists, this step augments it; in any other case, it builds a brand new graph from scratch for the present question context.
Conceptual Code Instance (Python – utilizing NetworkX for graph illustration):
def build_or_augment_graph(graph, entities, paperwork):
for entity, entity_type in entities:
graph.add_node(entity, kind=entity_type)
for doc in paperwork:
doc_nlp = nlp(doc)
individual = None
org = None
for ent in doc_nlp.ents:
if ent.label_ == "PERSON":
individual = ent.textual content.strip().strip(".")
elif ent.label_ == "ORG":
org = ent.textual content.strip().strip(".")
if individual and org and "CEO" in doc:
graph.add_node(individual, kind="PERSON")
graph.add_node(org, kind="ORG")
graph.add_edge(individual, org, relation="CEO_of")
return graph
knowledge_graph = nx.Graph()
knowledge_graph = build_or_augment_graph(knowledge_graph, extracted_entities, candidate_docs)
print("🧩 Graph Nodes:", knowledge_graph.nodes(information=True))
print("🔗 Graph Edges:", knowledge_graph.edges(information=True))

Step 4: Graph Traversal and Contextual Info Retrieval
With the dynamic information graph in place, the system performs graph traversals ranging from the question entities. It explores the relationships (edges) and related entities (nodes) to retrieve contextually related data.
This step is the place the “graph” in Graph RAG actually shines, permitting for multi-hop reasoning and the invention of implicit connections.
Conceptual Code Instance (Python – graph traversal):
def traverse_graph_for_context(graph, start_entity, depth=2):
contextual_info = set()
visited = set()
queue = [(start_entity, 0)]
whereas queue:
current_node, current_depth = queue.pop(0)
if current_node in visited or current_depth > depth:
proceed
visited.add(current_node)
contextual_info.add(current_node)
for neighbor in graph.neighbors(current_node):
edge_data = graph.get_edge_data(current_node, neighbor)
if edge_data:
relation = edge_data.get("relation", "unknown")
contextual_info.add(f"{current_node} {relation} {neighbor}")
queue.append((neighbor, current_depth + 1))
return listing(contextual_info)
context = traverse_graph_for_context(knowledge_graph, "Google")
print(f"🔍 Contextual Info from Graph: {context}")

Step 5: Confidence Rating-Guided Enlargement (Optionally available however Really useful)
As talked about within the options, confidence scores can be utilized to information the graph traversal.
This ensures that the enlargement of retrieved data is managed and avoids pulling in irrelevant or low-quality information. This may be built-in into Step 4 by assigning scores to edges or nodes and prioritizing high-scoring paths.
Step 6: Info Synthesis and LLM Augmentation
The retrieved contextual data from the graph, together with the unique question and doubtlessly the preliminary candidate paperwork, is then synthesized right into a coherent immediate for the LLM.
This enriched immediate gives the LLM with a a lot deeper and extra structured understanding of the consumer’s request.
Conceptual Code Instance (Python):
def synthesize_prompt(question, contextual_info, candidate_docs):
return "n".be part of([
f"User Query: {query}",
"Relevant Context from Knowledge Graph:",
"n".join(contextual_info),
"Additional Information from Documents:",
"n".join(candidate_docs)
])
final_prompt = synthesize_prompt(question, context, candidate_docs)
print(f"n📝 Remaining Immediate for LLM:n{final_prompt}")

Step 7: LLM Response Technology
Lastly, the LLM processes the augmented immediate and generates a response.
As a result of the immediate is wealthy with contextual and interconnected data, the LLM is healthier outfitted to offer correct, complete, and coherent solutions.
Conceptual Code Instance (Python – utilizing a placeholder LLM name):
def generate_llm_response(immediate):
if "Sundar" in immediate and "CEO of Google" in immediate:
return "Sundar Pichai is the CEO of Google. He oversees the corporate and has a major internet price."
return "I want extra data to reply that precisely."
llm_response = generate_llm_response(final_prompt)
print(f"n💬 LLM Response: {llm_response}
import matplotlib.pyplot as plt
plt.determine(figsize=(4, 3))
pos = nx.spring_layout(knowledge_graph)
nx.draw(knowledge_graph, pos, with_labels=True, node_color='skyblue', node_size=2000, font_size=12, font_weight='daring')
edge_labels = nx.get_edge_attributes(knowledge_graph, 'relation')
nx.draw_networkx_edge_labels(knowledge_graph, pos, edge_labels=edge_labels)
plt.title("Graph RAG: Data Graph")
plt.present()

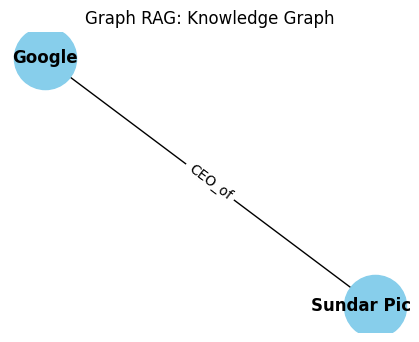
This step-by-step course of, notably the dynamic graph development and traversal, permits Graph RAG to maneuver past easy key phrase or semantic similarity, enabling a extra profound understanding of knowledge and resulting in superior response era.
The combination of graph buildings gives a strong mechanism for contextualizing data, which is a essential think about reaching high-quality RAG outputs.
Sensible Purposes and Use Circumstances of Graph RAG
Graph RAG is not only a theoretical idea; its means to grasp and leverage relationships inside information opens up a myriad of sensible functions throughout varied industries. By offering LLMs with a richer, extra interconnected context, Graph RAG can considerably improve efficiency in eventualities the place conventional RAG may fall quick. Listed here are some compelling use circumstances:
1. Enhanced Enterprise Data Administration
Giant organizations usually wrestle with huge, disparate information bases, together with inner paperwork, studies, wikis, and buyer help logs. Conventional search and RAG methods can retrieve particular person paperwork, however they usually fail to attach associated data throughout totally different silos.
Graph RAG can construct a dynamic information graph from these numerous sources, linking workers to tasks, tasks to paperwork, paperwork to ideas, and ideas to exterior rules or {industry} requirements. This enables for:
-
Clever Q&A for Staff: Staff can ask complicated questions like “What are the compliance necessities for Venture X, and which staff members are specialists in these areas?” Graph RAG can traverse the graph to establish related compliance paperwork, hyperlink them to particular rules, after which discover the staff related to these rules or Venture X.
-
Automated Report Technology: By understanding the relationships between information factors, Graph RAG can collect all needed data for complete studies, similar to venture summaries, threat assessments, or market analyses, considerably lowering handbook effort.
-
Onboarding and Coaching: New hires can rapidly stand up to hurry by querying the information base and receiving contextually wealthy solutions that designate not simply what one thing is, but in addition the way it pertains to different inner processes, instruments, or groups.
2. Superior Authorized and Regulatory Compliance
The authorized and regulatory domains are inherently complicated, characterised by huge quantities of interconnected paperwork, precedents, and rules. Understanding the relationships between totally different authorized clauses, case legal guidelines, and regulatory frameworks is essential. Graph RAG generally is a game-changer right here:
-
Contract Evaluation: Attorneys can use Graph RAG to investigate contracts, establish key clauses, obligations, and dangers, and hyperlink them to related authorized precedents or regulatory acts. A question like “Present me all clauses on this contract associated to information privateness and their implications underneath GDPR” may be answered comprehensively by traversing the graph of authorized ideas.
-
Regulatory Affect Evaluation: When new rules are launched, Graph RAG can rapidly establish all affected inner insurance policies, enterprise processes, and even particular tasks, offering a holistic view of the compliance affect.
-
Litigation Assist: By mapping relationships between entities in case paperwork (e.g., events, dates, occasions, claims, proof), Graph RAG can assist authorized groups rapidly establish connections, uncover hidden patterns, and construct stronger arguments.
3. Scientific Analysis and Drug Discovery
Scientific literature is rising exponentially, making it difficult for researchers to maintain up with new discoveries and their interconnections. Graph RAG can speed up analysis by creating dynamic information graphs from scientific papers, patents, and medical trial information:
-
Speculation Technology: Researchers can question the system about potential drug targets, illness pathways, or gene interactions. Graph RAG can join details about compounds, proteins, ailments, and analysis findings to recommend novel hypotheses or establish gaps in present information.
-
Literature Evaluate: As a substitute of sifting via 1000’s of papers, researchers can ask questions like “What are the identified interactions between Protein A and Illness B, and which analysis teams are actively engaged on this?” The system can then present a structured abstract of related findings and researchers.
-
Medical Trial Evaluation: Graph RAG can hyperlink affected person information, therapy protocols, and outcomes to establish correlations and insights that may not be obvious via conventional statistical evaluation, aiding in drug growth and customized medication.
4. Clever Buyer Assist and Chatbots
Whereas many chatbots exist, their effectiveness is commonly restricted by their incapability to deal with complicated, multi-turn conversations that require deep contextual understanding. Graph RAG can energy next-generation buyer help methods:
-
Advanced Question Decision: Clients usually ask questions that require combining data from a number of sources (e.g., product manuals, FAQs, previous help tickets, consumer boards). A question like “My sensible dwelling gadget is not connecting to Wi-Fi after the most recent firmware replace; what are the troubleshooting steps and identified compatibility points with my router mannequin?” may be resolved by a Graph RAG-powered chatbot that understands the relationships between units, firmware variations, router fashions, and troubleshooting procedures.
-
Customized Suggestions: By understanding a buyer’s previous interactions, preferences, and product utilization (represented in a graph), the system can present extremely customized product suggestions or proactive help.
-
Agent Help: Customer support brokers can obtain real-time, contextually related data and options from a Graph RAG system, considerably bettering decision instances and buyer satisfaction.
These use circumstances spotlight Graph RAG’s potential to rework how we work together with data, transferring past easy retrieval to true contextual understanding and clever reasoning. By specializing in the relationships inside information, Graph RAG unlocks new ranges of accuracy, effectivity, and perception in AI-powered functions.
Conclusion
Graph RAG represents a major evolution within the subject of Retrieval-Augmented Technology, transferring past the restrictions of conventional vector-based retrieval to harness the ability of interconnected information. By dynamically developing and leveraging information graphs, Graph RAG allows Giant Language Fashions to entry and synthesize data with unprecedented contextual depth and accuracy.
This method not solely enhances the factual grounding of LLM responses but in addition unlocks the potential for extra subtle reasoning, multi-hop query answering, and a deeper understanding of complicated relationships inside information.
The sensible functions of Graph RAG are huge and transformative, spanning enterprise information administration, authorized and regulatory compliance, scientific analysis, and clever buyer help. In every of those domains, the power to navigate and perceive the intricate net of knowledge via a graph construction results in extra exact, complete, and dependable AI-powered options. As information continues to develop in complexity and interconnectedness, Graph RAG provides a sturdy framework for constructing clever methods that may actually comprehend and make the most of the wealthy tapestry of human information.
Whereas the implementation of Graph RAG might contain overcoming challenges associated to graph development, entity extraction, and environment friendly traversal, the advantages by way of enhanced LLM efficiency and the power to sort out real-world issues with higher efficacy are plain.
As analysis and growth on this space proceed, Graph RAG is poised to develop into an indispensable element within the structure of superior AI methods, paving the best way for a future the place AI can cause and reply with a degree of intelligence that really mirrors human understanding.
Steadily Requested Questions
1. What’s the main benefit of Graph RAG over conventional RAG?
The first benefit of Graph RAG is its means to grasp and leverage the relationships between entities and ideas inside a information graph. In contrast to conventional RAG, which frequently depends on semantic similarity in vector house, Graph RAG can carry out multi-hop reasoning and retrieve contextually wealthy data by traversing specific connections, resulting in extra correct and complete responses.
2. How does Graph RAG deal with new data or evolving information?
Graph RAG employs dynamic information graph development. This implies it may possibly construct or increase the information graph in real-time primarily based on the entities recognized within the consumer question and retrieved paperwork. This on-the-fly functionality permits the system to adapt to new data and evolving contexts with out requiring fixed re-indexing or handbook graph updates.
3. Is Graph RAG appropriate for all sorts of information?
Graph RAG is especially efficient for information the place relationships between entities are essential for understanding and answering queries. This contains structured, semi-structured, and unstructured textual content that may be remodeled right into a graph illustration. Whereas it may possibly work with varied information varieties, its advantages are most pronounced in domains wealthy with interconnected data, similar to authorized paperwork, scientific literature, or enterprise information bases.
4. What are the primary elements required to construct a Graph RAG system?
Key elements usually embrace:
- **LLM (Giant Language Mannequin): **For producing responses.
Graph Database (or Graph Illustration Library): To retailer and handle the information graph (e.g., Neo4j, Amazon Neptune, NetworkX). - Info Extraction Module: For Named Entity Recognition (NER) and Relation Extraction (RE) to populate the graph.
Retrieval Module: To carry out preliminary doc retrieval after which graph traversal. - Immediate Engineering Module: To synthesize the retrieved graph context right into a coherent immediate for the LLM.
5. What are the potential challenges in implementing Graph RAG?
Challenges can embrace:
- Complexity of Graph Development: Precisely extracting entities and relations from unstructured textual content may be difficult.
- Scalability: Managing and traversing very giant information graphs effectively may be computationally intensive.
- Knowledge High quality: The standard of the generated graph closely will depend on the standard of the enter information and the extraction fashions.
- Integration: Seamlessly integrating varied elements (LLM, graph database, NLP instruments) can require vital engineering effort.
6. Can Graph RAG be mixed with different RAG strategies?
Sure, Graph RAG may be mixed with different RAG strategies. As an illustration, preliminary retrieval can nonetheless leverage vector search to slim down the related doc set, after which Graph RAG may be utilized to those candidate paperwork to construct a extra exact contextual graph. This hybrid method can provide the very best of each worlds: the broad protection of vector search and the deep contextual understanding of graph-based retrieval.
7. How does confidence scoring work in Graph RAG?
Confidence scoring in Graph RAG includes assigning scores to nodes and edges inside the dynamically constructed information graph. These scores can replicate the energy of a relationship, the recency of knowledge, or the reliability of its supply. The system makes use of these scores to prioritize paths throughout graph traversal, guaranteeing that solely essentially the most related and high-quality data is retrieved and used to enhance the LLM immediate, thereby minimizing irrelevant additions.
References
- Graph RAG: Dynamic Data Graph Development for Enhanced Retrieval
Notice: This can be a conceptual article primarily based on the rules of Graph RAG. Particular analysis papers on “Graph RAG” as a unified idea are rising, however the underlying concepts draw from information graphs, RAG, and dynamic graph development.
Authentic Jupyter Pocket book (for code examples and base content material)
- Retrieval-Augmented Technology (RAG)
Lewis, P., et al. (2020). Retrieval-Augmented Technology for Data-Intensive NLP Duties. arXiv preprint arXiv:2005.11401. https://arxiv.org/abs/2005.11401 - Data Graphs
Ehrlinger, L., & Wöß, W. (2016). Data Graphs: An Introduction to Their Creation and Utilization. In Semantic Net Challenges (pp. 1-17). Springer, Cham. https://hyperlink.springer.com/chapter/10.1007/978-3-319-38930-1_1 - Named Entity Recognition (NER) and Relation Extraction (RE)
Nadeau, D., & Sekine, S. (2007). A survey of named entity recognition and classification. Lingvisticae Investigationes, 30(1), 3-26.
https://www.researchgate.internet/publication/220050800_A_survey_of_named_entity_recognition_and_classification - NetworkX (Python Library for Graph Manipulation)
https://networkx.org/ - spaCy (Python Library for NLP)
https://spacy.io/ - scikit-learn (Python Library for Machine Studying)
https://scikit-learn.org/











{kind=link}