Researchers from Sakana AI and the College of Tokyo suggest DiffusionBlocks. It trains transformer-based networks one block at a time. Coaching reminiscence is lowered by an element of B, the place B is the variety of blocks. Efficiency is maintained throughout numerous architectures.
The Reminiscence Drawback in Neural Community Coaching
Finish-to-end backpropagation requires storing intermediate activations throughout each layer. Reminiscence consumption grows linearly with community depth. As fashions develop deeper, this turns into a major coaching bottleneck.
One current method, activation checkpointing, reduces activation reminiscence by recomputing activations on demand. Nonetheless, it doesn’t cut back reminiscence for parameters, gradients, or optimizer states. With the Adam optimizer, every layer requires reminiscence for parameters, gradients, and two optimizer states (momentum and variance). This totals 4 occasions the parameter dimension per layer, unchanged by activation checkpointing.
Block-wise coaching provides a special strategy. Partitioning a community into B blocks and coaching every independently reduces reminiscence to roughly 1/B. The discount is proportional to the variety of blocks. The problem is defining a principled native goal for every block that also produces a globally coherent mannequin.
Prior approaches like Hinton’s Ahead-Ahead algorithm and grasping layer-wise coaching depend on ad-hoc native aims. They persistently underperform end-to-end coaching and are largely restricted to classification duties.
DiffusionBlocks addresses each the theoretical hole and the restricted applicability of prior strategies.
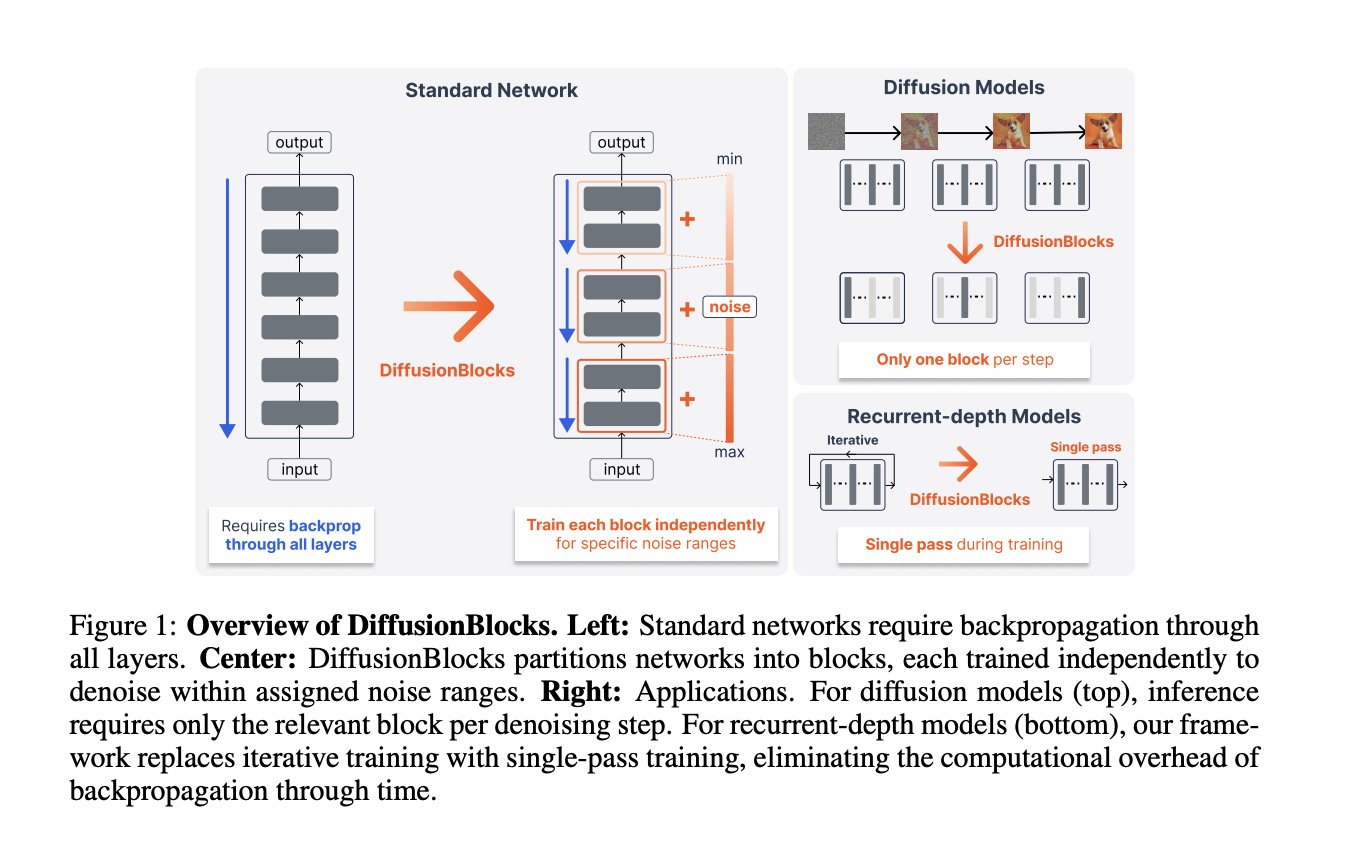
The Core Concept: Residual Connections as Euler Steps
The important thing perception builds on a longtime connection within the literature. Residual networks replace every layer enter by way of . This corresponds to Euler discretization of odd differential equations.
The analysis group present these updates correspond particularly to the chance movement ODE in score-based diffusion fashions. Within the Variance Exploding (VE) formulation, the reverse diffusion course of follows:
Making use of Euler discretization to this equation produces an replace rule that structurally matches the residual connection replace. A stack of residual blocks may be interpreted as discretized denoising steps. The steps span a noise degree vary [𝞂min, 𝞂max]
In score-based diffusion fashions, the rating matching goal may be optimized independently at every noise degree. This implies every block may be educated independently, utilizing solely its personal native goal. No inter-block communication is required throughout coaching.
Changing a Community: Three Steps
Changing a normal residual community to DiffusionBlocks requires three modifications:
- Block partitioning: Cut up the L-layer community into B blocks. Every block accommodates a contiguous group of layers.
- Noise vary task: Outline a noise distribution pnoise and a noise vary
[𝞂min, 𝞂max] - Noise conditioning: Lengthen every block’s enter to incorporate a loud model of the goal. Add noise-level conditioning by way of AdaLN (Adaptive Layer Normalization). Every block learns to foretell the clear goal from its noisy model inside its assigned noise vary.
Throughout coaching, a single block is sampled per iteration. The opposite blocks should not computed. Reminiscence consumption corresponds to L/B layers, not all L layers.
Equi-probability Partitioning
A naive uniform partition divides [𝞂min, 𝞂max]
DiffusionBlocks makes use of equi-probability partitioning as an alternative. Boundaries are chosen so every block handles precisely 1/B of the overall chance mass beneath pnoise. Blocks assigned to intermediate noise ranges obtain narrower intervals. Blocks dealing with excessive noise areas obtain wider intervals.
In ablation research on CIFAR-10 utilizing DiT-S/2, block overlap was disabled to isolate every element. Equi-probability partitioning achieved FID of 38.03 versus 43.53 for uniform partitioning (decrease is best). Each used a uniform layer distribution of [4,4,4] throughout 3 blocks.
Experimental Outcomes
The analysis group evaluated DiffusionBlocks throughout 5 architectures spanning three activity classes. All outcomes evaluate DiffusionBlocks (educated block-wise) towards the identical structure educated with end-to-end backpropagation.
| Structure | Dataset | Metric | Baseline | DiffusionBlocks | Reminiscence Discount |
|---|---|---|---|---|---|
| ViT, 12-layer, B=3 | CIFAR-100 | Accuracy (larger is best) | 60.25% | 59.30% | 3x |
| DiT-S/2, 12-layer, B=3 | CIFAR-10 | FID check (decrease is best) | 39.83 | 37.20 | 3x |
| DiT-L/2, 24-layer, B=3 | ImageNet 256×256 | FID check (decrease is best) | 12.09 | 10.63 | 3x |
| MDM, 12-layer, B=3 | text8 | BPC (decrease is best) | 1.56 | 1.45 | 3x |
| AR Transformer, 12-layer, B=4 | LM1B | MAUVE (larger is best) | 0.50 | 0.71 | 4x |
| AR Transformer, 12-layer, B=4 | OpenWebText | MAUVE (larger is best) | 0.85 | 0.82 | 4x |
| Huginn recurrent-depth | LM1B | MAUVE (larger is best) | 0.49 | 0.70 | ~10x compute |
Ahead-Ahead comparability: On CIFAR-100, the Ahead-Ahead algorithm achieved solely 7.85% accuracy beneath the identical ViT structure. This highlights the hole between ad-hoc contrastive aims and the rating matching goal utilized by DiffusionBlocks.
DiT inference effectivity: For diffusion fashions, every denoising step throughout inference prompts just one block. A 12-layer DiT with B=3 makes use of solely 4-layer evaluations per denoising step. It is a 3x inference compute discount versus working all 12 layers.
Huginn coaching: Huginn applies the identical 4-layer recurrent block recurrently. It makes use of stochastic recurrence depth averaging 32 iterations. Coaching makes use of 8-step truncated backpropagation by way of time (BPTT). DiffusionBlocks replaces this with a single ahead cross per coaching step. The Ok-iteration inference process is stored unchanged. The 32x iteration discount outweighs the 3x longer coaching schedule. DiffusionBlocks trains for 15 epochs versus Huginn’s 5 epochs. Whole compute is lowered by roughly 10x.
OpenWebText outcomes: On OpenWebText, DiffusionBlocks MAUVE was 0.82 versus 0.85. Generative perplexity beneath Llama-2 was 14.99 versus 15.05. Outcomes on this dataset had been combined, with some metrics barely worse than the baseline.
Masked diffusion partitioning: For masked diffusion fashions, block partitioning targets the masking schedule relatively than steady noise ranges. Every block handles an equal decrement within the unmasking chance alpha(t), making certain balanced parameter utilization throughout blocks.
Comparability with NoProp
NoProp is a concurrent work that makes use of a diffusion framework for backpropagation-free coaching. It’s evaluated solely on classification duties utilizing a customized CNN-based structure. It doesn’t present a process for making use of the tactic to different architectures or duties.
| Methodology | Steady-time | Block-wise | Accuracy on CIFAR-100 |
|---|---|---|---|
| Backpropagation | No | No | 47.80% |
| NoProp-DT | No | Sure | 46.06% |
| NoProp-CT | Sure | No | 21.31% |
| NoProp-FM | Sure | No | 37.57% |
| DiffusionBlocks (ours) | Sure | Sure | 46.88% |
DiffusionBlocks is the one technique combining a continuous-time formulation with block-wise coaching. It stays inside 1 proportion level of the end-to-end backpropagation baseline.
Strengths and Weaknesses
Strengths:
- Principled theoretical grounding by way of rating matching, not ad-hoc native aims
- Works throughout 5 distinct architectures with out task-specific modifications
- B× coaching reminiscence discount, proportional to the variety of blocks
- For diffusion fashions, inference compute can also be lowered by B× throughout era
- Equi-probability partitioning considerably outperforms uniform partitioning (FID 38.03 vs 43.53 on CIFAR-10)
- Replaces Ok-iteration BPTT in recurrent-depth fashions with a single ahead cross
- Blocks may be educated in parallel throughout GPUs with zero communication overhead
- Average block counts (B=2 or B=3) typically enhance FID over end-to-end coaching
Weaknesses:
- Requires matching enter and output dimensions; can not presently be utilized to U-Web-style architectures
- Validated solely on fashions educated from scratch; fine-tuning of pretrained fashions is untested
- No principled technique for choosing optimum block depend for a given structure and activity
- Provides noise conditioning overhead: aggregated wall time is 0.0543s versus 0.0507s beneath commonplace coaching
- On OpenWebText, some metrics are marginally worse than the autoregressive baseline
Marktechpost’s Visible Explainer
DiffusionBlocks · Sakana AI
ICLR 2026 · Block-wise Coaching
01 / 10
Key Takeaways
- DiffusionBlocks partitions residual networks into B independently trainable blocks, lowering coaching reminiscence by an element of B
- Residual connections in transformers map to Euler steps of the reverse diffusion course of, offering a principled native coaching goal for every block
- Equi-probability partitioning assigns equal chance mass per block, not equal noise intervals, enhancing picture era FID considerably over uniform partitioning
- Validated throughout 5 architectures: ViT, DiT, masked diffusion, autoregressive, and recurrent-depth transformers
- For recurrent-depth fashions like Huginn, replaces Ok-iteration BPTT with a single ahead cross, lowering complete coaching compute by roughly 10x
Take a look at the Analysis Paper, Repo and Technical particulars. Additionally, be happy to observe us on Twitter and don’t neglect to hitch our 150k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as effectively.
Have to associate with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and so on.? Join with us











{kind=link}