Most search brokers are educated as insurance policies over a rising transcript. The mannequin decides how one can search. It should additionally keep in mind what it noticed, which proof issues, and which claims it checked. A workforce of researchers from College of Illinois Urbana-Champaign, UC Berkeley, and Chroma argues this asks an excessive amount of. Reinforcement studying finally ends up optimizing each search selections and routine bookkeeping without delay.
Their reply is Harness-1, a 20B retrieval subagent constructed on gpt-oss-20b. It was educated with reinforcement studying inside a stateful search harness. The harness holds the bookkeeping. The coverage retains the semantic selections. The weights and harness code are publicly launched.
What’s Harness-1 Really
Harness-1 produces a ranked set of paperwork for a downstream answering mannequin. It doesn’t reply questions itself. It runs inside a state-machine harness centered on a per-episode WORKINGMEMORY.
Every flip works as a loop. The harness renders compact search state together with latest actions. The mannequin emits one structured motion. The harness executes it, updates state, and renders the subsequent statement.
The Stateful Harness: What Strikes Out of the Coverage
The analysis workforce calls its precept stateful cognitive offloading. The coverage decides what to look, curate, and confirm, and when to cease. The harness maintains the recoverable state round these selections.
That state contains a number of items. A candidate pool holds compressed, deduplicated paperwork. An importance-tagged curated set is the ultimate output, capped at 30 paperwork. Tags take 4 values: very_high, excessive, truthful, or low. A full-text retailer retains each retrieved chunk exterior the immediate.
An proof graph provides construction. A regex extractor scans every chunk for correct nouns, years, and dates. The harness then renders frequent entities, bridge paperwork, and singletons. Bridge paperwork comprise two or extra frequent entities. Singletons seem in a single doc and recommend follow-up leads.
The coverage works via eight instruments. These are fan_out_search, search_corpus, grep_corpus, read_document, review_docs, curate, confirm, and end_search. Search outputs are compressed with sentence-BM25, conserving the highest 4 sentences. Two-level deduplication removes repeats by chunk ID and content material fingerprint.
One design selection addresses chilly begins. The primary profitable search auto-seeds the curated set with eight reranked outcomes at truthful significance. The coverage then promotes sturdy paperwork and removes weak ones. This turns the duty from constructing from scratch into refinement.
The analysis workforce names three necessities for a trainable harness. These are warm-started curation, compact derived-state rendering, and diversity-preserving incentives. Harness-1 implements all three.
How It’s Educated
Coaching splits alongside the identical line because the harness. Supervised fine-tuning teaches the mannequin to function the interface. Reinforcement studying improves search selections over the maintained state.
A single instructor, GPT-5.4, runs stay inside the total harness. After filtering, 899 trajectories stay for SFT. The mannequin makes use of LoRA at rank 32 for 3 epochs. The step-550 checkpoint initializes RL.
RL makes use of on-policy CISPO with a 40-turn cap and terminal-only reward. It trains solely on SEC queries. Teams with an identical rewards are dropped from the gradient. Coaching ran on Tinker.
The reward separates discovery from choice. It additionally provides a tool-diversity bonus. With out that bonus, the agent collapses to repeated search. Curated recall then plateaus close to 0.53. With the bonus, range stabilizes and recall reaches about 0.60.
The Benchmark Case
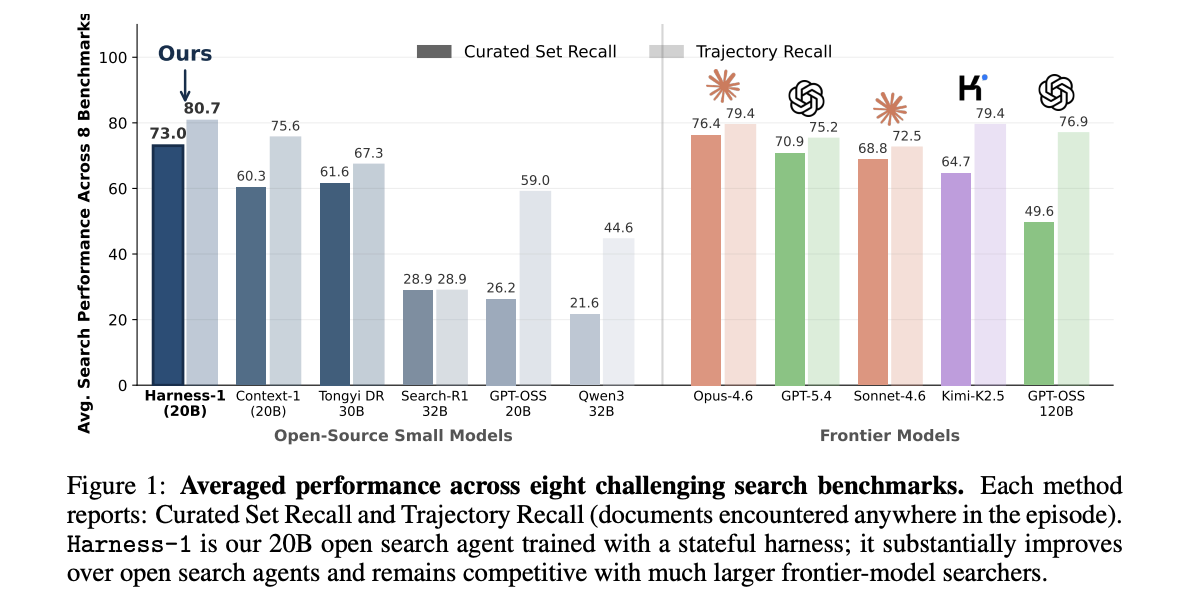
Harness-1 was evaluated on eight benchmarks spanning net, finance, patents, and multi-hop QA. The principle metric is curated recall: protection of related paperwork within the closing set. Trajectory recall counts proof encountered anyplace within the episode.
| Mannequin | Sort | Avg Curated Recall | Avg Trajectory Recall |
|---|---|---|---|
| Harness-1 (20B) | Open small | 0.730 | 0.807 |
| Tongyi DeepResearch 30B | Open small | 0.616 | 0.673 |
| Context-1 (20B) | Open small | 0.603 | 0.756 |
| Search-R1 (32B) | Open small | 0.289 | 0.289 |
| GPT-OSS-20B | Open small | 0.262 | 0.590 |
| Qwen3 (32B) | Open small | 0.216 | 0.446 |
| Opus-4.6 | Frontier | 0.764 | 0.794 |
| GPT-5.4 | Frontier | 0.709 | 0.752 |
| Sonnet-4.6 | Frontier | 0.688 | 0.725 |
| Kimi-K2.5 | Frontier | 0.647 | 0.794 |
| GPT-OSS-120B | Frontier | 0.496 | 0.769 |
Harness-1 reaches 0.730 common curated recall. That beats the subsequent open subagent, Tongyi DeepResearch 30B, by 11.4 factors. Among the many frontier searchers examined, solely Opus-4.6 scores increased on common.
The switch sample is the clearest sign of the mechanism. SFT used 4 benchmark households; RL used solely SEC. On these source-family duties, Harness-1 gained 7.9 factors over the closest open baseline. On 4 held-out benchmarks, it gained 17.0 factors. That could be a 2.2x bigger acquire on duties furthest from coaching knowledge.
Ablations assist the harness declare. Disabling all harness mechanisms drops Recall by 12.2 % relative on BrowseComp+. The educated coverage retains looking however can not rank what it sees.

Use Instances
The tactic targets evidence-seeking retrieval the place paperwork assist a solution. A number of workflows match this form.
One is literature and patent evaluate. The proof graph and curated set assist set up many sources. One other is financial-filing evaluation. The SEC case examine recovers an actual executive-transition date throughout a number of 8-Ks.
A 3rd is multi-hop fact-checking. The fan_out_search and confirm instruments resolve ambiguous entities earlier than committing. A fourth is modular RAG. The curated set feeds a frozen generator, and higher units yield increased reply accuracy.
Strengths and Weaknesses
Strengths
- Highest common curated recall among the many open fashions examined, and behind solely Opus-4.6 total.
- Good points maintain on held-out benchmarks, suggesting domain-general search operations.
- Educated on 4,352 distinctive gadgets, far fewer than a number of baselines.
- Open checkpoint and harness code, servable with widespread runtimes.
Weaknesses
- The proof graph makes use of regex extraction, not full entity linking.
- The confirm software is an LLM proxy that may err on ambiguous claims.
- Sentence-BM25 compression could drop context tied to discourse construction.
- The analysis workforce reviews level estimates with out full confidence intervals.
Key Takeaways
- Harness-1 is a 20B search agent that strikes search bookkeeping into the setting, leaving semantic selections to the coverage.
- It hits 0.730 common curated recall throughout eight benchmarks, beating the subsequent open subagent by 11.4 factors.
- Among the many searchers examined, solely Opus-4.6 scores increased on common curated recall.
- Good points are largest on held-out benchmarks (+17.0 vs +7.9 factors), suggesting the realized search operations switch.
- Weights and harness code are public, servable through vLLM, SGLang, or Transformers.
Marktechpost’s Visible Explainer
Stateful Search Brokers
1 / 7
Take a look at the Paper, Mannequin weights and GitHub Repo. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 150k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be a part of us on telegram as nicely.
Must companion with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and many others.? Join with us












{kind=link}