The KV Cache Compression Race: TurboQuant vs OSCAR vs EpiCache
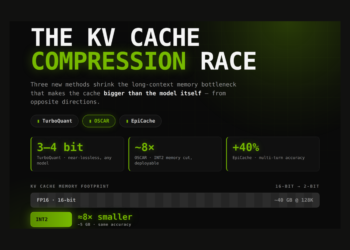
Lengthy-context giant language fashions (LLMs) face a reminiscence bottleneck that has nothing to do with mannequin weights. Throughout decoding, transformers ...
Lengthy-context giant language fashions (LLMs) face a reminiscence bottleneck that has nothing to do with mannequin weights. Throughout decoding, transformers ...


![How creators and entrepreneurs are utilizing AI to hurry up & succeed [data]](https://blog.aimactgrow.com/wp-content/uploads/2025/06/Untitled20design-Apr-07-2023-08-24-35-4586-PM-120x86.png)





