At present we’re rolling out an early model of Gemini 2.5 Flash in preview by means of the Gemini API through Google AI Studio and Vertex AI. Constructing upon the favored basis of two.0 Flash, this new model delivers a serious improve in reasoning capabilities, whereas nonetheless prioritizing pace and price. Gemini 2.5 Flash is our first totally hybrid reasoning mannequin, giving builders the power to show pondering on or off. The mannequin additionally permits builders to set pondering budgets to search out the appropriate tradeoff between high quality, value, and latency. Even with pondering off, builders can keep the quick speeds of two.0 Flash, and enhance efficiency.
Our Gemini 2.5 fashions are pondering fashions, able to reasoning by means of their ideas earlier than responding. As a substitute of instantly producing an output, the mannequin can carry out a “pondering” course of to raised perceive the immediate, break down complicated duties, and plan a response. On complicated duties that require a number of steps of reasoning (like fixing math issues or analyzing analysis questions), the pondering course of permits the mannequin to reach at extra correct and complete solutions. Actually, Gemini 2.5 Flash performs strongly on Exhausting Prompts in LMArena, second solely to 2.5 Professional.
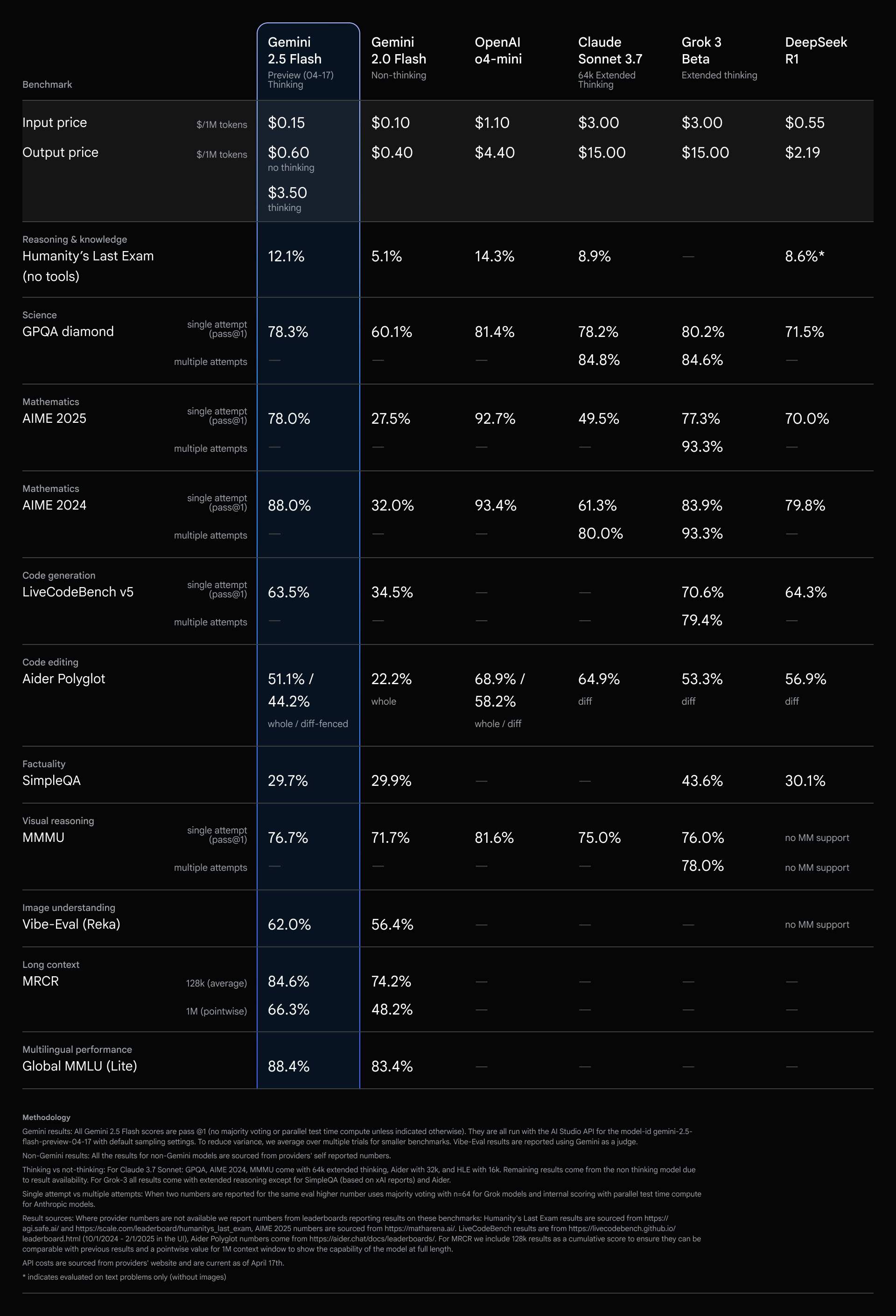
2.5 Flash has comparable metrics to different main fashions for a fraction of the associated fee and dimension.
Our most cost-efficient pondering mannequin
2.5 Flash continues to steer because the mannequin with the most effective price-to-performance ratio.
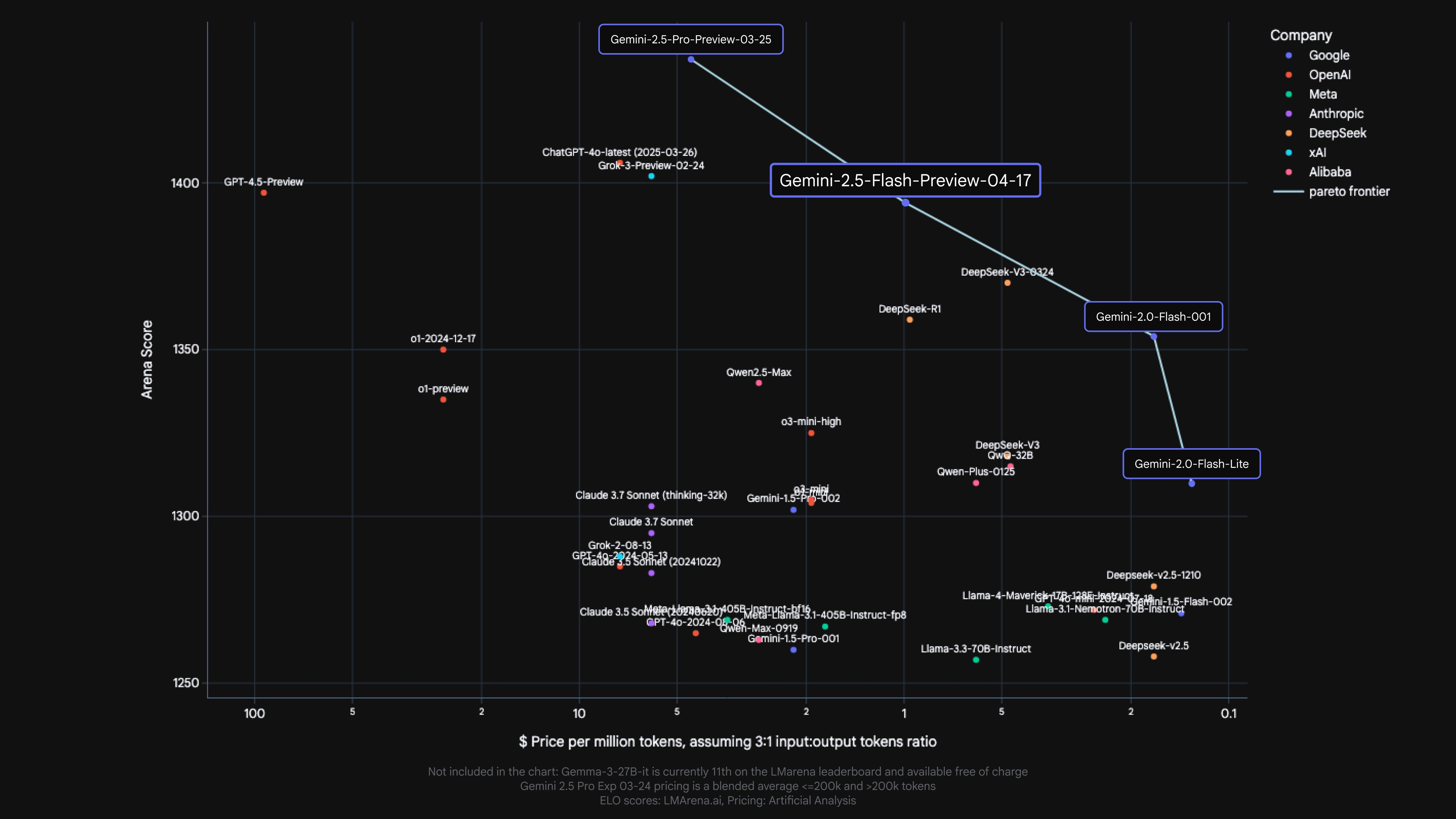
Gemini 2.5 Flash provides one other mannequin to Google’s pareto frontier of value to high quality.*
Advantageous-grained controls to handle pondering
We all know that totally different use circumstances have totally different tradeoffs in high quality, value, and latency. To offer builders flexibility, we’ve enabled setting a pondering price range that provides fine-grained management over the utmost variety of tokens a mannequin can generate whereas pondering. A better price range permits the mannequin to cause additional to enhance high quality. Importantly, although, the price range units a cap on how a lot 2.5 Flash can suppose, however the mannequin doesn’t use the total price range if the immediate doesn’t require it.
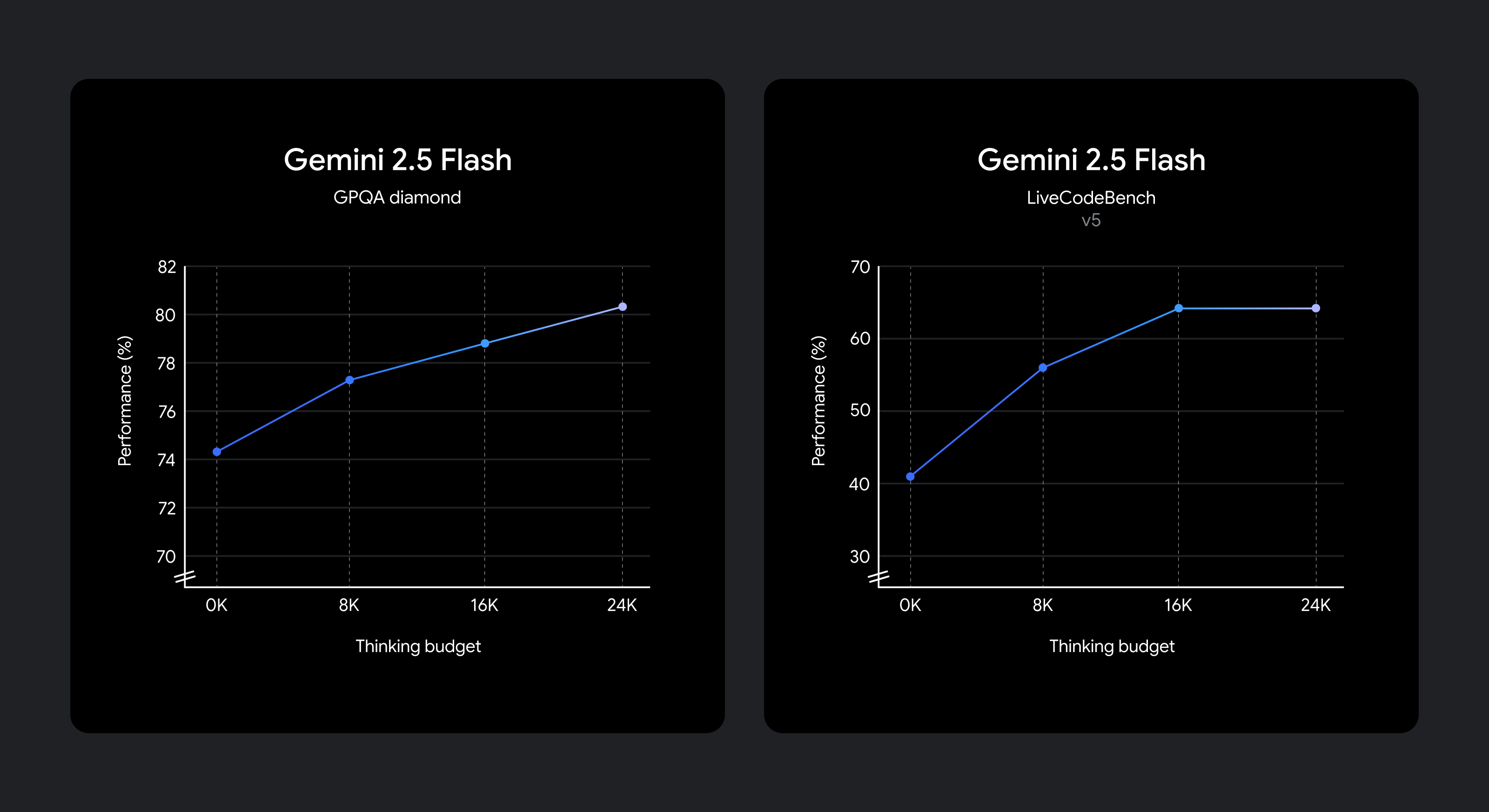
Enhancements in reasoning high quality as pondering price range will increase.
The mannequin is educated to understand how lengthy to suppose for a given immediate, and subsequently routinely decides how a lot to suppose based mostly on the perceived job complexity.
If you wish to maintain the bottom value and latency whereas nonetheless enhancing efficiency over 2.0 Flash, set the pondering price range to 0. You can even select to set a selected token price range for the pondering part utilizing a parameter within the API or the slider in Google AI Studio and in Vertex AI. The price range can vary from 0 to 24576 tokens for two.5 Flash.
The next prompts display how a lot reasoning could also be used within the 2.5 Flash’s default mode.
Prompts requiring low reasoning:
Instance 1: “Thanks” in Spanish
Instance 2: What number of provinces does Canada have?
Prompts requiring medium reasoning:
Instance 1: You roll two cube. What’s the likelihood they add as much as 7?
Instance 2: My health club has pickup hours for basketball between 9-3pm on MWF and between 2-8pm on Tuesday and Saturday. If I work 9-6pm 5 days every week and wish to play 5 hours of basketball on weekdays, create a schedule for me to make all of it work.
Prompts requiring excessive reasoning:
Instance 1: A cantilever beam of size L=3m has an oblong cross-section (width b=0.1m, top h=0.2m) and is fabricated from metal (E=200 GPa). It’s subjected to a uniformly distributed load w=5 kN/m alongside its whole size and some extent load P=10 kN at its free finish. Calculate the utmost bending stress (σ_max).
Instance 2: Write a operate evaluate_cells(cells: Dict[str, str]) -> Dict[str, float] that computes the values of spreadsheet cells.
Every cell incorporates:
- Or a components like
"=A1 + B1 * 2"utilizing+,-,*,/and different cells.
Necessities:
- Resolve dependencies between cells.
- Deal with operator priority (
*/earlier than+-).
- Detect cycles and lift
ValueError("Cycle detected at.") |
- No
eval(). Use solely built-in libraries.
Begin constructing with Gemini 2.5 Flash right this moment
Gemini 2.5 Flash with pondering capabilities is now accessible in preview through the Gemini API in Google AI Studio and in Vertex AI, and in a devoted dropdown within the Gemini app. We encourage you to experiment with the thinking_budget parameter and discover how controllable reasoning may help you clear up extra complicated issues.
from google import genai
shopper = genai.Shopper(api_key="GEMINI_API_KEY")
response = shopper.fashions.generate_content(
mannequin="gemini-2.5-flash-preview-04-17",
contents="You roll two cube. What’s the likelihood they add as much as 7?",
config=genai.varieties.GenerateContentConfig(
thinking_config=genai.varieties.ThinkingConfig(
thinking_budget=1024
)
)
)
print(response.textual content)Python
Discover detailed API references and pondering guides in our developer docs or get began with code examples from the Gemini Cookbook.
We’ll proceed to enhance Gemini 2.5 Flash, with extra coming quickly, earlier than we make it typically accessible for full manufacturing use.
*Mannequin pricing is sourced from Synthetic Evaluation & Firm Documentation



![A examine of fifty,000 manufacturers in ChatGPT [Study]](https://blog.aimactgrow.com/wp-content/uploads/2026/07/ai-visibility-is-a-topic-level-game-a-study-of-50000-brands-in-chatgpt-study-120x86.png)







{kind=link}