The way to Scale back LLM Inference Prices
IntroductionEach token a mannequin generates carries a worth, and at scale these pennies grow to be a critical line merchandise. ...
IntroductionEach token a mannequin generates carries a worth, and at scale these pennies grow to be a critical line merchandise. ...
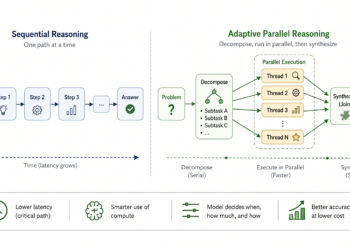
Overview of adaptive parallel reasoning. What if a reasoning mannequin may determine for itself when to decompose and parallelize impartial ...

Inference effectivity has quietly develop into one of the crucial consequential bottlenecks in AI deployment. As agentic coding methods corresponding ...
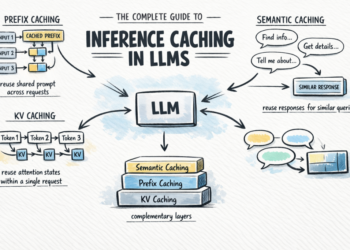
On this article, you'll learn the way inference caching works in massive language fashions and find out how to use ...
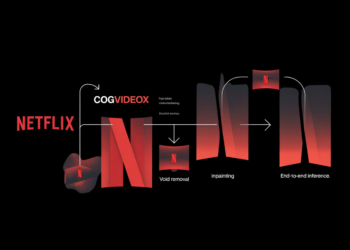
On this tutorial, we construct and run a sophisticated pipeline for Netflix’s VOID mannequin. We arrange the atmosphere, set up ...

On this tutorial, we construct and run a Colab workflow for Gemma 3 1B Instruct utilizing Hugging Face Transformers and ...

For the previous couple of years, the AI world has adopted a easy rule: if you'd like a Giant Language ...

Robots are coming into their GPT-3 period. For years, researchers have tried to coach robots ...

NVIDIA has launched Nemotron-Nano-3-30B-A3B-NVFP4, a manufacturing checkpoint that runs a 30B parameter reasoning mannequin in 4 bit NVFP4 format whereas ...
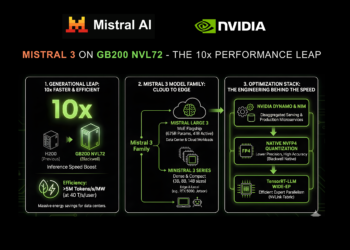
NVIDIA introduced at present a big growth of its strategic collaboration with Mistral AI. This partnership coincides with the discharge ...