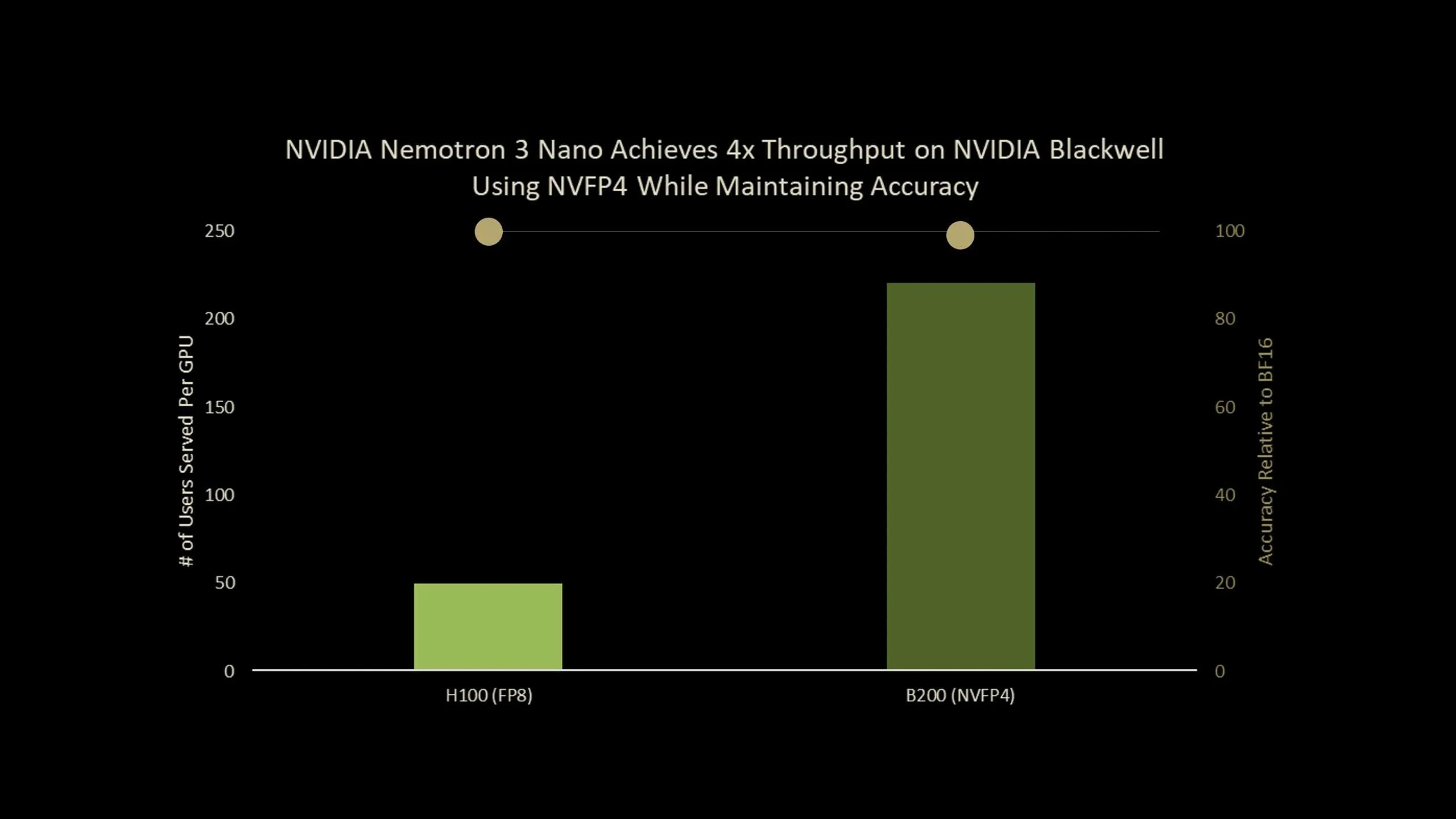
NVIDIA has launched Nemotron-Nano-3-30B-A3B-NVFP4, a manufacturing checkpoint that runs a 30B parameter reasoning mannequin in 4 bit NVFP4 format whereas preserving accuracy near its BF16 baseline. The mannequin combines a hybrid Mamba2 Transformer Combination of Specialists structure with a Quantization Conscious Distillation (QAD) recipe designed particularly for NVFP4 deployment. General, it’s an ultra-efficient NVFP4 precision model of Nemotron-3-Nano that delivers as much as 4x greater throughput on Blackwell B200.
What’s Nemotron-Nano-3-30B-A3B-NVFP4?
Nemotron-Nano-3-30B-A3B-NVFP4 is a quantized model of Nemotron-3-Nano-30B-A3B-BF16, skilled from scratch by NVIDIA staff as a unified reasoning and chat mannequin. It’s constructed as a hybrid Mamba2 Transformer MoE community:
- 30B parameters in complete
- 52 layers in depth
- 23 Mamba2 and MoE layers
- 6 grouped question consideration layers with 2 teams
- Every MoE layer has 128 routed consultants and 1 shared skilled
- 6 consultants are lively per token, which supplies about 3.5B lively parameters per token
The mannequin is pre-trained on 25T tokens utilizing a Warmup Steady Decay studying charge schedule with a batch dimension of 3072, a peak studying charge of 1e-3 and a minimal studying charge of 1e-5.
Put up coaching follows a 3 stage pipeline:
- Supervised positive tuning on artificial and curated information for code, math, science, device calling, instruction following and structured outputs.
- Reinforcement studying with synchronous GRPO throughout multi step device use, multi flip chat and structured environments, and RLHF with a generative reward mannequin.
- Put up coaching quantization to NVFP4 with FP8 KV cache and a selective excessive precision structure, adopted by QAD.
The NVFP4 checkpoint retains the eye layers and the Mamba layers that feed into them in BF16, quantizes remaining layers to NVFP4 and makes use of FP8 for the KV cache.
NVFP4 format and why it issues?
NVFP4 is a 4 bit floating level format designed for each coaching and inference on current NVIDIA GPUs. The primary properties of NVFP4:
- In contrast with FP8, NVFP4 delivers 2 to three occasions greater arithmetic throughput.
- It reduces reminiscence utilization by about 1.8 occasions for weights and activations.
- It extends MXFP4 by decreasing the block dimension from 32 to 16 and introduces two stage scaling.
The 2 stage scaling makes use of E4M3-FP8 scales per block and a FP32 scale per tensor. The smaller block dimension permits the quantizer to adapt to native statistics and the twin scaling will increase dynamic vary whereas preserving quantization error low.
For very giant LLMs, easy put up coaching quantization (PTQ) to NVFP4 already offers respectable accuracy throughout benchmarks. For smaller fashions, particularly these closely postage pipelines, the analysis staff notes that PTQ causes non negligible accuracy drops, which motivates a coaching based mostly restoration technique.
From QAT to QAD
Commonplace Quantization Conscious Coaching (QAT) inserts a pseudo quantization into the ahead move and reuses the authentic activity loss, reminiscent of subsequent token cross entropy. This works nicely for convolutional networks, however the analysis staff lists 2 important points for contemporary LLMs:
- Complicated multi stage put up coaching pipelines with SFT, RL and mannequin merging are arduous to breed.
- Unique coaching information for open fashions is usually unavailabublic kind.
Quantization Conscious Distillation (QAD) adjustments the target as a substitute of the total pipeline. A frozen BF16 mannequin acts as trainer and the NVFP4 mannequin is a pupil. Coaching minimizes KL divergence between their output token distributions, not the unique supervised or RL goal.
The analysis staff highlights 3 properties of QAD:
- It aligns the quantized mannequin with the excessive precision trainer extra precisely than QAT.
- It stays steady even when the trainer has already gone by a number of levels, reminiscent of supervised positive tuning, reinforcement studying and mannequin merging, as a result of QAD solely tries to match the ultimate trainer conduct.
- It really works with partial, artificial or filtered information, as a result of it solely wants enter textual content to question the trainer and pupil, not the unique labels or reward fashions.
Benchmarks on Nemotron-3-Nano-30B
Nemotron-3-Nano-30B-A3B is without doubt one of the RL heavy fashions within the QAD analysis. The beneath Desk reveals accuracy on AA-LCR, AIME25, GPQA-D, LiveCodeBench-v5 and SciCode-TQ, NVFP4-QAT and NVFP4-QAD.

Key Takeaways
- Nemotron-3-Nano-30B-A3B-NVFP4 is a 30B parameter hybrid Mamba2 Transformer MoE mannequin that runs in 4 bit NVFP4 with FP8 KV cache and a small set of BF16 layers preserved for stability, whereas preserving about 3.5B lively parameters per token and supporting context home windows as much as 1M tokens.
- NVFP4 is a 4 bit floating level format with block dimension 16 and two stage scaling, utilizing E4M3-FP8 per block scales and a FP32 per tensor scale, which supplies about 2 to three occasions greater arithmetic throughput and about 1.8 occasions decrease reminiscence value than FP8 for weights and activations.
- Quantization Conscious Distillation (QAD) replaces the unique activity loss with KL divergence to a frozen BF16 trainer, so the NVFP4 pupil instantly matches the trainer’s output distribution with out replaying the total SFT, RL and mannequin merge pipeline or needing the unique reward fashions.
- Utilizing the brand new Quantization Conscious Distillation technique, the NVFP4 model achieves as much as 99.4% accuracy of BF16
- On AA-LCR, AIME25, GPQA-D, LiveCodeBench and SciCode, NVFP4-PTQ reveals noticeable accuracy loss and NVFP4-QAT degrades additional, whereas NVFP4-QAD recovers efficiency to close BF16 ranges, decreasing the hole to just a few factors throughout these reasoning and coding benchmarks.
Try the Paper and Mannequin Weights. Additionally, be at liberty to observe us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be a part of us on telegram as nicely.











{kind=link}