Google expanded its Gemini mannequin household with the discharge of Gemini Embedding 2. This second-generation mannequin succeeds the text-only gemini-embedding-001 and is designed particularly to deal with the high-dimensional storage and cross-modal retrieval challenges confronted by AI builders constructing production-grade Retrieval-Augmented Technology (RAG) methods. The Gemini Embedding 2 launch marks a big technical shift in how embedding fashions are architected, transferring away from modality-specific pipelines towards a unified, natively multimodal latent area.
Native Multimodality and Interleaved Inputs
The first architectural development in Gemini Embedding 2 is its capacity to map 5 distinct media varieties—Textual content, Picture, Video, Audio, and PDF—right into a single, high-dimensional vector area. This eliminates the necessity for complicated pipelines that beforehand required separate fashions for various knowledge varieties, comparable to CLIP for pictures and BERT-based fashions for textual content.
The mannequin helps interleaved inputs, permitting builders to mix totally different modalities in a single embedding request. That is significantly related to be used instances the place textual content alone doesn’t present ample context. The technical limits for these inputs are outlined as:
- Textual content: As much as 8,192 tokens per request.
- Photographs: As much as 6 pictures (PNG, JPEG, WebP, HEIC/HEIF).
- Video: As much as 120 seconds of video (MP4, MOV, and so forth.).
- Audio: As much as 80 seconds of native audio (MP3, WAV, and so forth.) with out requiring a separate transcription step.
- Paperwork: As much as 6 pages of PDF information.
By processing these inputs natively, Gemini Embedding 2 captures the semantic relationships between a visible body in a video and the spoken dialogue in an audio observe, projecting them as a single vector that may be in contrast towards textual content queries utilizing normal distance metrics like Cosine Similarity.
Effectivity by way of Matryoshka Illustration Studying (MRL)
Storage and compute prices are sometimes the first bottlenecks in large-scale vector search. To mitigate this, Gemini Embedding 2 implements Matryoshka Illustration Studying (MRL).
Normal embedding fashions distribute semantic data evenly throughout all dimensions. If a developer truncates a 3,072-dimension vector to 768 dimensions, the accuracy usually collapses as a result of the knowledge is misplaced. In distinction, Gemini Embedding 2 is skilled to pack probably the most crucial semantic data into the earliest dimensions of the vector.
The mannequin defaults to 3,072 dimensions, however Google group has optimized three particular tiers for manufacturing use:
- 3,072: Most precision for complicated authorized, medical, or technical datasets.
- 1,536: A steadiness of efficiency and storage effectivity.
- 768: Optimized for low-latency retrieval and decreased reminiscence footprint.
Matryoshka Illustration Studying (MRL) permits a ‘short-listing’ structure. A system can carry out a rough, high-speed search throughout hundreds of thousands of things utilizing the 768-dimension sub-vectors, then carry out a exact re-ranking of the highest outcomes utilizing the total 3,072-dimension embeddings. This reduces the computational overhead of the preliminary retrieval stage with out sacrificing the ultimate accuracy of the RAG pipeline.
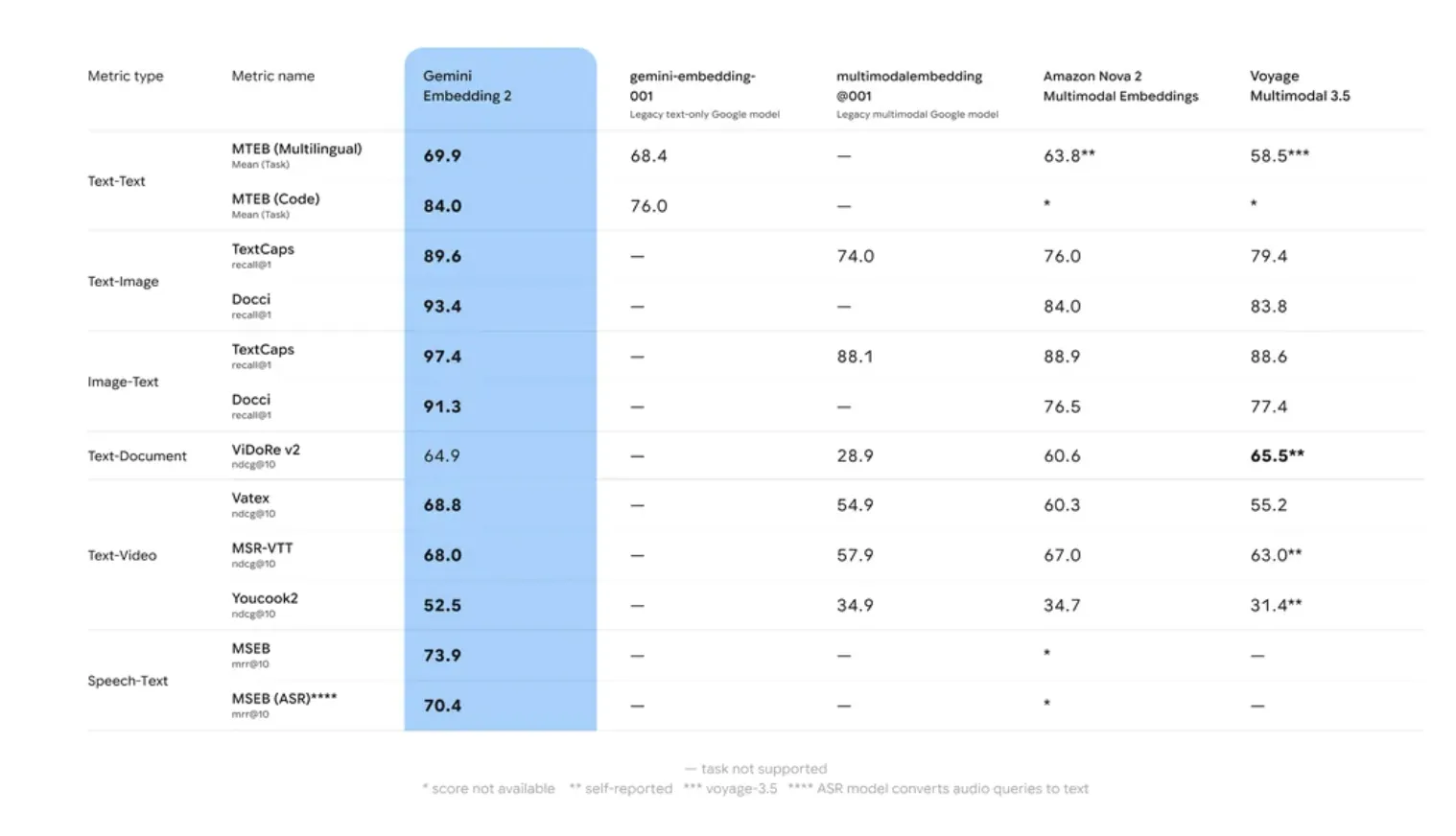
Benchmarking: MTEB and Lengthy-Context Retrieval
Google AI’s inner analysis and efficiency on the Huge Textual content Embedding Benchmark (MTEB) point out that Gemini Embedding 2 outperforms its predecessor in two particular areas: Retrieval Accuracy and Robustness to Area Shift.
Many embedding fashions undergo from ‘area drift,’ the place accuracy drops when transferring from generic coaching knowledge (like Wikipedia) to specialised domains (like proprietary codebases). Gemini Embedding 2 utilized a multi-stage coaching course of involving numerous datasets to make sure larger zero-shot efficiency throughout specialised duties.
The mannequin’s 8,192-token window is a crucial specification for RAG. It permits for the embedding of bigger ‘chunks’ of textual content, which preserves the context needed for resolving coreferences and long-range dependencies inside a doc. This reduces the chance of ‘context fragmentation,’ a standard situation the place a retrieved chunk lacks the knowledge wanted for the LLM to generate a coherent reply.
Key Takeaways
- Native Multimodality: Gemini Embedding 2 helps 5 distinct media varieties—Textual content, Picture, Video, Audio, and PDF—inside a unified vector area. This enables for interleaved inputs (e.g., a picture mixed with a textual content caption) to be processed as a single embedding with out separate mannequin pipelines.
- Matryoshka Illustration Studying (MRL): The mannequin is architected to retailer probably the most crucial semantic data within the early dimensions of a vector. Whereas it defaults to 3,072 dimensions, it helps environment friendly truncation to 1,536 or 768 dimensions with minimal loss in accuracy, lowering storage prices and growing retrieval pace.
- Expanded Context and Efficiency: The mannequin options an 8,192-token enter window, permitting for bigger textual content ‘chunks’ in RAG pipelines. It reveals important efficiency enhancements on the Huge Textual content Embedding Benchmark (MTEB), particularly in retrieval accuracy and dealing with specialised domains like code or technical documentation.
- Job-Particular Optimization: Builders can use
task_typeparameters (comparable toRETRIEVAL_QUERY,RETRIEVAL_DOCUMENT, orCLASSIFICATION) to offer hints to the mannequin. This optimizes the vector’s mathematical properties for the precise operation, bettering the “hit price” in semantic search.
Take a look at Technical particulars, in Public Preview by way of the Gemini API and Vertex AI. Additionally, be happy to comply with us on Twitter and don’t neglect to hitch our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be part of us on telegram as properly.











{kind=link}