Pondering Machines Lab has moved its Tinker coaching API into common availability and added 3 main capabilities, help for the Kimi K2 Pondering reasoning mannequin, OpenAI appropriate sampling, and picture enter by way of Qwen3-VL imaginative and prescient language fashions. For AI engineers, this turns Tinker right into a sensible technique to high quality tune frontier fashions with out constructing distributed coaching infrastructure.
What Tinker Really Does?
Tinker is a coaching API that focuses on giant language mannequin high quality tuning and hides the heavy lifting of distributed coaching. You write a easy Python loop that runs on a CPU solely machine. You outline the info or RL surroundings, the loss, and the coaching logic. The Tinker service maps that loop onto a cluster of GPUs and executes the precise computation you specify.
The API exposes a small set of primitives, equivalent to forward_backward to compute gradients, optim_step to replace weights, pattern to generate outputs, and capabilities for saving and loading state. This retains the coaching logic express for individuals who need to implement supervised studying, reinforcement studying, or choice optimization, however don’t need to handle GPU failures and scheduling.
Tinker makes use of low rank adaptation, LoRA, relatively than full high quality tuning for all supported fashions. LoRA trains small adapter matrices on prime of frozen base weights, which reduces reminiscence and makes it sensible to run repeated experiments on giant combination of specialists fashions in the identical cluster.
Common Availability and Kimi K2 Pondering
The flagship change within the December 2025 replace is that Tinker not has a waitlist. Anybody can join, see the present mannequin lineup and pricing, and run cookbook examples instantly.
On the mannequin aspect, customers can now high quality tune moonshotai/Kimi-K2-Pondering on Tinker. Kimi K2 Pondering is a reasoning mannequin with about 1 trillion whole parameters in a combination of specialists structure. It’s designed for lengthy chains of thought and heavy device use, and it’s presently the biggest mannequin within the Tinker catalog.
Within the Tinker mannequin lineup, Kimi K2 Pondering seems as a Reasoning MoE mannequin, alongside Qwen3 dense and combination of specialists variants, Llama-3 era fashions, and DeepSeek-V3.1. Reasoning fashions at all times produce inner chains of thought earlier than the seen reply, whereas instruction fashions deal with latency and direct responses.
OpenAI Appropriate Sampling Whereas Coaching
Tinker already had a local sampling interface by way of its SamplingClient. The everyday inference sample builds a ModelInput from token ids, passes SamplingParams, and calls pattern to get a future that resolves to outputs
The brand new launch provides a second path that mirrors the OpenAI completions interface. A mannequin checkpoint on Tinker might be referenced by way of a URI like:
response = openai_client.completions.create(
mannequin="tinker://0034d8c9-0a88-52a9-b2b7-bce7cb1e6fef:practice:0/sampler_weights/000080",
immediate="The capital of France is",
max_tokens=20,
temperature=0.0,
cease=["n"],
)Imaginative and prescient Enter With Qwen3-VL On Tinker
The second main functionality is picture enter. Tinker now exposes 2 Qwen3-VL imaginative and prescient language fashions, Qwen/Qwen3-VL-30B-A3B-Instruct and Qwen/Qwen3-VL-235B-A22B-Instruct. They’re listed within the Tinker mannequin lineup as Imaginative and prescient MoE fashions and can be found for coaching and sampling by way of the identical API floor.
To ship a picture right into a mannequin, you assemble a ModelInput that interleaves an ImageChunk with textual content chunks. The analysis weblog makes use of the next minimal instance:
model_input = tinker.ModelInput(chunks=[
tinker.types.ImageChunk(data=image_data, format="png"),
tinker.types.EncodedTextChunk(tokens=tokenizer.encode("What is this?")),
])Right here image_data is uncooked bytes and format identifies the encoding, for instance png or jpeg. You should utilize the identical illustration for supervised studying and for RL high quality tuning, which retains multimodal pipelines constant on the API degree. Imaginative and prescient inputs are totally supported in Tinker’s LoRA coaching setup.
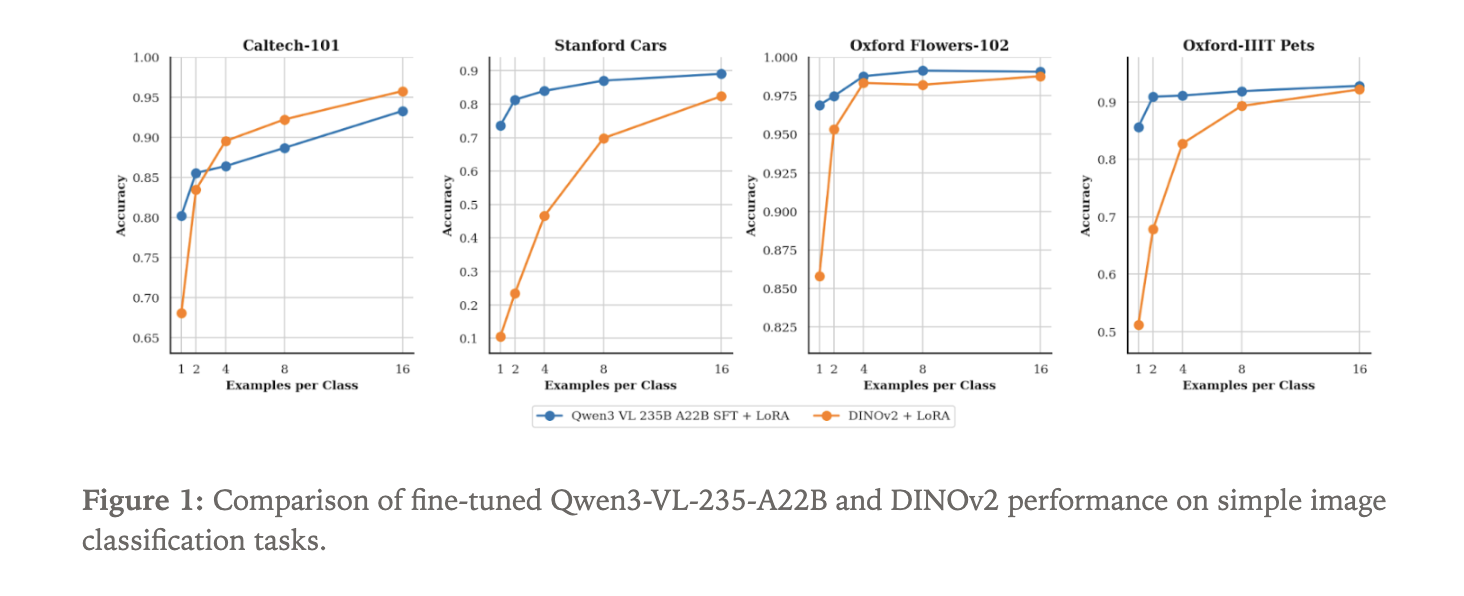
Qwen3-VL Versus DINOv2 On Picture Classification
To indicate what the brand new imaginative and prescient path can do, the Tinker staff high quality tuned Qwen3-VL-235B-A22B-Instruct as a picture classifier. They used 4 commonplace datasets:
- Caltech 101
- Stanford Vehicles
- Oxford Flowers
- Oxford Pets
As a result of Qwen3-VL is a language mannequin with visible enter, classification is framed as textual content era. The mannequin receives a picture and generates the category title as a textual content sequence.
As a baseline, they high quality tuned a DINOv2 base mannequin. DINOv2 is a self supervised imaginative and prescient transformer that encodes pictures into embeddings and is commonly used as a spine for imaginative and prescient duties. For this experiment, a classification head is connected on prime of DINOv2 to foretell a distribution over the N labels in every dataset.
Each Qwen3-VL-235B-A22B-Instruct and DINOv2 base are educated utilizing LoRA adapters inside Tinker. The main target is information effectivity. The experiment sweeps the variety of labeled examples per class, ranging from just one pattern per class and rising. For every setting, the staff measures classification accuracy.
Key Takeaways
- Tinker is now usually accessible, so anybody can join and high quality tune open weight LLMs by way of a Python coaching loop whereas Tinker handles the distributed coaching backend.
- The platform helps Kimi K2 Pondering, a 1 trillion parameter combination of specialists reasoning mannequin from Moonshot AI, and exposes it as a high quality tunable reasoning mannequin within the Tinker lineup.
- Tinker provides an OpenAI appropriate inference interface, which helps you to pattern from in coaching checkpoints utilizing a
tinker://…mannequin URI by way of commonplace OpenAI type shoppers and tooling. - Imaginative and prescient enter is enabled by way of Qwen3-VL fashions, Qwen3-VL 30B and Qwen3-VL 235B, so builders can construct multimodal coaching pipelines that mix
ImageChunkinputs with textual content utilizing the identical LoRA primarily based API. - Pondering Machines demonstrates that Qwen3-VL 235B, high quality tuned on Tinker, achieves stronger few shot picture classification efficiency than a DINOv2 base baseline on datasets equivalent to Caltech 101, Stanford Vehicles, Oxford Flowers, and Oxford Pets, highlighting the info effectivity of huge imaginative and prescient language fashions.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.











{kind=link}