Introduction
Picture recognition lets computer systems establish objects, individuals, textual content, and scenes inside digital pictures and video frames. This functionality now sits inside telephones, automobiles, hospitals, factories, and the social apps that billions of individuals open each day. The worldwide laptop imaginative and prescient market that powers it was valued at 19.82 billion {dollars} in 2024, in line with Grand View Analysis market evaluation. That very same determine is projected to succeed in 58.29 billion {dollars} by 2030, a transparent signal of how briskly visible machine intelligence is spreading. Most individuals use picture recognition dozens of instances a day with out ever seeing the equipment that makes it potential. This information opens that black field and explains how the expertise works, one step at a time, in plain language. You will note the info, the mathematics, the mannequin architectures, and the true techniques that flip uncooked pixels into assured choices.
Fast Solutions on How Picture Recognition Works
What’s picture recognition in easy phrases?
Picture recognition is software program that appears at an image and names what it incorporates. It converts pixels into numbers, finds discovered patterns in these numbers, and outputs labels comparable to cat, tumor, or cease signal with a confidence rating.
How does picture recognition really work?
A educated neural community scans the picture, detects edges and textures in early layers, and combines them into shapes and objects in deeper layers. It then maps these options to the most certainly class it discovered throughout coaching.
Is picture recognition the identical as laptop imaginative and prescient?
No. Picture recognition is one job inside laptop imaginative and prescient. Pc imaginative and prescient is the broader discipline, which additionally covers detection, monitoring, segmentation, and three dimensional scene understanding throughout each nonetheless photos and video.
Key Takeaways
- Picture recognition turns uncooked pixels into labeled that means by passing photos by way of educated neural networks that discovered from hundreds of thousands of examples.
- Convolutional neural networks and newer imaginative and prescient transformers do the heavy lifting, studying visible options as an alternative of relying available written guidelines.
- Accuracy relies upon closely on the amount, high quality, and stability of the labeled coaching information behind the mannequin.
- The identical core technique powers medical prognosis, self driving automobiles, retail checkout, content material moderation, and biometric safety worldwide.
What Is Picture Recognition in Trendy AI
Picture recognition is the power of a pc system to detect and classify objects, faces, textual content, or scenes inside a digital picture. It makes use of educated neural networks to transform pixels into numerical options, examine these options in opposition to discovered patterns, and output labels with confidence scores.
Interactive
Picture recognition accuracy simulator
Regulate the coaching situations and watch how a picture recognition mannequin’s anticipated accuracy and prediction confidence reply.
Estimated top-1 accuracy
0%
Pattern prediction confidence
The Constructing Blocks Behind Machine Imaginative and prescient
Each digital picture is a grid of tiny squares referred to as pixels, and every pixel shops numbers that describe coloration and brightness. A coloration photograph normally holds three numbers per pixel, one every for pink, inexperienced, and blue depth. A single excessive decision {photograph} can include a number of million of those numeric values organized in a neat rectangle. To a pc, a picture is subsequently not an image in any respect however a big desk of numbers ready to be analyzed. Picture recognition begins with this straightforward reality: a photograph is information, and information may be measured, in contrast, and discovered from. The entire discipline of laptop imaginative and prescient and why it issues rests on turning these uncooked numbers into helpful that means.
Early imaginative and prescient software program tried to search out objects utilizing hand written guidelines about edges, corners, and coloration thresholds. Engineers would manually describe what a face or a automobile ought to appear to be in pixel phrases. These rule based mostly techniques had been brittle and broke every time lighting, angle, or background modified even barely. They might not address the infinite number of the true visible world. The breakthrough got here when researchers let machines study the principles themselves from labeled examples as an alternative of coding them by hand.
This shift moved picture recognition from fragile handcrafted logic to versatile discovered fashions. As a substitute of telling the pc what a cat seems like, engineers now present it 1000’s of cat pictures and let it infer the sample. The mannequin discovers which combos of pixels reliably sign every class. That discovered data generalizes much better than any rule an individual might write. This information pushed method is the muse of each trendy recognition system in use at present.
How Neural Networks Study to See
The engine inside trendy picture recognition is the substitute neural community, defined in depth right here. A neural community is a stack of mathematical layers loosely impressed by the way in which neurons join within the mind. Every layer receives numbers, multiplies them by adjustable weights, and passes the consequence ahead. Throughout coaching, the community compares its guesses to the right labels and measures the error. It then nudges each weight barely to scale back that error, a course of repeated hundreds of thousands of instances. Studying to see, for a machine, means tuning hundreds of thousands of numbers till the precise reply turns into the most certainly output.
This tuning technique is known as backpropagation paired with gradient descent. The community flows a picture ahead to make a prediction, then flows the error backward to assign blame to every weight. Over many cycles, helpful patterns get strengthened and ineffective ones fade away. The identical precept underpins all of how deep studying works, the place many stacked layers construct wealthy representations. With sufficient information and computation, these networks attain accuracy that older strategies by no means approached.
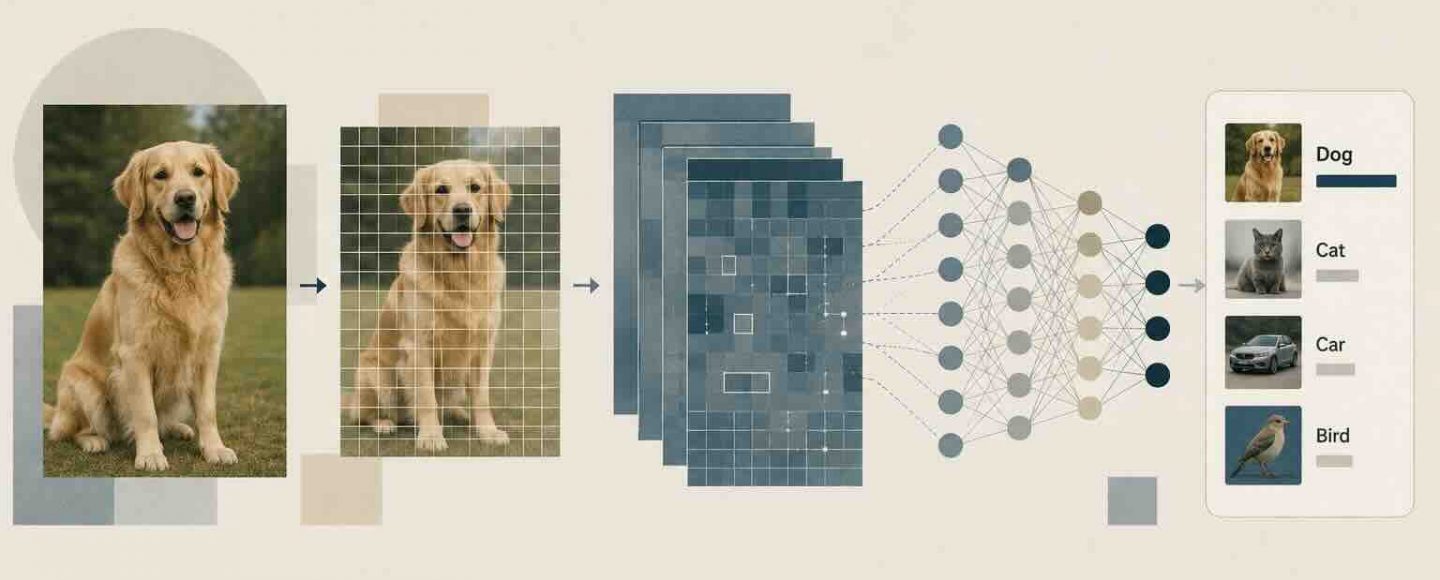
The Step by Step Pipeline of Recognizing an Picture
Constructing on that studying precept, it helps to hint a single picture by way of the complete recognition pipeline. The journey begins the second a digicam or file delivers uncooked pixels to the system. Every stage transforms the info a little bit extra till a readable label seems on the finish. Understanding this move demystifies what can really feel like magic. The pipeline is remarkably constant throughout most picture recognition merchandise you encounter.
The primary stage is preprocessing, the place the picture is resized, cropped, and normalized to an ordinary format. Pixel values are sometimes scaled right into a small numeric vary so the community trains extra stably. Some techniques additionally increase the info by flipping, rotating, or recoloring photos to enhance robustness. This cleansing step ensures each enter arrives in a form the mannequin expects. Skipping it normally causes accuracy to break down on actual world pictures.
The second stage is function extraction, the place the community detects edges, textures, and shapes throughout the picture. Early layers spot easy traces and coloration modifications, whereas deeper layers assemble them into eyes, wheels, or letters. This hierarchy of options is what lets a mannequin acknowledge a face whether or not it seems massive, small, tilted, or partly hidden. The extracted options turn into a compact numerical abstract of the image. That abstract carries much more that means than the uncooked pixels did.
The ultimate stage is classification, the place the mannequin maps the function abstract to class scores. A operate referred to as softmax turns these scores into possibilities that add as much as a hundred percent. The label with the best likelihood turns into the prediction, together with a confidence worth. If the highest rating is low, effectively designed techniques flag the consequence as unsure. This staged design seems in almost each information to picture recognition for good purpose.
Convolutional Neural Networks on the Core
Turning to the core structure, the convolutional neural community has for over a decade been the workhorse of picture recognition. A convolutional neural community, or CNN, slides small filters throughout a picture to detect native patterns. Every filter learns to fireplace when it meets a selected function, comparable to a vertical edge or a patch of fur. As a result of the identical filter scans the entire picture, the community acknowledges a function irrespective of the place it sits. This property, referred to as translation invariance, makes CNNs each environment friendly and highly effective. The CNN solved the central puzzle of imaginative and prescient by studying reusable visible filters as an alternative of memorizing mounted pixel positions.
A CNN stacks many convolution layers, every constructing on the options discovered by the layer under. Between them sit pooling layers that shrink the info whereas preserving an important alerts. This gradual compression turns an enormous pixel grid right into a small, that means wealthy vector. The deeper the stack, the extra summary the discovered ideas turn into. By the ultimate layers, neurons might reply to complete objects like canines, bridges, or avenue indicators.
The 2012 mannequin AlexNet proved how far this design might go by crushing a significant benchmark. It minimize the highest 5 error charge on the ImageNet contest to about 15.3 %, a dramatic leap reported on the ImageNet leaderboard. That consequence triggered the deep studying increase that also drives the sector. Later networks comparable to ResNet pushed accuracy even larger with a whole lot of layers. CNNs stay a reliable selection for a lot of manufacturing recognition duties.
Coaching Knowledge and Why Labels Matter
Past the structure itself, no recognition mannequin is healthier than the info used to show it. A community learns solely the patterns current in its coaching photos, so gaps within the information turn into gaps within the mannequin. The well-known ImageNet dataset incorporates over fourteen million hand labeled photos throughout 1000’s of classes. That scale is what allowed fashions to study the wealthy visible vocabulary they now possess. In picture recognition, fastidiously labeled information is the true supply of intelligence, not the algorithm alone.
Labeling is gradual, pricey, and straightforward to get improper, which is why picture annotation for laptop imaginative and prescient is a self-discipline of its personal. A single mislabeled batch can educate the mannequin the improper lesson at scale. Balanced information additionally issues, since a mannequin educated totally on daytime pictures struggles at evening. Groups now make investments closely in cleansing, auditing, and diversifying their datasets. High quality information work usually beats intelligent structure tweaks for actual accuracy positive factors.
From Classification to Detection and Segmentation
Past easy labeling, picture recognition branches into a number of associated duties of rising problem. Plain classification solutions one query: what’s the major topic of this picture. Object detection goes additional by drawing packing containers round each merchandise and naming each. Segmentation is extra exact nonetheless, labeling every particular person pixel as a part of a selected object. These duties construct on the identical function extraction spine however add completely different output heads.
Detection fashions just like the YOLO household scan a picture as soon as and predict many packing containers in a single cross. This velocity makes them sensible for stay video, robotics, and visitors monitoring. Segmentation networks as an alternative produce an in depth masks that traces object outlines precisely. Medical and satellite tv for pc imaging depend on this pixel degree precision for measurement and planning. This overview of AI in picture and video recognition maps the broader discipline clearly for brand spanking new readers.
Selecting the best job shapes the price, velocity, and information wants of a undertaking. Classification is least expensive and wishes solely picture degree labels to coach. Detection and segmentation demand much more detailed annotation and heavier computation. Selecting the best job that solves the true drawback is among the most beneficial choices in any imaginative and prescient undertaking. Many groups waste months constructing segmentation when fundamental classification would have sufficed.
Imaginative and prescient Transformers and the New Architectures
Past convolutional designs, a more moderen method referred to as the imaginative and prescient transformer has reshaped the sector since 2020. A imaginative and prescient transformer splits a picture into small patches and treats every patch like a phrase in a sentence. It then makes use of an consideration mechanism to weigh how each patch pertains to each different patch. This world view helps the mannequin join distant components of a scene {that a} CNN would possibly miss. Imaginative and prescient transformers introduced the language mannequin revolution into picture recognition, usually surpassing CNN accuracy when educated on very massive datasets.
Transformers are information hungry and want large coaching units to succeed in their full power. On smaller datasets, a effectively tuned CNN can nonetheless match or beat them at decrease value. Many latest techniques mix each concepts, utilizing convolution for native element and a spotlight for world context. This hybrid pattern displays the broader story of AI and laptop imaginative and prescient shaping visible recognition. The sector now gives a toolbox of architectures relatively than one winner.
Measuring Accuracy and Mannequin Efficiency
With fashions in hand, groups want sincere methods to measure how effectively it acknowledges photos. Uncooked accuracy, the share of right predictions, is the best metric however it might mislead. A mannequin that all the time guesses the most typical class can rating excessive whereas being ineffective. For that purpose, engineers additionally monitor precision, recall, and the mixed F1 rating. These metrics reveal whether or not a system misses actual objects or raises too many false alarms.
Benchmarks give the sector a shared yardstick for evaluating picture recognition fashions pretty. The ImageNet problem stays probably the most cited take a look at, the place high fashions now exceed ninety % high one accuracy on the public ImageNet benchmark. That determine has climbed steadily from the AlexNet period barely a decade in the past. Trendy recognition techniques now match or beat common human accuracy on many slim visible duties. Benchmarks should nonetheless be learn with care, since lab scores not often match messy actual situations.
A mannequin can ace a benchmark and nonetheless fail in deployment as a result of actual photos differ from clear take a look at units. Lighting, movement blur, odd angles, and unfamiliar objects all degrade efficiency. This hole is why groups take a look at on information that mirrors their precise working surroundings. In addition they monitor stay predictions to catch drift because the world modifications over time. Steady analysis, not a single launch rating, defines a reliable system.
Confidence scores add one other layer of nuance to efficiency judgment. A prediction at fifty one % confidence deserves far much less belief than one at ninety 9 %. Good merchandise use thresholds to defer unsure circumstances to a human reviewer. This human within the loop design prevents overconfident errors in excessive stakes settings. Measuring not simply accuracy however calibrated confidence separates protected techniques from reckless ones.
Actual World Functions Throughout Industries
Past uncooked benchmarks, the attain of picture recognition extends into virtually each main business. Hospitals use it to flag tumors, fractures, and eye illness in medical scans. Retailers use it for cashierless checkout, shelf monitoring, and theft prevention. Producers deploy it to identify tiny defects on fast-paced manufacturing traces. The breadth is seen in these purposes of laptop imaginative and prescient in on a regular basis life.
Transportation is among the most demanding arenas for visible machine intelligence. Self driving techniques should acknowledge pedestrians, indicators, and lane markings in actual time and in any climate. A single missed object can carry severe security penalties, so redundancy is inbuilt. The technical calls for are explored additional on this take a look at how self driving automobiles use AI. In security vital fields, picture recognition should be not solely correct however predictable below stress.
Shopper expertise hides recognition inside options individuals use with out pondering. Cellphone cameras detect faces to focus, type pictures, and unlock screens. Social platforms scan billions of uploads to tag pals and filter dangerous content material. Even agriculture now makes use of drones that acknowledge crop illness from the air. The identical underlying technique, discovered visible options, powers all of those very completely different merchandise.
Placing Picture Recognition Into Manufacturing
Shifting on to deployment, turning a educated mannequin right into a stay product introduces recent challenges. A community that runs quick on a analysis server could also be too heavy for a cellphone or digicam. Engineers compress fashions by way of pruning, quantization, and distillation to shrink them. These strategies minimize measurement and velocity up inference whereas preserving accuracy acceptable. The purpose is a mannequin sufficiently small to run the place the pictures are literally captured.
Groups should additionally resolve the place the popularity runs, within the cloud or on the gadget. Cloud processing gives extra energy however provides delay, value, and privateness considerations. On gadget processing retains information native and responds immediately however limits mannequin measurement. Many merchandise cut up the work, dealing with easy circumstances domestically and arduous circumstances remotely. This stability connects on to broader questions of how AI works in actual techniques.
Manufacturing techniques want monitoring, retraining, and clear fallback conduct when confidence drops. Actual world inputs drift, so a mannequin correct at launch can decay inside months. Robust pipelines log predictions, pattern errors, and feed corrections again into coaching. A deployed picture recognition mannequin is a dwelling service that wants upkeep, not a completed artifact. Treating it as set and overlook is a standard and dear mistake.
The Dangers and Limits of Visible AI
Regardless of the progress thus far, picture recognition carries actual dangers that deserve sober consideration. Fashions may be fooled by adversarial examples, tiny pixel modifications invisible to people that flip a prediction. A cease signal with just a few stickers may be misinterpret as a velocity restrict signal by a weak system. These assaults present that machine sight doesn’t work the way in which human sight does. A picture recognition mannequin may be extraordinarily correct and nonetheless fragile in ways in which shock its builders.
Fashions additionally fail silently once they meet objects or situations absent from coaching. A medical system educated in a single hospital might falter on one other scanner model. Overconfidence compounds the hazard, because the mannequin might report excessive certainty whereas being improper. These limits are why vital deployments maintain people within the resolution loop. Understanding the distinction between deep studying versus machine studying helps groups set sensible expectations.
Bias, Privateness, and the Ethics of Machine Sight
Past technical limits, moral questions sit on the coronary heart of how picture recognition is constructed and used. Facial evaluation techniques have proven massive accuracy gaps throughout pores and skin tone and gender teams. Authorities testing by america requirements company documented these disparities clearly in its Face Recognition Vendor Take a look at program. Biased information produces biased fashions, which may trigger actual hurt in policing or hiring. Equity in picture recognition will not be computerized and should be engineered, examined, and audited intentionally.
Privateness is the second main concern raised by widespread visible evaluation. Cameras that acknowledge faces can monitor individuals throughout cities with out their data or consent. A number of jurisdictions have restricted public facial recognition in response to those fears. The talk over surveillance touches the identical nerves explored in writing on whether or not AI can acknowledge faces. Robust governance and consent guidelines at the moment are important components of accountable deployment.
Transparency and accountability spherical out the moral image for visible AI. Customers need to know when a recognition system judges them and easy methods to contest its output. Explainability instruments that spotlight which pixels drove a choice assist construct that belief. Clear documentation of coaching information and recognized limits helps sincere use. Ethics right here will not be a barrier to progress however a situation for lasting adoption.
The Historical past That Led to Trendy Picture Recognition
Constructing on the architectures already described, the story of how machines discovered to see spans seven many years. The earliest spark was the Perceptron of 1958, a easy studying machine that would separate fundamental patterns. Progress stalled for years as a result of computer systems had been weak and labeled information was scarce. A Japanese mannequin referred to as the Neocognitron in 1980 launched layered function detection that prefigured trendy networks. In 1998 a community named LeNet learn handwritten digits on financial institution checks at scale. These early techniques proved the core concept however couldn’t but deal with advanced pure photos. Every milestone added one lacking piece, and solely their mixture unlocked dependable picture recognition.
The trendy period started in 2012 when AlexNet gained the ImageNet contest by a large margin. Its victory confirmed that deep networks plus graphics processors plus huge information might beat older strategies. In 2015 a design referred to as ResNet launched skip connections that allowed networks a whole lot of layers deep. That depth pushed accuracy previous human degree on the slim ImageNet job. Researchers then raced to make fashions quicker, smaller, and extra correct without delay. The tempo of enchancment in these years was in contrast to something the sector had seen.
The newest chapter arrived in 2020 with the imaginative and prescient transformer borrowed from language fashions. This design questioned whether or not convolution was even crucial for robust recognition. It handled photos as sequences of patches and let consideration hyperlink them globally. The consequence reset expectations and sparked a brand new wave of hybrid designs. Understanding this lineage helps clarify why at present’s instruments behave the way in which they do. The historical past of AI as an entire mirrors this identical arc of gradual begins and sudden leaps.
Preprocessing and Knowledge Augmentation in Observe
Turning to the sensible groundwork, uncooked photos not often arrive in a type a mannequin can use straight. Pictures differ in measurement, lighting, coloration stability, and orientation throughout each supply. Preprocessing standardizes them so the community sees constant inputs each time. Engineers resize photos to a hard and fast decision and scale pixel values right into a tidy numeric vary. They could additionally crop, middle, or right coloration earlier than coaching begins. This unglamorous step usually decides whether or not a mannequin succeeds or fails. Clear, constant inputs are the quiet basis of correct picture recognition.
Past cleansing, groups intentionally develop their information by way of augmentation. They flip, rotate, zoom, and recolor present photos to create new coaching variations. This trick teaches the mannequin {that a} cat remains to be a cat when mirrored or dimmed. A handful of strategies for information augmentation in machine studying can multiply an efficient dataset many instances over. Augmentation additionally reduces overfitting, the place a mannequin memorizes coaching pictures as an alternative of studying common patterns. The payoff is a system that holds up higher on photos it has by no means seen.
Switch Studying and Pretrained Fashions
Past coaching from scratch, most groups now begin from a mannequin that already is aware of easy methods to see. Switch studying takes a community educated on hundreds of thousands of common photos and adapts it to a brand new job. The pretrained mannequin already understands edges, textures, and customary shapes. Engineers change solely its last layers and retrain on a smaller, particular dataset. This method cuts information wants and coaching time dramatically. A information to switch studying in machine studying reveals why it grew to become the default place to begin. Switch studying made robust picture recognition potential even for groups with little information.
The economics of switch studying are arduous to overstate for smaller organizations. Coaching a high mannequin from zero can break the bank in computing and labeled information. Ranging from a pretrained spine shrinks that value to a fraction. A medical startup can fine-tune a common imaginative and prescient mannequin on just a few thousand scans. The mannequin arrives already fluent in fundamental visible options it might in any other case relearn. This reuse is one purpose recognition unfold so shortly throughout industries.
Switch studying will not be a free lunch in each scenario. When the brand new photos differ wildly from the unique coaching set, positive factors shrink. Medical scans, satellite tv for pc pictures, and microscopy can confuse a mannequin educated on on a regular basis footage. Groups then fine-tune extra layers or collect extra area information to compensate. Understanding when switch helps and when it hurts is a core sensible ability. The method stays a strong shortcut when utilized with judgment.
Optical Character Recognition and Studying Textual content
Past naming objects, picture recognition additionally reads textual content printed or written in footage. This department is known as optical character recognition, and it converts photos of phrases into editable textual content. Banks use it to course of checks, and apps use it to scan receipts and paperwork. Trendy techniques deal with messy handwriting, pale print, and curved surfaces with rising ability. A sensible breakdown of how OCR expertise works reveals the pipeline intimately. This department of imaginative and prescient turns pictures of textual content into information that software program can search and retailer.
Early OCR relied on inflexible template matching that broke on uncommon fonts. Deep studying changed these brittle guidelines with fashions educated on large text-image collections. These networks acknowledge complete phrases and even full traces in context. They address rotation, glare, and background litter much better than older instruments. Multilingual help has expanded to a whole lot of scripts and alphabets. The result’s dependable textual content seize from virtually any photographed web page.
OCR nonetheless struggles with really degraded or stylized enter. Handwriting from completely different individuals varies enormously, and a few scripts stay underserved by coaching information. Errors in a single digit can corrupt a whole bill or medical document. For that purpose, delicate workflows route low-confidence reads to human checkers. Combining OCR with language fashions now helps right apparent errors routinely. The expertise retains closing the hole between printed pages and structured information.
Generative Fashions and Artificial Coaching Knowledge
Shifting to a more moderen trick, groups now generate pretend photos to coach recognition techniques. When actual labeled information is scarce, artificial photos can fill the hole. Generative adversarial networks pit two fashions in opposition to one another to supply sensible footage. An introduction to generative adversarial networks explains how this rivalry sharpens output high quality. These artificial photos can present uncommon defects, uncommon angles, or harmful scenes safely. Coaching on them helps a mannequin deal with conditions that seldom seem in actual information. Artificial information lets picture recognition study from occasions which are uncommon, pricey, or dangerous to seize.
Artificial information shines in fields the place actual examples are arduous to assemble. A manufacturing facility might not often produce a selected defect, but the mannequin should catch it. Self-driving groups simulate uncommon street hazards they can’t stage on public streets. Medical teams generate diversified scans whereas defending affected person privateness. These approaches develop protection with out ready years for uncommon occasions. Used effectively, artificial information enhances relatively than replaces actual photos.
Picture Recognition on Edge Units and Telephones
Shifting on to the place fashions really run, a lot recognition now occurs on the gadget itself. Your cellphone identifies faces, scans paperwork, and kinds pictures with out sending them to a server. Operating on the sting retains information personal and delivers immediate outcomes. The function behind how Google AI analyzes your pictures reveals this shift in motion. Specialised chips inside trendy telephones run neural networks effectively and quietly. This native processing has made imaginative and prescient options really feel seamless and fast. On-device recognition trades some uncooked energy for privateness, velocity, and offline reliability.
Becoming a succesful mannequin onto a tiny chip calls for actual engineering. Builders prune unused connections and decrease numerical precision to shrink the community. They distill massive fashions into smaller college students that mimic the unique. These steps minimize reminiscence and battery use whereas preserving most accuracy. The purpose is a mannequin that responds in milliseconds on modest {hardware}. This self-discipline now drives an entire subfield of environment friendly imaginative and prescient.
Edge recognition additionally unlocks makes use of that the cloud can not serve. A drone inspecting a distant pipeline might haven’t any community in any respect. A manufacturing facility digicam should react quicker than a spherical journey to a knowledge middle permits. Native fashions maintain working throughout outages and shield delicate footage. The tradeoff is a ceiling on mannequin measurement and complexity. Designers stability that restrict in opposition to the advantages of staying on the gadget.
Recognizing Movement and Objects in Video
transferring footage, video provides the dimension of time to recognition. A video is solely a quick stream of nonetheless frames, usually thirty per second. The identical fashions can label every body, however movement carries additional that means. Monitoring hyperlinks an object throughout frames so the system is aware of it’s the identical automobile. Recurrent designs and their successors assist fashions keep in mind context over time, and recurrent neural networks had been an early device for this. Motion recognition then identifies occasions like a fall, a purpose, or a collision. Video evaluation reads not simply what’s current however the way it strikes and modifications.
Processing video is much heavier than dealing with single pictures. Thirty frames per second means thirty instances the info of 1 picture. Sensible techniques skip redundant frames and focus computation the place movement happens. They cache options so unchanged areas usually are not analyzed twice. These efficiencies make stay video evaluation sensible on actual {hardware}. Sports activities, safety, and visitors techniques all rely on this velocity.
Temporal context additionally helps repair errors a single body would make. A blurred object in a single body could also be clear within the subsequent. By combining frames, the system corrects flickering or unsure labels. This smoothing reduces false alarms in safety and driving purposes. The identical context can even confuse fashions when scenes change abruptly. Designers tune how a lot historical past every system ought to belief.
The {Hardware} Engine Behind Machine Imaginative and prescient
Stepping again from software program, none of this works with out highly effective {hardware}. Graphics processing items, or GPUs, carry out the huge parallel math that neural networks require. A contemporary GPU runs 1000’s of small calculations without delay, completely suited to picture information. This uncooked throughput is why coaching that after took months now takes days. Corporations like NVIDIA and Intel construct chips tuned for imaginative and prescient workloads. The connection between how synthetic intelligence works and its {hardware} is tight and inseparable. The deep studying increase was as a lot a {hardware} story as a software program one.
Specialised accelerators now push efficiency even additional. Tensor cores and devoted imaginative and prescient chips deal with recognition with much less energy. Cloud suppliers lease this {hardware} so small groups can prepare massive fashions. Edge chips convey a slice of that energy to telephones and cameras. This unfold of succesful silicon lowered the barrier to constructing imaginative and prescient techniques. {Hardware} progress and mannequin progress now feed one another constantly.
Explainability and Belief in Visible Fashions
Given the stakes, individuals more and more ask why a mannequin made a given name. Picture recognition fashions are famously opaque, providing a label however no purpose. Explainability instruments open that field by displaying which pixels drove a choice. Warmth maps spotlight the areas a mannequin centered on for its prediction. The softmax layer that turns scores into possibilities is described on this take a look at the softmax operate in neural networks. These instruments assist engineers catch when a mannequin depends on the improper cues. Explainability turns a black field prediction into proof a human can really test.
Explanations matter most in high-stakes settings like medication and regulation. A physician must know whether or not a mannequin flagged a tumor or a scanner artifact. A warmth map that factors on the lung, not the label textual content, builds justified belief. Regulators more and more anticipate this sort of proof earlier than approval. With out it, a assured improper reply can do actual harm. Transparency is changing into a requirement, not a luxurious.
Present rationalization strategies stay imperfect and generally deceptive. A warmth map can look affordable whereas hiding a deeper flaw within the mannequin. Completely different instruments can disagree about what mattered for a similar prediction. Researchers warn in opposition to treating these visuals as full proof. They’re helpful clues, not full accounts of mannequin reasoning. Sincere groups current them with applicable warning.
Sensor Fusion Past the Digital camera
For groups in demanding fields, cameras alone are sometimes not sufficient. Self-driving automobiles mix picture recognition with radar, ultrasound, and laser scanning. Lidar builds a exact three-dimensional map {that a} flat photograph can not present, and its position seems on this information to lidar in robotic imaginative and prescient. Merging these alerts is known as sensor fusion, and it fills the gaps every sensor leaves. A digicam sees coloration and textual content, whereas lidar measures actual distance. Collectively they produce a richer, safer image of the world. Sensor fusion pairs picture recognition with depth and movement information for a lot better reliability.
Every sensor has strengths and weaknesses that fusion balances. Cameras fail in darkness, whereas radar and lidar work in low gentle. Lidar struggles in heavy rain or fog, the place radar nonetheless performs. Combining them means a failure in a single channel doesn’t blind the entire system. This redundancy is crucial for safety-critical machines. The fused result’s extra sturdy than any single sensor alone.
Fusion provides complexity that groups should fastidiously handle. Completely different sensors seize information at completely different charges and should be aligned in time. Conflicting readings must be reconciled by the software program. Additional sensors additionally increase value, weight, and energy calls for. Designers weigh these burdens in opposition to the security positive factors fusion delivers. For autonomous techniques, the added reliability normally justifies the hassle.
The Way forward for Picture Recognition
Wanting forward, picture recognition is merging with language and reasoning in highly effective new methods. Multimodal fashions now describe photos in sentences, reply questions on pictures, and comply with visible directions. This fusion lets a single system each see a scene and clarify what it means. The road between recognition and broader understanding is blurring quick. These advances construct on the foundations of synthetic intelligence as an entire.
Effectivity is the opposite frontier shaping the approaching years of visible AI. Researchers are shrinking fashions so succesful recognition can run on low cost, low energy chips. This pattern will unfold good imaginative and prescient into sensors, wearables, and distant units in every single place. Self supervised studying can also be lowering the necessity for pricey hand labeling. The following decade of picture recognition might be outlined as a lot by effectivity and reasoning as by uncooked accuracy.
Our World in Knowledge fashion chart
The pc imaginative and prescient market powering picture recognition
International laptop imaginative and prescient market worth, in USD billions, the engine behind trendy picture recognition techniques.
Key Insights on Picture Recognition
- The pc imaginative and prescient market behind picture recognition, price 19.82 billion {dollars} in 2024 per Grand View Analysis figures, ought to attain 58.29 billion by 2030.
- Main fashions now exceed 90 % top-one accuracy on the thousand-category ImageNet benchmark, a milestone unthinkable earlier than deep studying remodeled imaginative and prescient after 2012.
- A Google deep studying system flagged diabetic retinopathy with 90.3 % sensitivity and 98.1 % specificity in a landmark JAMA examine of retinal pictures.
- Federal testing within the NIST Face Recognition Vendor Take a look at discovered some algorithms misidentify sure teams at false-positive charges as much as 100 instances larger.
- The Stanford CheXNet mannequin discovered to detect pneumonia and 13 different situations from chest X-rays, reaching radiologist-level accuracy on a 112,120-image dataset.
- Amazon constructed cashierless shops, detailed in its Simply Stroll Out overview, the place ceiling cameras acknowledge each merchandise customers seize and take away checkout totally.
- A broadly cited adversarial assault examine confirmed that small stickers can idiot a road-sign classifier in one hundred pc of managed lab trials.
These numbers inform one constant story about trendy picture recognition. Accuracy has climbed from a analysis novelty to a reliable device throughout medication, retail, and transport. But the identical techniques that rival radiologists can even misinterpret a face or a doctored signal. Market development reveals that demand is racing forward of cautious oversight. The expertise now works effectively sufficient that its limits, not its uncooked capabilities, deserve the closest consideration. Constructing reliable imaginative and prescient means pairing robust fashions with sincere testing and human judgment.
| Dimension | Picture Classification | Object Detection | Picture Segmentation |
|---|---|---|---|
| What it outputs | One label for the entire picture | Packing containers plus labels for a lot of objects | A category label for each pixel |
| Label granularity | Picture degree | Area degree | Pixel degree |
| Annotation value | Low | Medium to excessive | Very excessive |
| Compute value | Lowest | Average | Highest |
| Inference velocity | Quickest | Quick with fashions like YOLO | Slower |
| Typical metric | High-one accuracy | Imply common precision | Intersection over union |
| Frequent use case | Picture tagging | Self driving notion | Medical and satellite tv for pc imaging |
Picture Recognition in Motion Right this moment
Stanford CheXNet Reads Chest X-Rays
Researchers at Stanford educated a 121-layer convolutional community referred to as CheXNet on greater than 112,000 chest X-ray photos. The group reported that the mannequin matched or exceeded working towards radiologists at detecting pneumonia, as described on the CheXNet undertaking web page. It discovered to flag 14 completely different thoracic situations from a single scan. The system produced warmth maps displaying which lung areas drove every prediction, which helped clinician belief. Critics famous that the unique labels got here from automated textual content mining, introducing actual noise into the bottom reality. Later analyses additionally questioned whether or not the radiologist comparability absolutely mirrored actual scientific situations. The work nonetheless stands as a milestone for medical picture recognition.
Amazon Go Acknowledges Each Merchandise
Amazon deployed its Simply Stroll Out expertise in cashierless shops beginning in 2018, utilizing ceiling cameras and shelf sensors. The corporate explains in its Simply Stroll Out overview that laptop imaginative and prescient tracks which gadgets every shopper picks up. Prospects merely seize merchandise and depart, with prices utilized routinely to their account. The format eliminated checkout traces totally throughout dozens of retailer places. Reporting later revealed that round a thousand human reviewers in India helped confirm many transactions behind the scenes. Amazon scaled again the system in its bigger grocery shops throughout 2024. The episode reveals each the promise and the bounds of picture recognition at retail scale.
AlexNet Cracks the ImageNet Benchmark
In 2012 a deep convolutional community named AlexNet entered the ImageNet recognition competitors and adjusted the sector. It minimize the top-five error charge to about 15.3 %, far forward of the runner up, because the ImageNet leaderboard data. The mannequin educated on 1.2 million labeled photos utilizing two shopper graphics playing cards. Its success proved that deep studying might beat hand-engineered imaginative and prescient strategies decisively. The unique community was vulnerable to overfitting and leaned closely on dropout and information augmentation. It additionally demanded computing assets unusual for educational labs on the time. AlexNet stays the spark that lit the fashionable picture recognition period.
Picture Recognition Examined within the Actual World
Case Examine: Google Screens for Diabetic Retinopathy
Diabetic retinopathy is a number one explanation for blindness, but many areas lack sufficient eye specialists to display screen sufferers in time. Google researchers got down to ease this scarcity with an automatic screening device. They educated a deep studying mannequin on 128,000 retinal fundus photos graded by dozens of ophthalmologists, as documented within the JAMA validation examine. At a high-specificity working level the mannequin reached 90.3 % sensitivity and 98.1 % specificity. The system was later deployed in clinics in India and Thailand to widen entry to screening. Actual-world use uncovered a severe limitation, since many pictures taken in busy clinics had been rejected for poor high quality. Nurses needed to retake photos, which slowed the very workflow the device aimed to hurry up. This case reveals that lab accuracy and discipline efficiency can diverge sharply in medical picture recognition.
Case Examine: Facial Recognition Faces a Bias Reckoning
Facial recognition unfold quickly into policing and border management earlier than its accuracy throughout teams was effectively understood. Civil rights advocates warned that errors might fall erratically on ladies and folks of coloration. To measure the issue, america requirements company ran large-scale demographic checks of economic algorithms. Its Face Recognition Vendor Take a look at discovered that some techniques produced false positives for Asian and Black faces at charges as much as 100 instances larger than for white males. The findings pushed a number of cities to ban authorities use of the expertise outright. Distributors responded by retraining fashions on extra balanced information, which narrowed however didn’t erase the gaps. No less than three wrongful arrests in america have been linked to mistaken facial matches. This case stays a warning about deploying picture recognition earlier than equity is confirmed.
Case Examine: Stickers That Idiot a Signal Reader
Self-driving techniques depend on picture recognition to learn street indicators, so a misinterpret signal turns into a security drawback. Researchers needed to know whether or not attackers might trick these classifiers within the bodily world. They positioned small black and white stickers on an strange cease check in a managed examine. Their sturdy physical-world assault paper reported the modified signal was misclassified as a velocity restrict check in one hundred pc of road-test frames. The assault required no entry to the digicam or the mannequin inner code. This proved that extremely correct recognition fashions can nonetheless be brittle in opposition to easy tampering. Defenders have since explored adversarial coaching and enter filtering, although no technique absolutely closes the hole. This case underscores why safety-critical imaginative and prescient wants layered defenses relatively than blind belief in accuracy.
Frequent Questions About How Picture Recognition Works
Picture recognition is software program that identifies objects, individuals, textual content, or scenes inside digital photos. It converts pixels into numbers and matches them to patterns discovered from labeled coaching information. The output is a label with a confidence rating.
The picture is first preprocessed and resized into an ordinary format. A neural community then extracts edges, textures, and shapes throughout many stacked layers. A last layer maps these options to class possibilities and picks the most certainly label.
No, picture recognition is one job inside laptop imaginative and prescient. Pc imaginative and prescient is the broader discipline that additionally consists of detection, monitoring, and segmentation. Picture recognition focuses narrowly on naming what a picture incorporates.
Convolutional neural networks have powered most techniques for over a decade. Imaginative and prescient transformers now rival them, particularly when educated on very massive datasets. Many trendy techniques mix each approaches for velocity and accuracy.
High fashions exceed 90 % accuracy on the ImageNet benchmark. Some slim duties now match or beat common human efficiency. Accuracy nonetheless drops on messy real-world photos that differ from coaching information.
Fashions study from massive units of labeled photos, generally hundreds of thousands of examples. The information should be correct, balanced, and visually diversified. Poor or biased information straight produces poor or biased predictions.
Sure, fashions fail on unfamiliar objects, odd angles, and poor lighting. They may also be fooled by tiny adversarial modifications invisible to individuals. Excessive confidence doesn’t all the time imply the reply is right.
It powers medical scan evaluation, self-driving notion, and retail checkout. It additionally runs photograph tagging, face unlock, and content material moderation. Manufacturing and agriculture use it for inspection and monitoring.
It may be, particularly with facial recognition in public areas. Cameras can monitor individuals with out their data or clear consent. A number of areas now restrict authorities use of the expertise.
Easy classifiers may be educated in hours utilizing switch studying. Complicated customized techniques can take weeks and even months. Knowledge assortment and labeling normally eat probably the most time.
Sure, video is processed as a quick sequence of picture frames. The identical fashions analyze every body, usually many instances per second. Additional monitoring strategies comply with objects easily throughout frames.
Fashions are merging with language to explain and purpose about photos. They’re additionally shrinking to run on small, low-power units. Self-supervised studying is slicing the necessity for pricey guide labels.











{kind=link}