NVIDIA has introduced the discharge of Nemotron-Cascade 2, an open-weight 30B Combination-of-Specialists (MoE) mannequin with 3B activated parameters. The mannequin focuses on maximizing ‘intelligence density,’ delivering superior reasoning capabilities at a fraction of the parameter scale utilized by frontier fashions. Nemotron-Cascade 2 is the second open-weight LLM to attain Gold Medal-level efficiency within the 2025 Worldwide Mathematical Olympiad (IMO), the Worldwide Olympiad in Informatics (IOI), and the ICPC World Finals.
Focused Efficiency and Strategic Commerce-offs
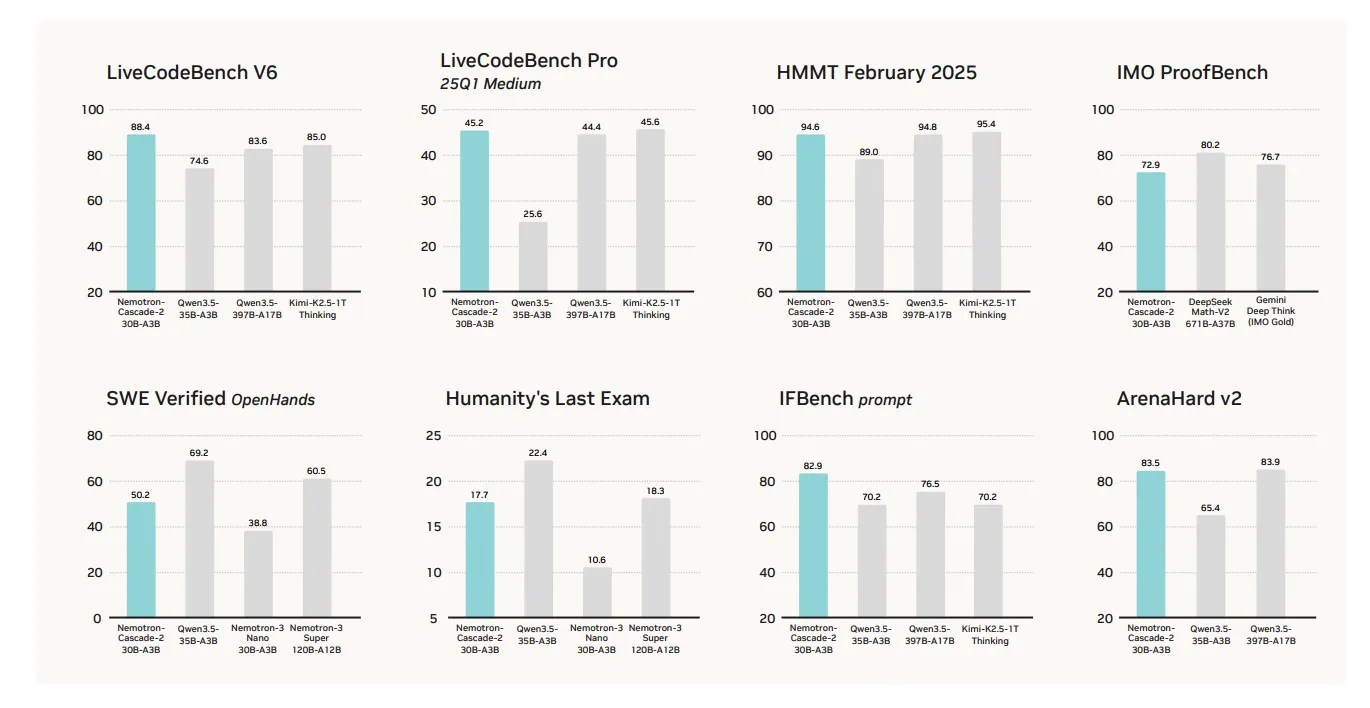
The first worth proposition of Nemotron-Cascade 2 is its specialised efficiency in mathematical reasoning, coding, alignment, and instruction following. Whereas it achieves state-of-the-art leads to these key reasoning-intensive domains, it’s absolutely not a ‘blanket win’ throughout all benchmarks.
The mannequin’s efficiency excels in a number of focused classes in comparison with the not too long ago launched Qwen3.5-35B-A3B (February 2026) and the bigger Nemotron-3-Tremendous-120B-A12B:
- Mathematical Reasoning: Outperforms Qwen3.5-35B-A3B on AIME 2025 (92.4 vs. 91.9) and HMMT Feb25 (94.6 vs. 89.0).
- Coding: Leads on LiveCodeBench v6 (87.2 vs. 74.6) and IOI 2025 (439.28 vs. 348.6+).
- Alignment and Instruction Following: Scores considerably greater on ArenaHard v2 (83.5 vs. 65.4+) and IFBench (82.9 vs. 70.2).
Technical Structure: Cascade RL and Multi-domain On-Coverage Distillation (MOPD)
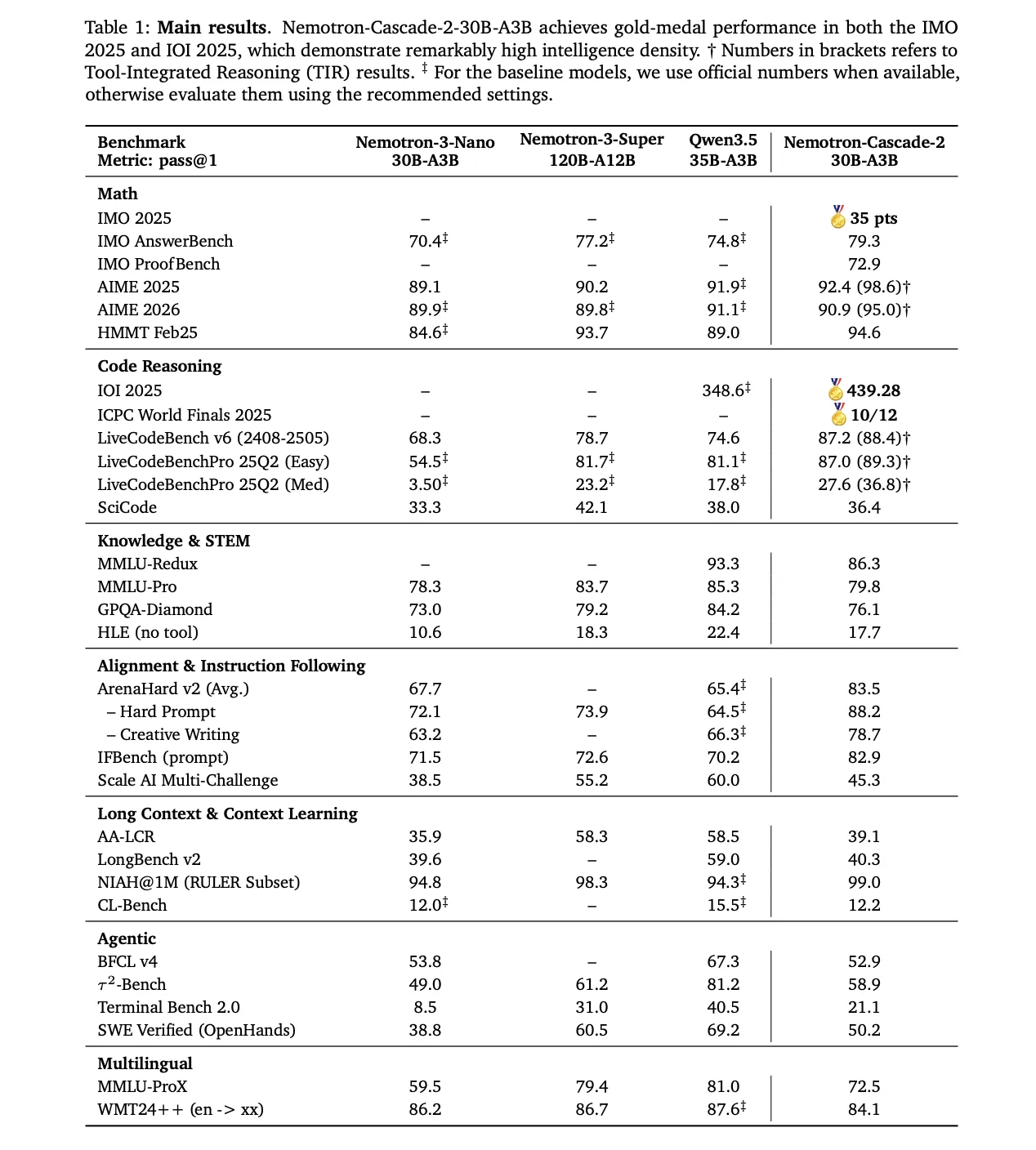
The mannequin’s reasoning capabilities stem from its post-training pipeline, ranging from the Nemotron-3-Nano-30B-A3B-Base mannequin.
1. Supervised Wonderful-Tuning (SFT)
Throughout SFT, NVIDIA analysis staff utilized a meticulously curated dataset the place samples had been packed into sequences of as much as 256K tokens. The dataset included:
- 1.9M Python reasoning traces and 1.3M Python tool-calling samples for aggressive coding.
- 816K samples for mathematical pure language proofs.
- A specialised Software program Engineering (SWE) mix consisting of 125K agentic and 389K agentless samples.
2. Cascade Reinforcement Studying
Following SFT, the mannequin underwent Cascade RL, which applies sequential, domain-wise coaching. This prevents catastrophic forgetting by permitting hyperparameters to be tailor-made to particular domains with out destabilizing others. The pipeline contains levels for instruction-following (IF-RL), multi-domain RL, RLHF, long-context RL, and specialised Code and SWE RL.
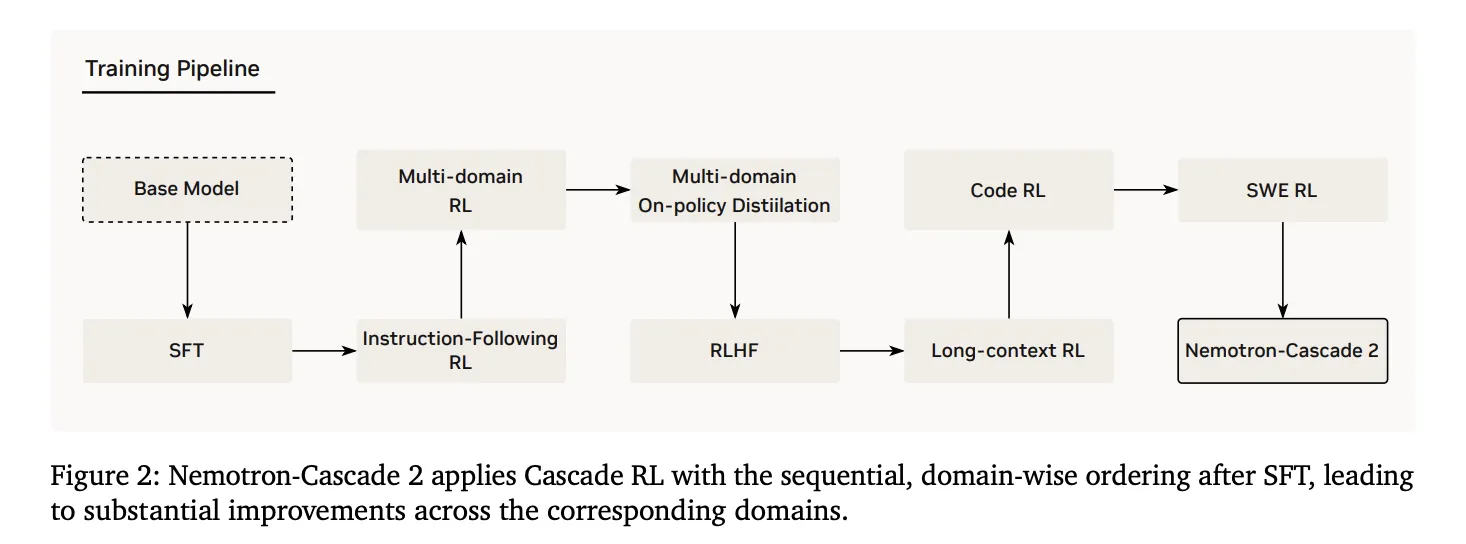
3. Multi-Area On-Coverage Distillation (MOPD)
A crucial innovation in Nemotron-Cascade 2 is the mixing of MOPD through the Cascade RL course of. MOPD meeting makes use of the best-performing intermediate ‘trainer’ fashions—already derived from the identical SFT initialization—to supply a dense token-level distillation benefit. This benefit is outlined mathematically as:
$$a_{t}^{MOPD}=log~pi^{domain_{t}}(y_{t}|s_{t})-log~pi^{practice}(y_{t}|s_{t})$$
The analysis staff discovered that MOPD is considerably extra sample-efficient than sequence-level reward algorithms like Group Relative Coverage Optimization (GRPO). As an example, on AIME25, MOPD reached teacher-level efficiency (92.0) inside 30 steps, whereas GRPO achieved solely 91.0 after matching these steps.
Inference Options and Agentic Interplay
Nemotron-Cascade 2 helps two major working modes by its chat template:
- Pondering Mode: Initiated by a single
- Non-Pondering Mode: Activated by prepending an empty
For agentic duties, the mannequin makes use of a structured tool-calling protocol throughout the system immediate. Out there instruments are listed inside
By specializing in ‘intelligence density,’ Nemotron-Cascade 2 demonstrates that specialised reasoning capabilities as soon as regarded as the unique area of frontier-scale fashions are achievable at a 30B scale by domain-specific reinforcement studying.
Try Paper and Mannequin on HF. Additionally, be happy to comply with us on Twitter and don’t neglect to affix our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be part of us on telegram as effectively.











{kind=link}