We all know that AI assistants like ChatGPT entry search indices, like Google and Bing, to retrieve URLs for his or her response. However how, precisely?
To search out out, we’ve run a collection of experiments trying on the relationship between the URLs cited by AI assistants, and the outcomes present in Google when looking for a similar matters.
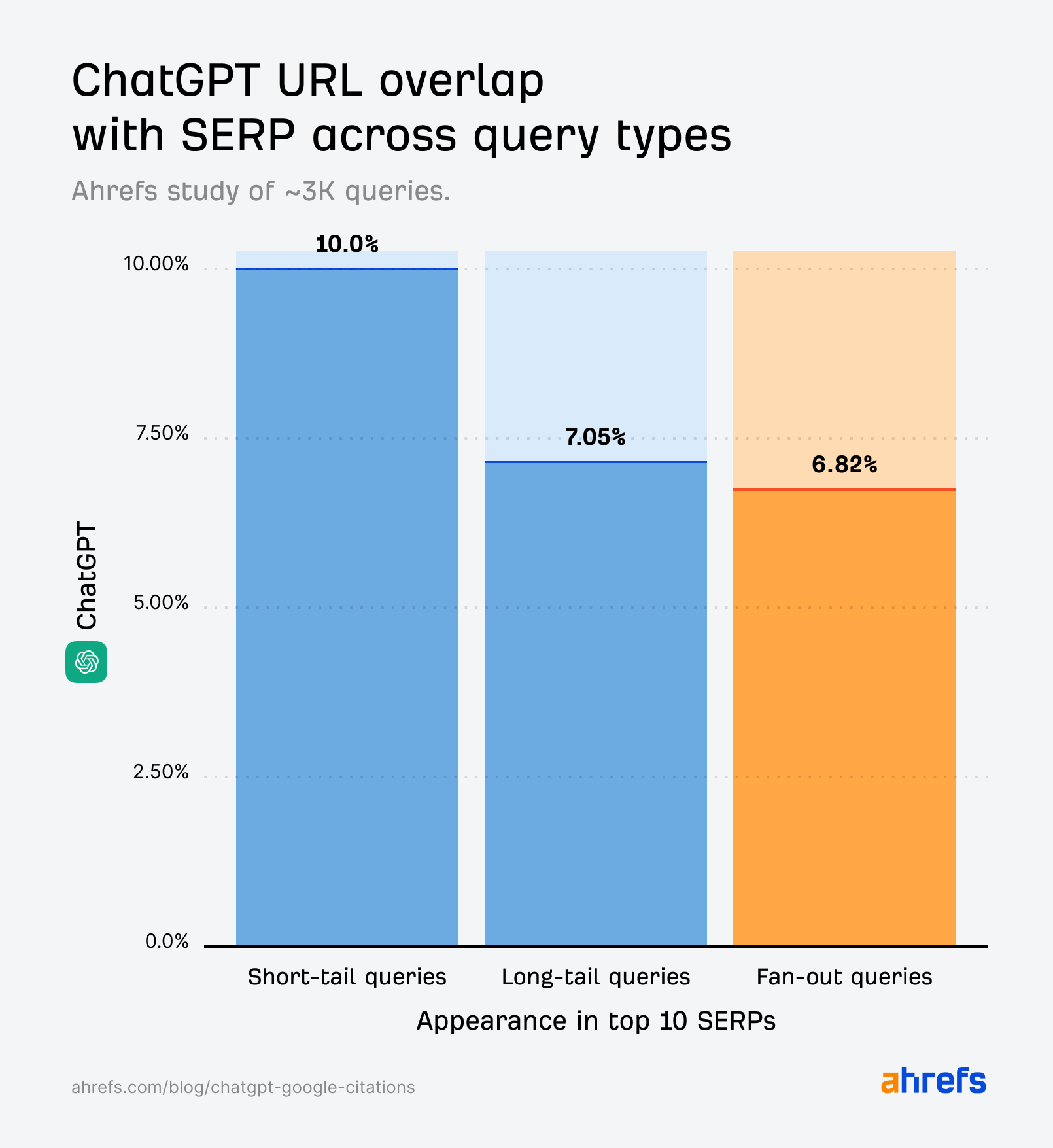
To date, we’ve examined long-tail prompts (very lengthy, very particular queries identical to these you’d enter into ChatGPT); fan-out queries (mid-length prompts that relate to the unique long-tail immediate); and right this moment we’re testing short-tail key phrases—ultra-short, ultra-specific “head” phrases.
Brief-tail key phrases provide the clearest illustration of how AI citations monitor with Google outcomes.
Primarily based on three separate research, our conclusion is that ChatGPT (and comparable programs) don’t simply raise URLs instantly from Google, Bing, or different indexes. As a substitute, they apply further processing steps earlier than citing sources.
Even after we examined fan-out queries—the precise search prompts these programs ship to serps—the overlap between AI and search engine citations was surprisingly low.
In different phrases, whereas ChatGPT could pull from Google’s search index, it nonetheless seems to use its personal choice layer that filters and reshuffles which hyperlinks seem.
It’s subsequently not sufficient to establish fan-out queries and rank nicely for them—there are further elements influencing which URLs get surfaced, which are outdoors of a writer’s management.
Completely different question sorts inform us various things about how AI assistants deal with info.
In our earlier analysis, Ahrefs’ information scientist Xibeijia Guan analyzed quotation overlap between AI and search outcomes for informational long-tail and fan-out prompts, utilizing Ahrefs Model Radar.
This time, she has taken a pattern of three,311 basic Search engine optimisation-style head phrases, protecting informational, industrial, transactional, and navigational intent.
| Instance question | Informational | Industrial | Transactional | Navigational |
|---|---|---|---|---|
| 1 | cincinnati bearcats basketball | finest bank card rewards | swimming pools for sale | onedrive signal in |
| 2 | protein in shrimp | soundbar for television | store women costume | verizon buyer help |
| 3 | what’s cybersecurity | at dwelling sauna | purchase a site | costco rest room paper |
Every key phrase has been run by way of ChatGPT, Perplexity, and Google’s prime 100 SERPs to research quotation overlap between AI and search.
If something had been to align intently with Google’s outcomes, you’d anticipate it to be short-tail queries—since that’s the basic approach we search.
However that’s not fairly the case.
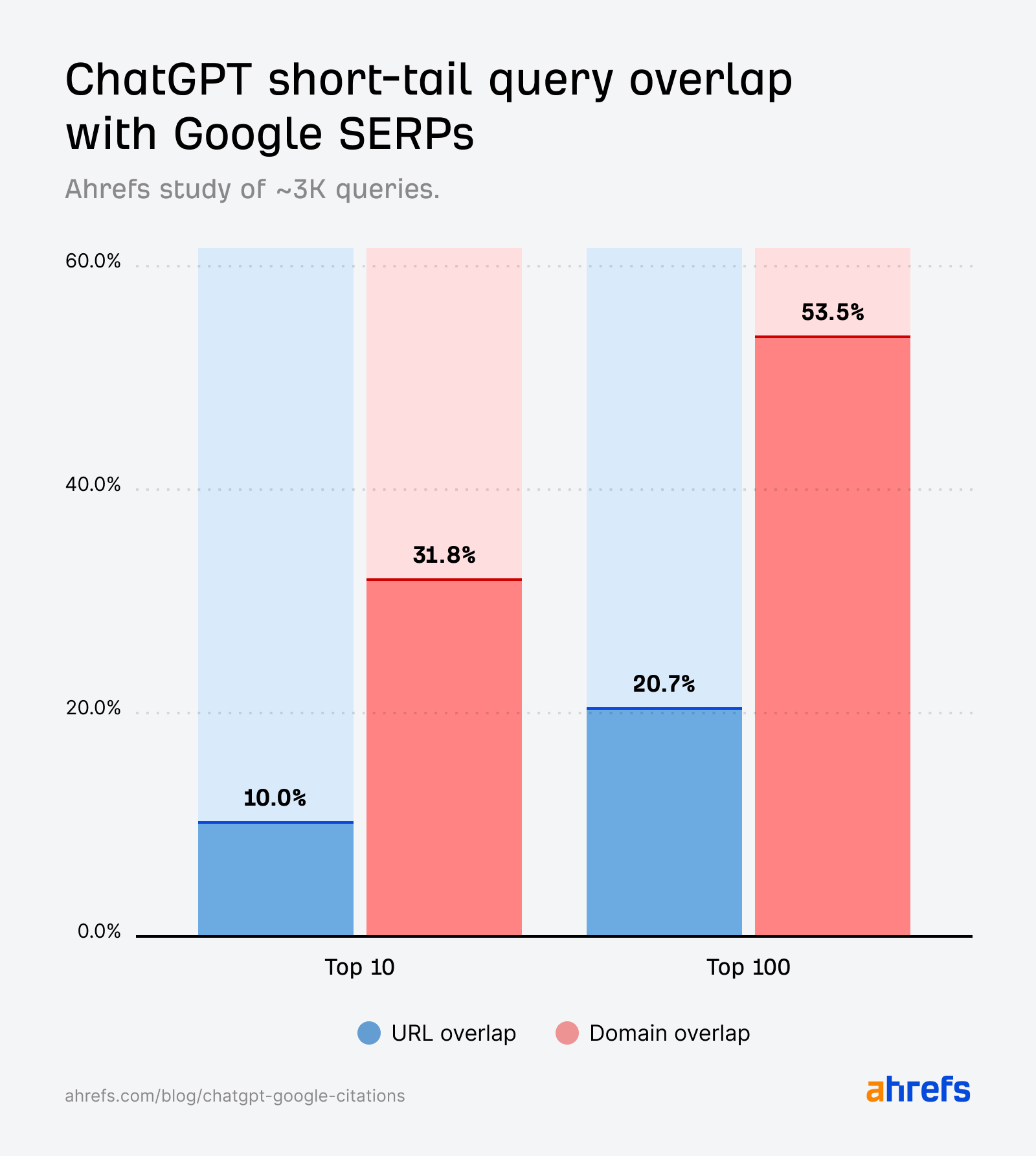
Whereas the quotation overlap for short-tail queries (10%) is barely stronger than for fan-out queries (6.82%), it’s nonetheless a lot weaker than we’d anticipate if it had been instantly echoing the SERPs.
That is much more stunning, now now we have affirmation that OpenAI and Perplexity have been scraping Google outcomes through a third-party supplier.
It’s doable we’d see extra overlap if our research targeted solely on ‘real-time’ queries (e.g., information, sports activities, finance), since these are reportedly the sorts ChatGPT scrapes Google for.
Perplexity citations align intently with Google’s search outcomes throughout short-tail queries.
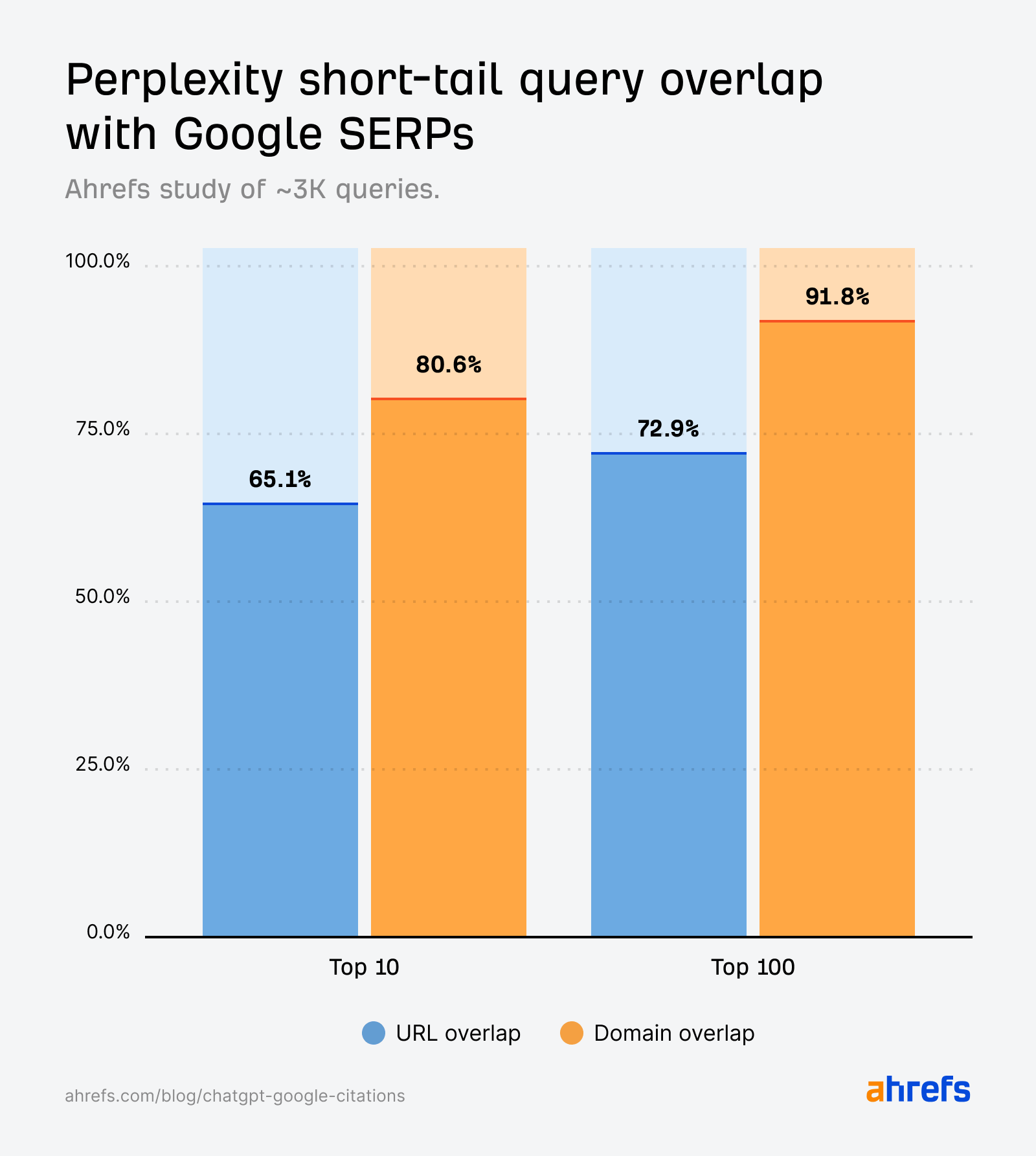
Not like ChatGPT, overlap isn’t simply seen on the area stage—most of Perplexity’s cited pages are additionally the precise URLs rating in Google’s prime 10.
This mirrors the findings in our long-tail question research, the place Perplexity responses most resembled Google’s outcomes, reinforcing its design as a “citation-first” engine.
Area overlap is persistently larger than URL overlap, suggesting that ChatGPT and Perplexity cite the identical web sites as Google—however not the very same pages.
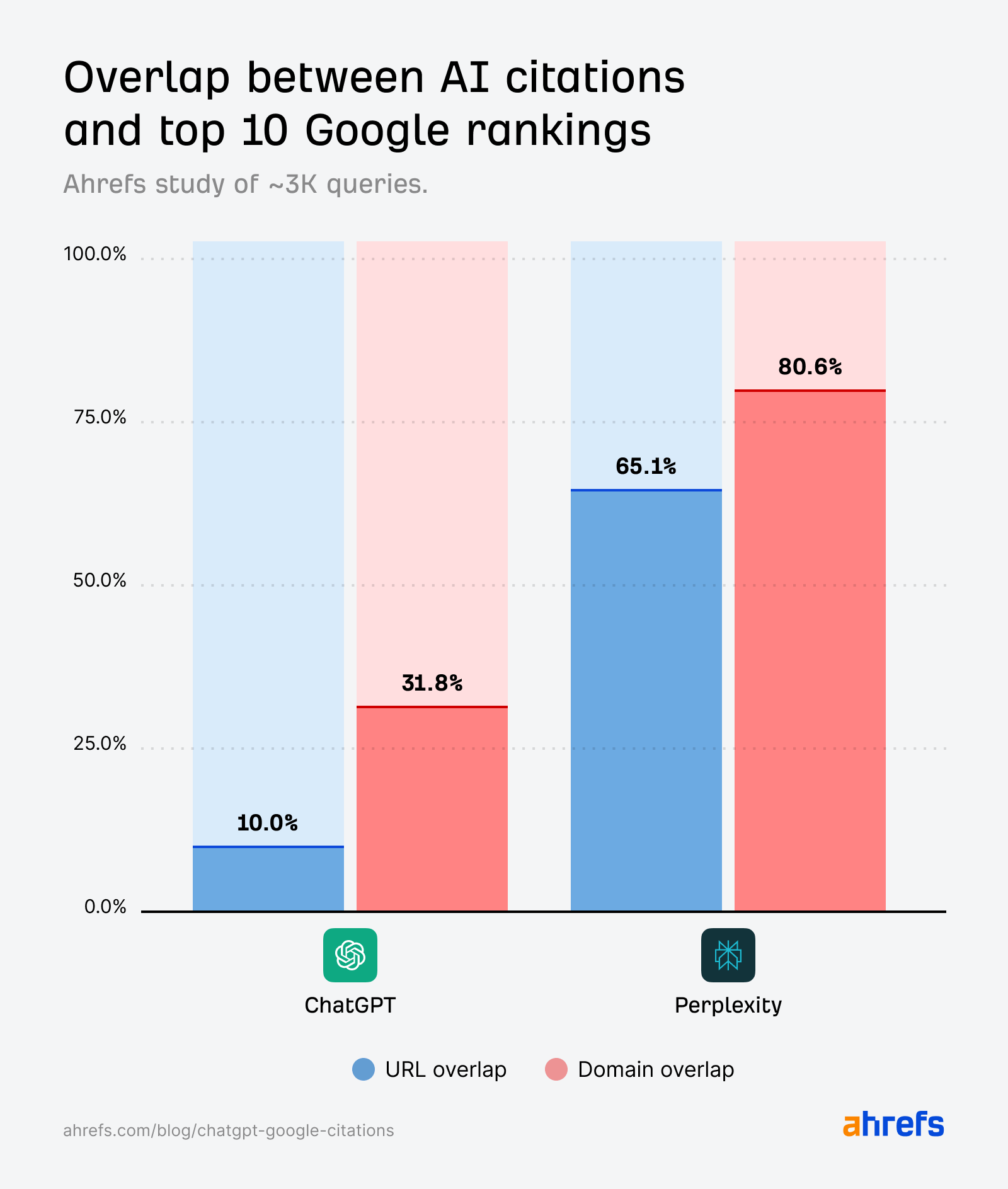
In ChatGPT, the domain-URL hole is very huge—31.8% vs. 10%.
In different phrases, ChatGPT cites rating domains ~3X greater than rating pages.
On the one hand, this might imply ChatGPT selects completely different pages from the similar domains as Google.
For instance, Google cites one web page from ahrefs.com/writing-tools/, whereas ChatGPT finds a greater “match” on ahrefs.com/weblog/ and cites one other.
If true, this reinforces the worth of making cluster content material—optimizing a number of pages for various matter intents, to have the most effective probability of being discovered.
One other chance is that each lean on the identical pool of authoritative domains, however disagree on arbitrary pages.
Assess your cluster content material in AI and search
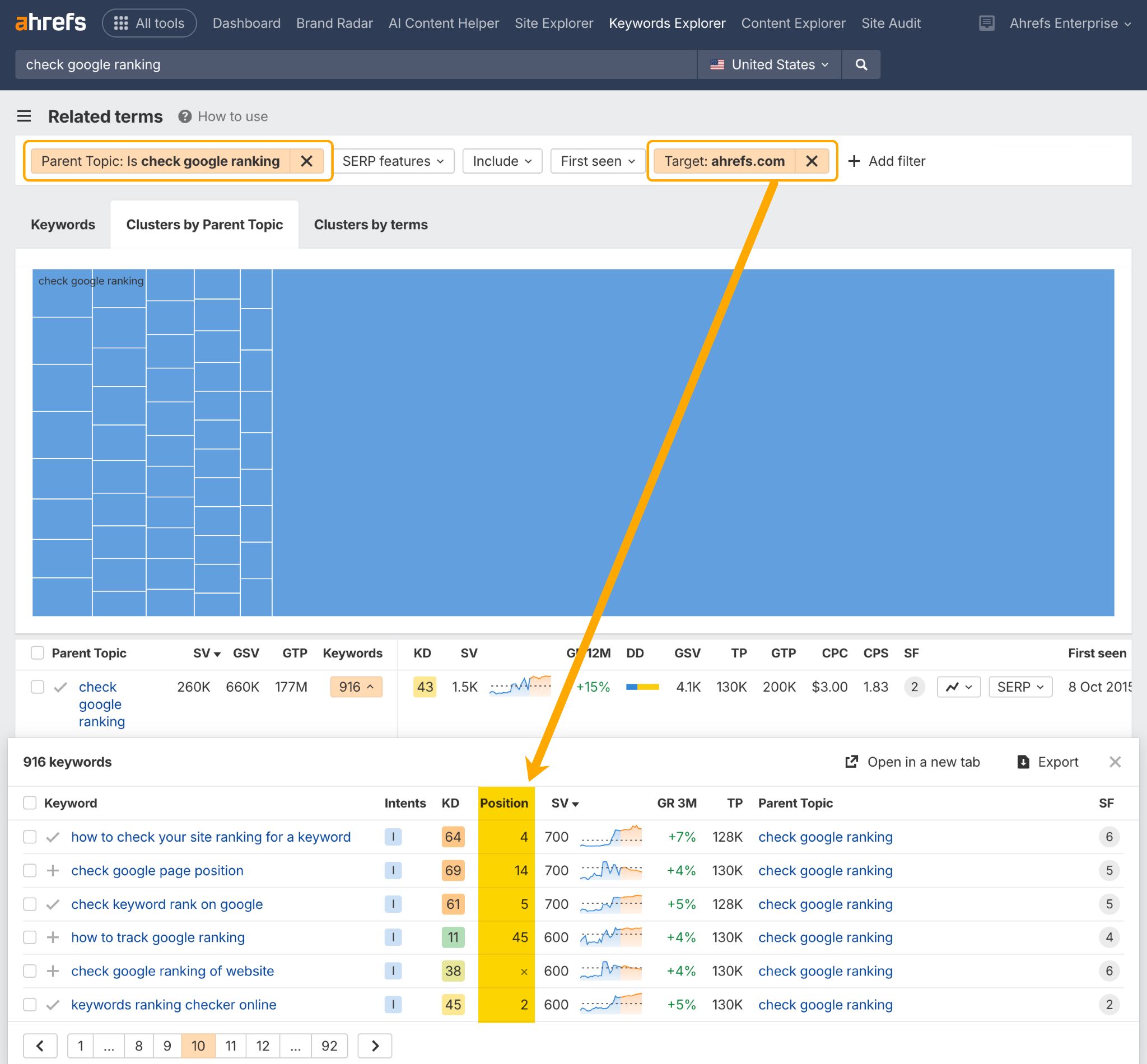
You may verify the Search engine optimisation efficiency of your cluster content material within the Associated Phrases report in Ahrefs Key phrases Explorer.
It will present you if and the place you rank throughout a whole cluster of associated key phrases.
Simply add a Mother or father Subject filter, and a Goal filter containing your area.
When you’ve carried out that, head to Ahrefs Model Radar to verify on the AI efficiency of your cluster content material.
Run particular person URLs by way of the Cited Pages report in Ahrefs Model Radar to see in case your cluster content material is being cited by AI assistants like ChatGPT, Perplexity, Gemini, and Copilot.
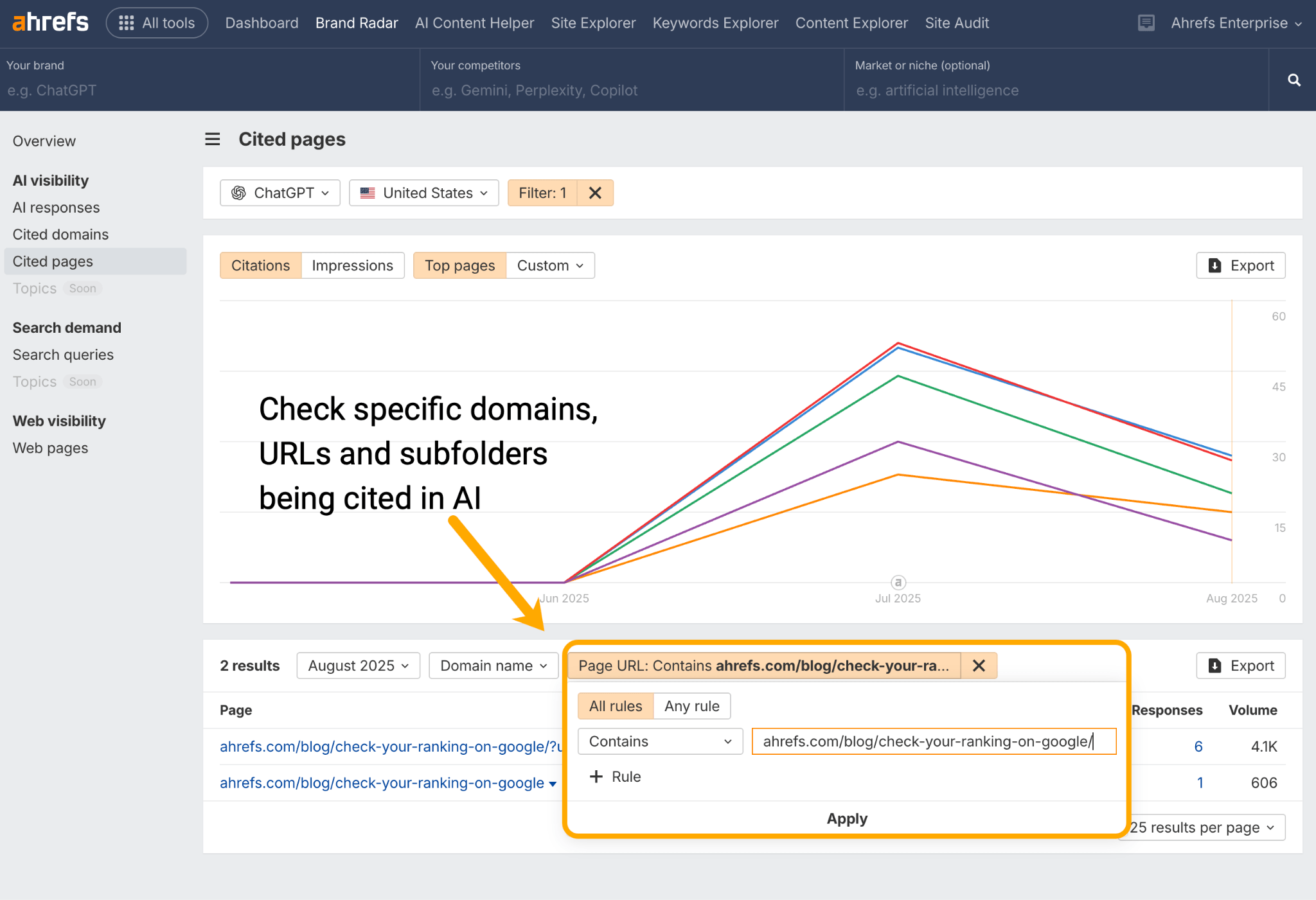
Work out if any content material is lacking from both floor, then optimize till you’ve stuffed these gaps and enriched the general cluster.
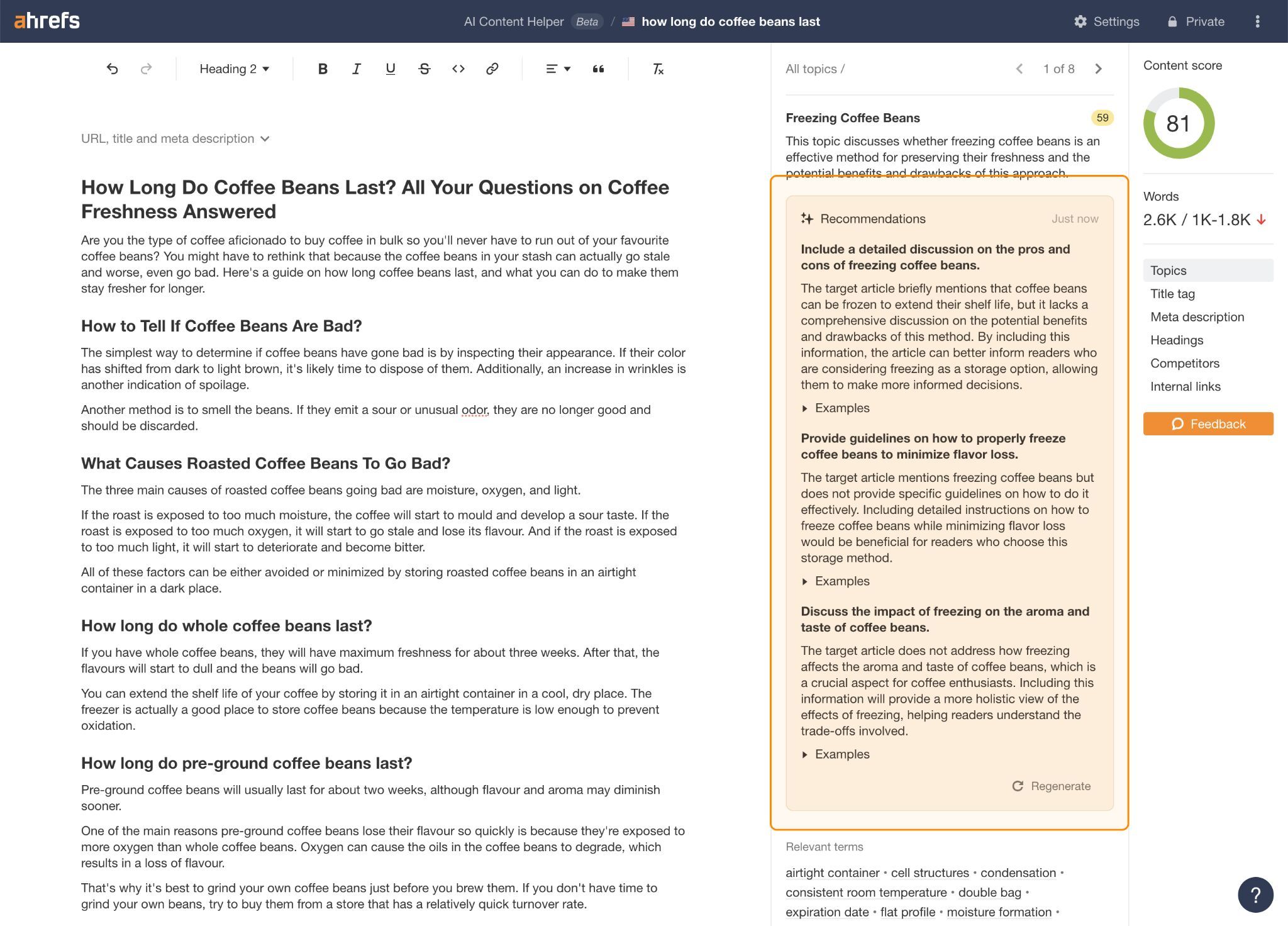
You should use matter hole suggestions in Ahrefs’ AI Content material Helper to assist with this.
Brief-tail queries present nearer SERP-AI alignment than pure language prompts—particularly in the case of Perplexity.
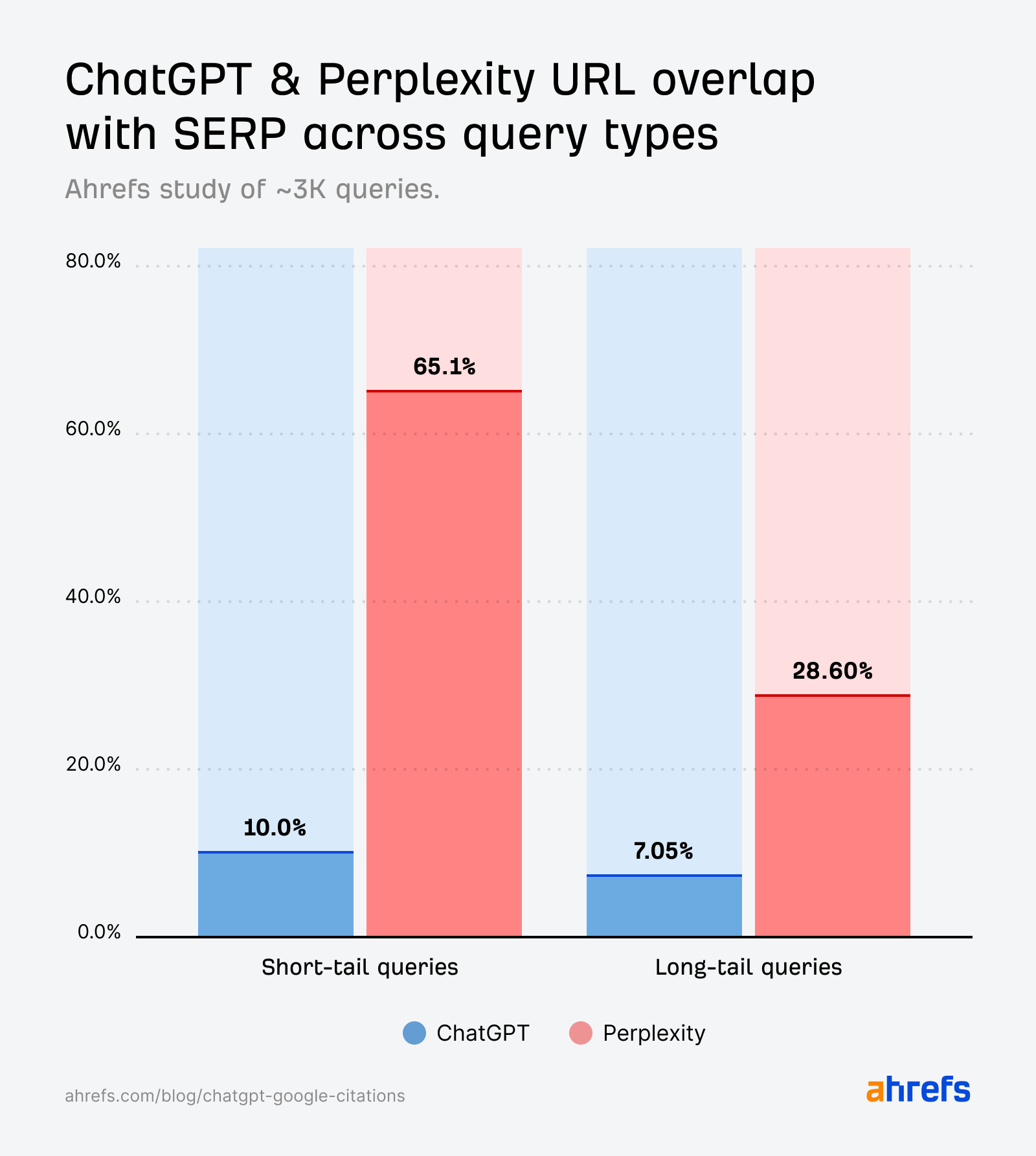
However the ChatGPT citations generated by fan-out queries (first studied by SQ and Xibeijia) present the least overlap. They match solely 6.82% of Google’s prime 10 outcomes.
We’re not evaluating apples-with-apples right here. These percentages signify completely different research, and completely different sized datasets.
However every research produces comparable findings: the pages that ChatGPT cites don’t overlap considerably with the pages that Google ranks. And it’s largely the alternative for Perplexity.
One different factor we haven’t talked about is intent. The larger quotation overlap we see throughout short-tail queries may partly be defined by the relative stability of navigational, industrial, and transactional queries—which we didn’t assess in our earlier research.
Navigational, industrial, and transactional head phrases have SERPs that don’t have a tendency to vary too typically, as a result of the set of related merchandise, manufacturers, or locations is finite.
This stability means AI assistants and Google usually tend to converge on the identical sources, which means overlap is larger than it’s for informational queries (the place the pool of doable pages is much bigger and extra risky).
Closing ideas
Throughout all three research, the story is constant: ChatGPT doesn’t observe Google’s sources, Perplexity does.
What’s stunning is that ChatGPT differs a lot from Google, after we now know that OpenAI does scrape Google’s outcomes.
My hunch is that ChatGPT does greater than Perplexity to distinguish its outcomes set from Google.
This concept from SQ appears probably the most possible one to me:
“ChatGPT seemingly makes use of a hybrid strategy the place they retrieve search outcomes from numerous sources, e.g. Google SERPs, Bing SERPs, their very own index, and third-party search APIs, after which mix all of the URLs and apply their very own re-ranking algorithm.”
Regardless of the case, search and AI are shaping discovery side-by-side, and the most effective technique is to construct content material that provides you an opportunity to look on each surfaces.











{kind=link}