Introduction
Pure language processing permits computer systems to interpret and analyze human language. Earlier than machines can perceive textual content, nevertheless, the textual content should first be damaged into smaller items that algorithms can course of. This foundational step is called tokenization.
Tokenization converts uncooked textual content into tokens, which signify smaller segments of language reminiscent of phrases, characters, or subwords. Machine studying fashions use these tokens as the essential enter for language evaluation duties. With out tokenization, computer systems would wrestle to interpret sentences as a result of language incorporates complicated grammatical buildings and irregular spacing. Trendy synthetic intelligence techniques rely closely on tokenization when processing giant volumes of textual content. From chatbots and serps to translation instruments and suggestion techniques, tokenization permits algorithms to transform language right into a structured format that machine studying fashions can analyze.
Readers who need to perceive the broader foundations of synthetic intelligence can discover Understanding Synthetic Intelligence. The underlying machine studying ideas behind these techniques are defined additional in How Synthetic Intelligence Works
Understanding tokenization helps reveal how computer systems remodel human language into numerical information that machine studying algorithms can course of. This text was final reviewed and up to date in March 2026 to replicate how tokenization features inside giant language fashions, fashionable transformer architectures, and present AI improvement instruments.
What Is Tokenization in NLP
Tokenization in pure language processing is the method of splitting textual content into smaller items known as tokens. These tokens might signify phrases, characters, or subwords that machine studying fashions analyze when deciphering language. Tokenization permits NLP techniques to transform human language into structured information appropriate for computational evaluation.
Key Takeaways
- Tokenization breaks textual content into smaller items known as tokens that machine studying fashions can analyze.
- Tokens might signify phrases, characters, or subword fragments relying on the algorithm used.
- Trendy pure language processing techniques rely closely on tokenization earlier than performing duties reminiscent of translation or sentiment evaluation.
- Tokenization performs a vital function in giant language fashions and transformer based mostly architectures.
What Is Tokenization in Pure Language Processing
Tokenization is the method of splitting textual content into smaller items referred to as tokens. These tokens kind the essential items that pure language processing fashions analyze when deciphering language.
A token might signify a phrase, a phrase, or perhaps a character relying on how the algorithm is designed. For instance, a easy sentence will be separated into particular person phrases so that every phrase turns into a token.
Contemplate the sentence:
Synthetic intelligence is remodeling healthcare.
A fundamental phrase tokenization course of would possibly produce the next tokens:
- Synthetic
- intelligence
- is
- remodeling
- healthcare
Every token turns into a discrete unit that machine studying fashions can analyze and convert into numerical representations.
Tokenization subsequently acts as step one in most pure language processing pipelines.
Supply: YouTube | Tokenization.
Why Tokenization Is Essential in NLP
Human language incorporates ambiguity, punctuation, and sophisticated grammatical buildings that computer systems can not interpret straight. Tokenization helps simplify language by breaking sentences into manageable parts. Machine studying fashions depend on tokens as a result of algorithms course of numerical representations reasonably than uncooked textual content. After tokenization happens, every token is mapped to a numerical vector that represents its which means inside a dataset.
This conversion permits synthetic intelligence techniques to carry out duties reminiscent of:
- language translation
- sentiment evaluation
- speech recognition
- textual content classification
- query answering
Many of those applied sciences affect on a regular basis digital experiences described in Dwelling with AI
Tokenization subsequently performs a vital function in enabling computer systems to grasp and course of human language successfully.
How Tokenization Works
Tokenization usually happens early within the pure language processing pipeline. The method begins when uncooked textual content enters an NLP system. The algorithm analyzes the textual content and divides it into smaller segments in accordance with predefined guidelines.
Easy tokenization strategies cut up textual content based mostly on whitespace and punctuation. Extra superior tokenizers analyze linguistic patterns and statistical relationships inside giant datasets. As soon as tokens are created, the NLP system converts them into numerical representations referred to as embeddings. Machine studying fashions analyze these embeddings to determine patterns and relationships between phrases.
This course of permits algorithms to acknowledge which means, context, and relationships between language parts. Understanding how these patterns emerge additionally connects to strategies utilized in machine studying techniques mentioned in How Do You Educate Machines to Advocate. Though suggestion techniques analyze habits reasonably than language, each applied sciences depend on related sample recognition strategies.
How AI Breaks Textual content into Tokens
Tokenization is step one in NLP. AI splits a sentence into smaller items known as tokens.
Tokens will seem right here.
Kinds of Tokenization
Completely different tokenization methods exist relying on the necessities of the language mannequin.
Phrase Tokenization
Phrase tokenization is the only type of tokenization. The algorithm splits sentences into particular person phrases based mostly on areas and punctuation.
For instance, the sentence:
Machine studying improves healthcare diagnostics
would grow to be the next tokens:
- Machine
- studying
- improves
- healthcare
- diagnostics
Phrase tokenization works properly for a lot of languages however struggles when phrases include a number of meanings or grammatical variations.
Character Tokenization
Character tokenization breaks textual content into particular person characters as a substitute of phrases. Every letter turns into a token.
For instance:
AI improves medication
turns into:
Character tokenization permits fashions to deal with uncommon phrases and spelling variations. Nevertheless, it will increase the variety of tokens dramatically and should sluggish mannequin coaching.
Subword Tokenization
Subword tokenization splits phrases into smaller fragments referred to as subwords. This strategy balances the strengths of phrase and character tokenization.
For instance, the phrase:
unbelievable
could also be damaged into tokens reminiscent of:
Subword tokenization permits fashions to grasp unfamiliar phrases by combining recognized subword parts.
Many fashionable NLP techniques depend on subword tokenization strategies. Based on Hugging Face’s NLP course, subword tokenization is now the dominant strategy throughout just about all manufacturing transformer fashions because of its steadiness between vocabulary dimension and protection of uncommon phrases.
Tokenization in Transformer Fashions
Trendy language fashions reminiscent of GPT and BERT rely closely on superior tokenization strategies. These fashions use subword tokenization strategies reminiscent of Byte Pair Encoding and WordPiece tokenization. These algorithms determine often occurring character sequences inside giant textual content datasets. The tokenizer then builds a vocabulary of frequent subword items.
When the mannequin encounters a phrase exterior its vocabulary, the tokenizer breaks the phrase into smaller subword tokens that the mannequin can perceive. Transformer fashions analyze relationships between tokens reasonably than whole sentences. This strategy permits fashions to seize contextual which means and carry out complicated language duties reminiscent of summarization, translation, and conversational dialogue.
Lots of the broader developments shaping these applied sciences are mentioned in AI in Present Developments and Future Predictions.
Transformer based mostly fashions – the State of The Artwork (SOTA) Deep Studying architectures in NLP – course of the uncooked textual content on the token stage. Equally, the preferred deep studying architectures for NLP like RNN, GRU, and LSTM additionally course of the uncooked textual content on the token stage.
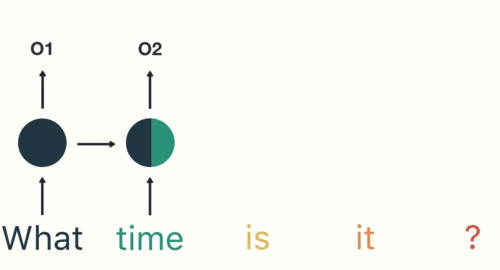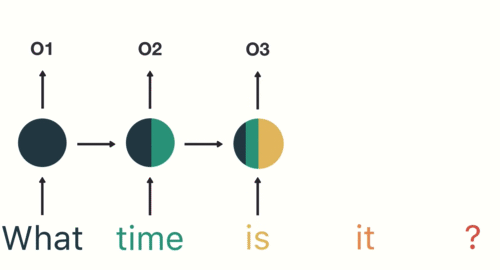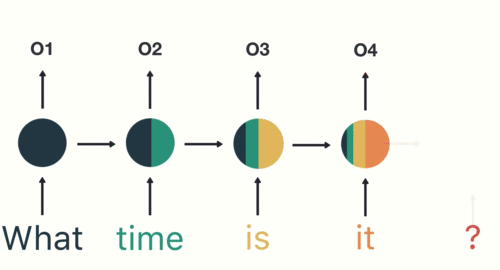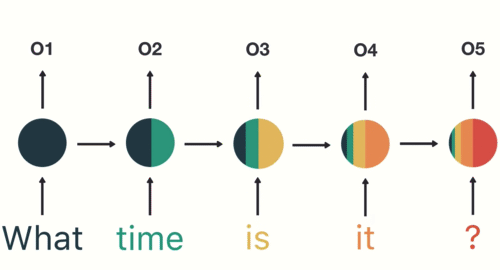
Therefore, Tokenization is the foremost step whereas modeling textual content information. Tokenization is carried out on the corpus to acquire tokens. The next tokens are then used to organize a vocabulary. Vocabulary refers back to the set of distinctive tokens within the corpus. Keep in mind that vocabulary will be constructed by contemplating every distinctive token within the corpus or by contemplating the highest Ok often occurring phrases.
Now, let’s perceive the utilization of the vocabulary in Conventional and Superior Deep Studying-based NLP strategies.
Conventional NLP approaches reminiscent of Depend Vectorizer and TF-IDF use vocabulary as options. Every phrase within the vocabulary is handled as a novel characteristic:
In Superior Deep Studying-based NLP architectures, vocabulary is used to create the tokenized enter sentences. Lastly, the tokens of those sentences are handed as inputs to the mannequin.
Tokenization Algorithms Utilized in NLP
Trendy pure language processing techniques depend on specialised tokenization algorithms. These algorithms assist fashions deal with complicated language patterns and enormous vocabularies.
Byte Pair Encoding BPE
Byte Pair Encoding is a extensively used tokenization methodology. It splits phrases into often occurring character sequences.
BPE begins with characters as tokens. The algorithm repeatedly merges frequent character pairs.
For instance, the phrase unbelievable could also be cut up into subword tokens reminiscent of:
BPE reduces vocabulary dimension whereas preserving which means. Many transformer based mostly language fashions depend on BPE tokenizers.
WordPiece Tokenization
WordPiece tokenization is utilized in fashions reminiscent of BERT. It builds a vocabulary of frequent phrase fragments.
The algorithm selects subwords that maximize likelihood throughout coaching. Uncommon phrases are decomposed into acquainted fragments.
For instance, the phrase tokenization could also be cut up into:
token
ization
This strategy improves mannequin accuracy when encountering unfamiliar phrases.
SentencePiece Tokenization
SentencePiece treats textual content as a steady sequence of characters. It doesn’t depend upon whitespace boundaries.
This strategy works properly for languages that don’t separate phrases with areas, reminiscent of Chinese language and Japanese.
SentencePiece helps algorithms reminiscent of:
- Byte Pair Encoding
- Unigram language mannequin tokenization
Many multilingual NLP techniques use SentencePiece tokenization.
How Tokenization Impacts Token Limits in Massive Language Fashions
Massive language fashions course of enter utilizing tokens as a substitute of phrases. Every phrase or subword fragment turns into a token.
Language fashions have limits on what number of tokens they’ll course of in a single request.
| Mannequin | Approximate Token Restrict |
|---|---|
| GPT 3 | 4096 tokens |
| GPT 4 | 8000 to 32000 tokens |
| GPT 4 Turbo | As much as 128000 tokens |
Lengthy paperwork require extra tokens. Tokenization subsequently determines how a lot textual content a mannequin can analyze. A sentence with complicated phrases might produce extra tokens. This will increase computational price and processing time. Understanding tokenization helps builders optimize prompts and coaching datasets.
OpenAI’s tokenizer documentation gives a reside software that demonstrates how textual content is cut up into tokens, making it potential to check any sentence or doc earlier than sending it to the API.
Tokenization in Trendy AI Programs: GPT, Claude, and Gemini
Tokenization methods have grow to be a essential engineering resolution within the improvement of contemporary giant language fashions. GPT-4 and subsequent OpenAI fashions use Byte Pair Encoding via the tiktoken library, which produces tokens averaging roughly 4 characters in English textual content. This implies a typical web page of textual content containing round 750 phrases generates roughly 1,000 tokens, a ratio builders should account for when designing prompts and managing context home windows.
Anthropic’s Claude fashions use the same subword tokenization strategy, calibrated for environment friendly context utilization throughout lengthy paperwork and multi-turn conversations. Google’s Gemini household depends on SentencePiece-based tokenization, which handles multilingual inputs significantly properly and permits a single tokenizer to work throughout dozens of languages with out requiring language detection preprocessing.
The growth of context home windows throughout current-generation fashions has made tokenization effectivity more and more essential. A mannequin processing 100,000 tokens in a single request should tokenize, embed, and attend over every of these items, which means that tokenization design decisions straight affect each inference price and response latency. Builders working with retrieval-augmented era pipelines, the place lengthy paperwork are chunked and retrieved for injection into prompts, should perceive how their tokenizer handles chunk boundaries to keep away from splitting significant semantic items throughout tokens.
One rising sample is tokenizer-aware chunking, wherein doc processing pipelines cut up textual content not at arbitrary character counts however at pure token boundaries. This ensures that language fashions obtain semantically coherent enter segments and produce extra correct retrievals and summaries. Instruments reminiscent of LangChain and LlamaIndex have constructed tokenizer-aware chunking straight into their doc processing pipelines, reflecting how central tokenization has grow to be to manufacturing AI engineering. Based on the Stanford HAI 2024 AI Index, the deployment of huge language fashions throughout enterprise functions grew considerably in 2024, with tokenization and context administration cited as core technical concerns by engineering groups.
Instance of Tokenization Utilizing Python
Builders usually implement tokenization utilizing Python libraries reminiscent of NLTK.
The next instance demonstrates fundamental phrase tokenization.
from nltk.tokenize import word_tokenizetext = "Synthetic intelligence is remodeling healthcare."tokens = word_tokenize(textual content)print(tokens)Output:
['Artificial', 'intelligence', 'is', 'transforming', 'healthcare']Every token turns into an enter ingredient for machine studying fashions.
Builders additionally use libraries reminiscent of:
- spaCy
- Hugging Face Tokenizers
- TensorFlow Textual content
These instruments help superior tokenization strategies for contemporary NLP techniques.
Tokenization Comparability
Completely different tokenization methods serve completely different pure language processing duties.
| Tokenization Kind | Instance | Use Case |
|---|---|---|
| Phrase Tokenization | AI is highly effective | Conventional NLP pipelines |
| Character Tokenization | A I i s | Spelling correction and noisy textual content |
| Subword Tokenization | un imagine ready | Massive language fashions |
| Byte Pair Encoding | token ization | Transformer based mostly fashions |
| WordPiece | play ing | BERT and related architectures |
Subword tokenization now dominates fashionable NLP techniques. It balances vocabulary dimension with contextual understanding.
Tokenization Challenges
Tokenization might seem easy, however actual language introduces a number of challenges. Languages differ extensively in construction and grammar. Some languages don’t use areas between phrases, making tokenization extra complicated. Chinese language and Japanese textual content, for instance, requires specialised segmentation algorithms.
One other problem entails punctuation and contractions. Phrases reminiscent of “don’t” could also be handled as one token or cut up into a number of tokens relying on the tokenizer. Named entities, abbreviations, and emojis additionally create difficulties for tokenization algorithms. Builders subsequently design tokenization techniques fastidiously to make sure that tokens protect which means whereas remaining computationally environment friendly.
Tokenization vs Stemming vs Lemmatization
Tokenization usually seems alongside different textual content preprocessing strategies reminiscent of stemming and lemmatization. Though these processes work collectively in lots of NLP pipelines, they carry out completely different duties. Tokenization splits textual content into tokens. Stemming reduces phrases to their root kind by eradicating suffixes. For instance, “working” might grow to be “run.”
Lemmatization performs the same operate however makes use of linguistic guidelines to find out the right base type of a phrase. Collectively these strategies assist put together textual content for machine studying evaluation.
Actual World Purposes of Tokenization
Tokenization allows a variety of pure language processing functions. Serps use tokenization to interpret consumer queries and match them with related paperwork. Chatbots depend on tokenization to interpret consumer enter and generate responses. Machine translation techniques analyze tokens when changing textual content from one language to a different. Sentiment evaluation techniques consider tokens to find out whether or not textual content expresses optimistic or damaging opinions. Advice platforms might also analyze textual content tokens when deciphering consumer critiques and suggestions. These applied sciences affect digital experiences throughout many industries together with healthcare, finance, training, and leisure.
Incessantly Requested Questions About Tokenization in NLP
Tokenization is the method of dividing textual content into smaller parts known as tokens for machine studying evaluation. For instance, the sentence ‘Synthetic intelligence improves healthcare’ turns into 4 tokens: synthetic, intelligence, improves, and healthcare. Trendy techniques use subword tokenization, which may cut up unfamiliar phrases like ‘tokenization’ into fragments reminiscent of ‘token’ and ‘ization’ that the mannequin already understands.
Tokenization is crucial as a result of machine studying algorithms can not course of uncooked textual content straight. Language should first be transformed into structured items that algorithms can analyze. Tokens enable fashions to map language into numerical vectors that signify semantic which means. This step allows NLP techniques to carry out duties reminiscent of translation, sentiment evaluation, and textual content classification.
The most typical forms of tokenization embrace phrase tokenization, character tokenization, and subword tokenization. Phrase tokenization divides sentences into phrases. Character tokenization splits textual content into particular person characters. Subword tokenization divides phrases into smaller fragments that assist fashions interpret unfamiliar vocabulary.
Subword tokenization breaks phrases into smaller items that seize significant fragments of language. As a substitute of treating each phrase as a novel token, the algorithm learns frequent subword patterns from giant datasets. This strategy permits fashions to interpret uncommon or unfamiliar phrases by combining recognized subword parts.
Massive language fashions reminiscent of GPT-4, Claude, and Gemini depend on tokenization to transform textual content into numerical inputs earlier than processing. Tokenizers remodel sentences into sequences of tokens utilizing algorithms reminiscent of Byte Pair Encoding or SentencePiece. Every token is mapped to a numerical embedding representing semantic which means. Most English textual content produces roughly one token per 4 characters, which means a 750-word doc generates roughly 1,000 tokens.
Tokenization splits textual content into tokens, whereas stemming reduces phrases to their root varieties. Tokenization prepares textual content for machine studying evaluation, whereas stemming simplifies vocabulary by eradicating suffixes. These processes usually work collectively throughout textual content preprocessing in NLP techniques.
Tokenization faces challenges when processing languages with out clear phrase boundaries reminiscent of Chinese language, Japanese, or Thai, which require specialised segmentation. Different challenges embrace dealing with contractions reminiscent of ‘don’t,’ named entities, emojis, code, and mathematical expressions. Tokenizers should additionally steadiness vocabulary dimension in opposition to protection — too small a vocabulary creates many unknown tokens, whereas too giant a vocabulary will increase reminiscence necessities and slows coaching.
Tokenization helps applied sciences throughout many industries together with serps, chatbots, healthcare analytics, finance, and social media evaluation. Any system that processes giant volumes of textual content information depends on tokenization as a part of the pure language processing pipeline.
In NLP, tokenization refers to splitting textual content into smaller items known as tokens that machine studying fashions can analyze. In cybersecurity and funds, tokenization refers to changing delicate information reminiscent of bank card numbers with randomly generated substitutes known as tokens that haven’t any exploitable worth. The 2 makes use of of the time period are solely unrelated and are available from completely different fields.
AI API suppliers reminiscent of OpenAI cost based mostly on the variety of tokens processed per request, masking each enter and output. An extended immediate with extra context produces extra tokens and prices extra. Builders optimize price by shortening prompts, summarizing context, and utilizing tokenizer instruments to estimate token counts earlier than sending requests. Understanding tokenization straight impacts AI software budgeting and structure.
Conclusion
Tokenization is a basic step in Pure Language Processing (NLP) that influences the efficiency of high-level duties reminiscent of sentiment evaluation, language translation, and subject extraction. It’s the technique of breaking down textual content into smaller items, or tokens, reminiscent of phrases or phrases. Tokenization not solely simplifies the following processes within the NLP pipeline but additionally allows the mannequin to grasp the context and semantic relationships between phrases.
Regardless of its obvious simplicity, tokenization can deal with complicated linguistic nuances and cater to completely different languages and textual content buildings. Its significance in NLP can’t be overstated as the standard of tokenization straight impacts the effectiveness of the general NLP system. As developments in AI and machine studying proceed, extra refined tokenization strategies are anticipated to emerge, enhancing the efficiency of NLP techniques additional.
References
Synthetic Intelligence Fundamentals: A Non-Technical Introduction
Synthetic Intelligence: A Information for Pondering People
Life 3.0: Being Human within the Age of Synthetic Intelligence
Synthetic Intelligence: Foundations of Computational Brokers






![How creators and entrepreneurs are utilizing AI to hurry up & succeed [data]](https://blog.aimactgrow.com/wp-content/uploads/2025/06/Untitled20design-Apr-07-2023-08-24-35-4586-PM-120x86.png)




{kind=link}