Can a single AI stack plan like a researcher, motive over scenes, and switch motions throughout totally different robots—with out retraining from scratch? Google DeepMind’s Gemini Robotics 1.5 says sure, by splitting embodied intelligence into two fashions: Gemini Robotics-ER 1.5 for high-level embodied reasoning (spatial understanding, planning, progress/success estimation, tool-use) and Gemini Robotics 1.5 for low-level visuomotor management. The system targets long-horizon, real-world duties (e.g., multi-step packing, waste sorting with native guidelines) and introduces movement switch to reuse knowledge throughout heterogeneous platforms.
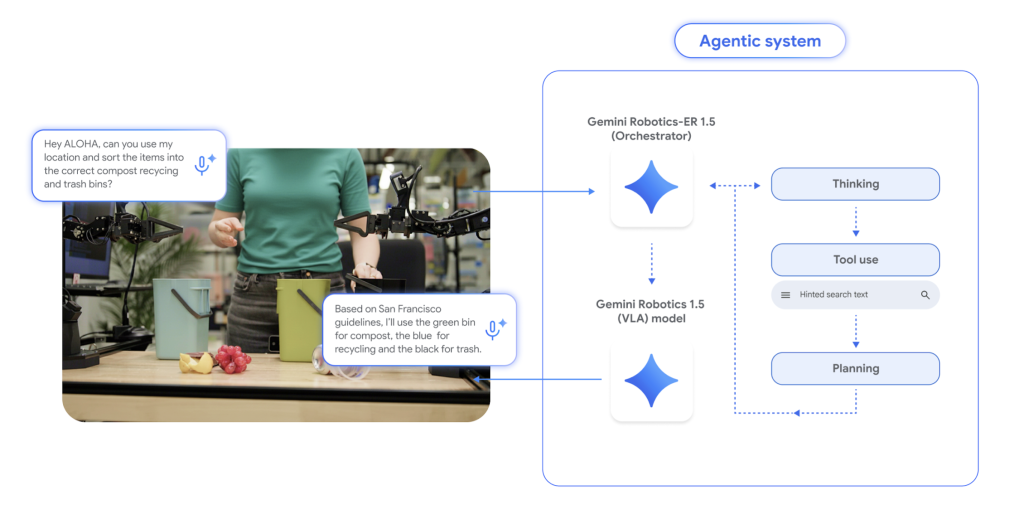
What really is the stack?
- Gemini Robotics-ER 1.5 (reasoner/orchestrator): A multimodal planner that ingests photos/video (and optionally audio), grounds references by way of 2D factors, tracks progress, and invokes exterior instruments (e.g., net search or native APIs) to fetch constraints earlier than issuing sub-goals. It’s accessible by way of the Gemini API in Google AI Studio.
- Gemini Robotics 1.5 (VLA controller): A vision-language-action mannequin that converts directions and percepts into motor instructions, producing express “think-before-act” traces to decompose lengthy duties into short-horizon expertise. Availability is restricted to chose companions throughout the preliminary rollout.
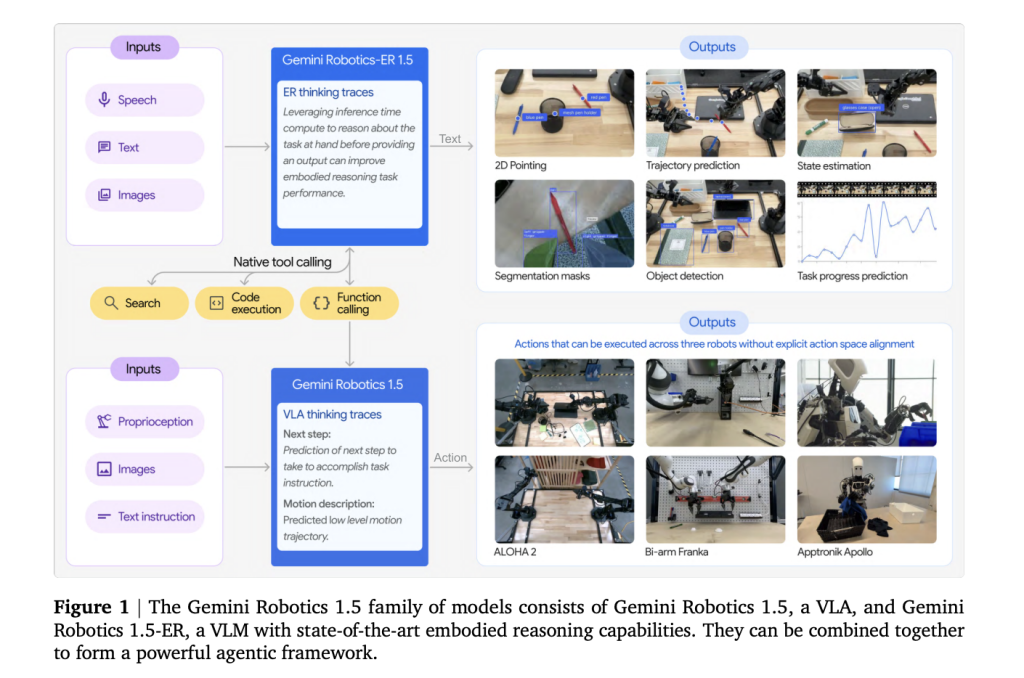
Why cut up cognition from management?
Earlier end-to-end VLAs (Imaginative and prescient-Language-Motion) battle to plan robustly, confirm success, and generalize throughout embodiments. Gemini Robotics 1.5 isolates these considerations: Gemini Robotics-ER 1.5 handles deliberation (scene reasoning, sub-goaling, success detection), whereas the VLA focuses on execution (closed-loop visuomotor management). This modularity improves interpretability (seen inner traces), error restoration, and long-horizon reliability.
Movement Switch throughout embodiments
A core contribution is Movement Switch (MT): coaching the VLA on a unified movement illustration constructed from heterogeneous robotic knowledge—ALOHA, bi-arm Franka, and Apptronik Apollo—so expertise discovered on one platform can zero-shot switch to a different. This reduces per-robot knowledge assortment and narrows sim-to-real gaps by reusing cross-embodiment priors.
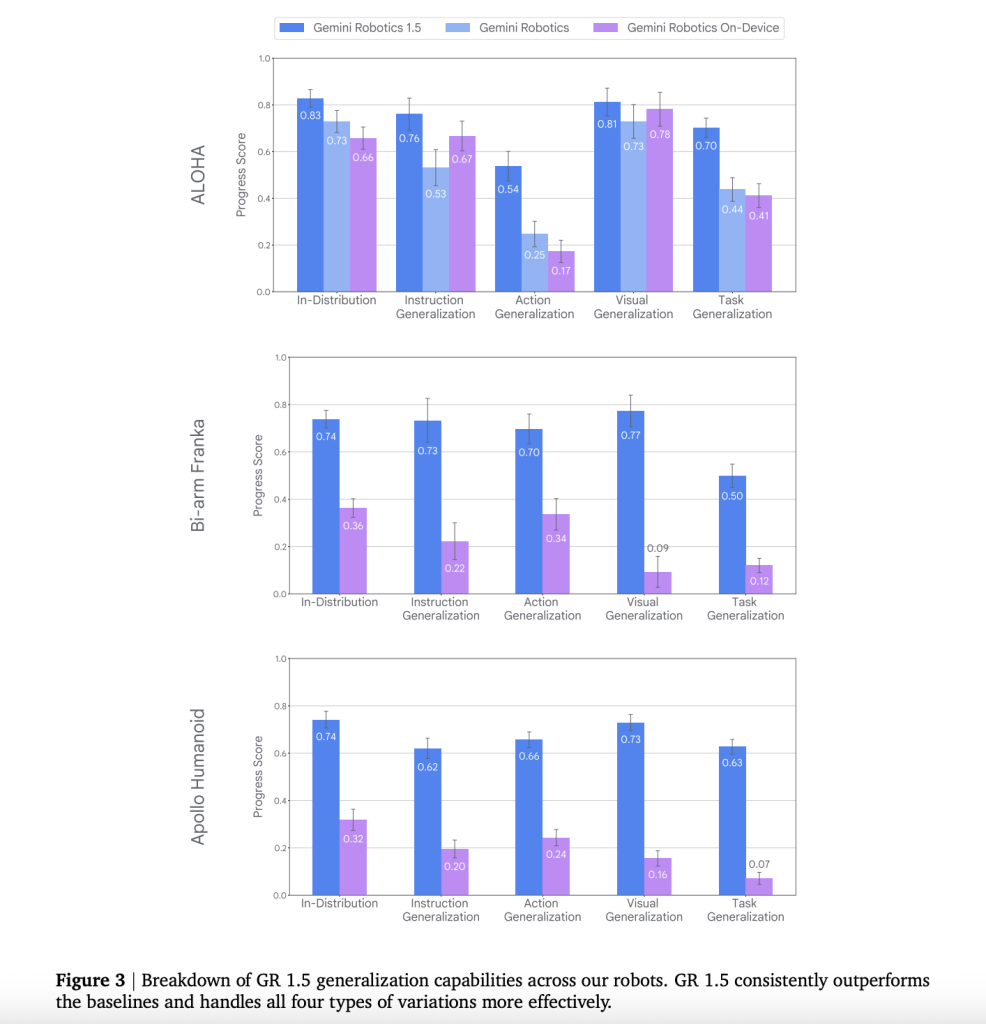
Quantitative alerts
The analysis crew showcased managed A/B comparisons on actual {hardware} and aligned MuJoCo scenes. This consists of:
- Generalization: Robotics 1.5 surpasses prior Gemini Robotics baselines in instruction following, motion generalization, visible generalization, and process generalization throughout the three platforms.
- Zero-shot cross-robot expertise: MT yields measurable good points in progress and success when transferring expertise throughout embodiments (e.g., Franka→ALOHA, ALOHA→Apollo), somewhat than merely bettering partial progress.
- “Pondering” improves appearing: Enabling VLA thought traces will increase long-horizon process completion and stabilizes mid-rollout plan revisions.
- Finish-to-end agent good points: Pairing Gemini Robotics-ER 1.5 with the VLA agent considerably improves progress on multi-step duties (e.g., desk group, cooking-style sequences) versus a Gemini-2.5-Flash-based baseline orchestrator.
Security and analysis
DeepMind analysis crew highlights layered controls: policy-aligned dialog/planning, safety-aware grounding (e.g., not pointing to hazardous objects), low-level bodily limits, and expanded analysis suites (e.g., ASIMOV/ASIMOV-style situation testing and auto red-teaming to elicit edge-case failures). The aim is to catch hallucinated affordances or nonexistent objects earlier than actuation.
Aggressive/business context
Gemini Robotics 1.5 is a shift from “single-instruction” robotics towards agentic, multi-step autonomy with express net/instrument use and cross-platform studying, a functionality set related to client and industrial robotics. Early associate entry facilities on established robotics distributors and humanoid platforms.
Key Takeaways
- Two-model structure (ER ↔ VLA): Gemini Robotics-ER 1.5 handles embodied reasoning—spatial grounding, planning, success/progress estimation, instrument calls—whereas Robotics 1.5 is the vision-language-action executor that points motor instructions.
- “Assume-before-act” management: The VLA produces express intermediate reasoning/traces throughout execution, bettering long-horizon decomposition and mid-task adaptation.
- Movement Switch throughout embodiments: A single VLA checkpoint reuses expertise throughout heterogeneous robots (ALOHA, bi-arm Franka, Apptronik Apollo), enabling zero-/few-shot cross-robot execution somewhat than per-platform retraining.
- Device-augmented planning: ER 1.5 can invoke exterior instruments (e.g., net search) to fetch constraints, then situation plans—e.g., packing after checking native climate or making use of city-specific recycling guidelines.
- Quantified enhancements over prior baselines: The tech report paperwork increased instruction/motion/visible/process generalization and higher progress/success on actual {hardware} and aligned simulators; outcomes cowl cross-embodiment transfers and long-horizon duties.
- Availability and entry: ER 1.5 is offered by way of the Gemini API (Google AI Studio) with docs, examples, and preview knobs; Robotics 1.5 (VLA) is restricted to pick companions with a public waitlist.
- Security & analysis posture: DeepMind highlights layered safeguards (policy-aligned planning, safety-aware grounding, bodily limits) and an upgraded ASIMOV benchmark plus adversarial evaluations to probe dangerous behaviors and hallucinated affordances.
Abstract
Gemini Robotics 1.5 operationalizes a clear separation of embodied reasoning and management, provides movement switch to recycle knowledge throughout robots, and showcases the reasoning floor (level grounding, progress/success estimation, instrument calls) to builders by way of the Gemini API. For groups constructing real-world brokers, the design reduces per-platform knowledge burden and strengthens long-horizon reliability—whereas maintaining security in scope with devoted check suites and guardrails.
Take a look at the Paper and Technical particulars. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.









{kind=link}