On this article, you’ll learn to establish, perceive, and mitigate race circumstances in multi-agent orchestration methods.
Subjects we’ll cowl embody:
- What race circumstances seem like in multi-agent environments
- Architectural patterns for stopping shared-state conflicts
- Sensible methods like idempotency, locking, and concurrency testing
Let’s get straight to it.
Dealing with Race Circumstances in Multi-Agent Orchestration
Picture by Editor
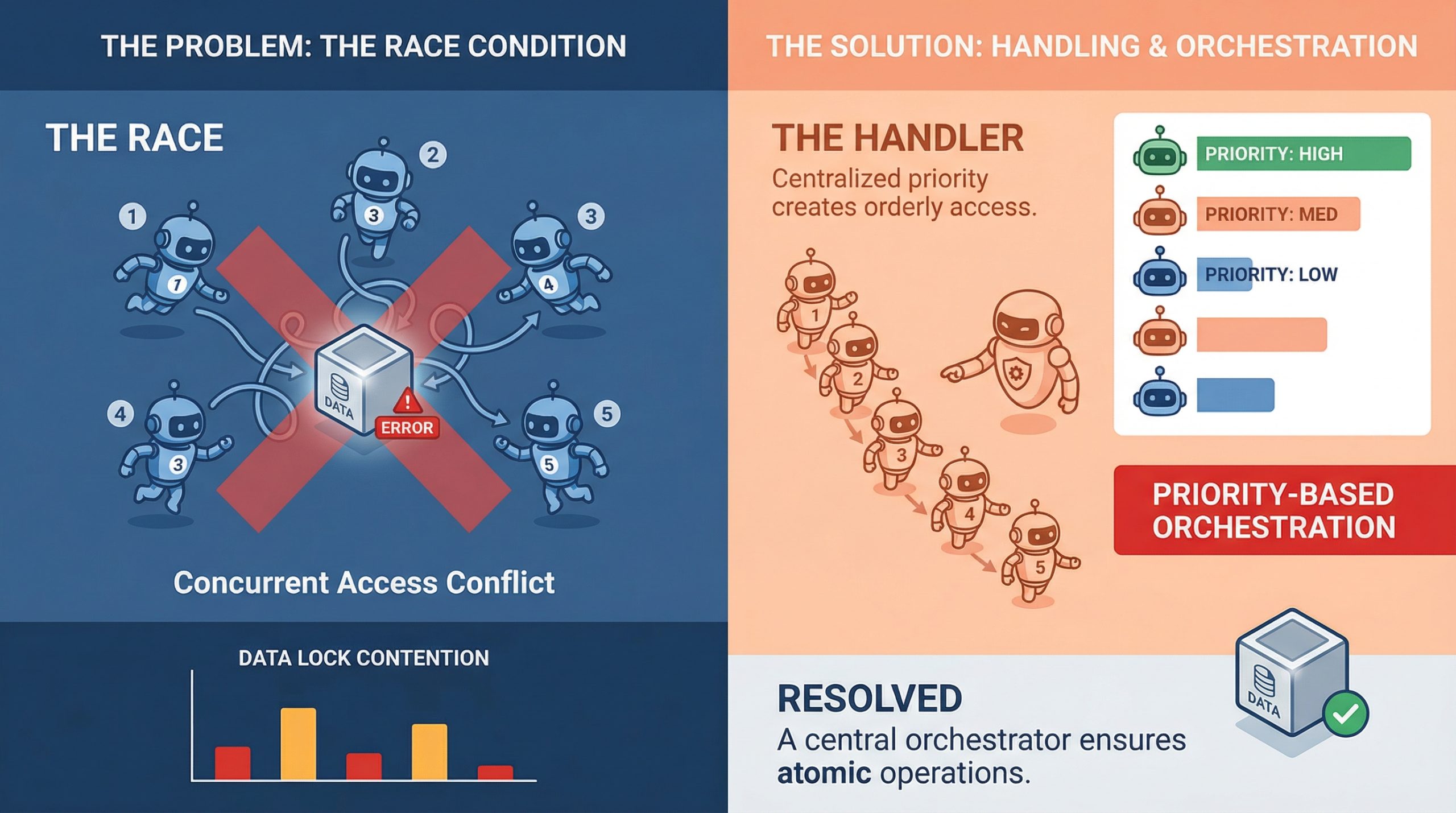
If you happen to’ve ever watched two brokers confidently write to the identical useful resource on the identical time and produce one thing that makes zero sense, you already know what a race situation seems like in follow. It’s a kind of bugs that doesn’t present up in unit exams, behaves completely in staging, after which detonates in manufacturing throughout your highest-traffic window.
In multi-agent methods, the place parallel execution is the entire level, race circumstances aren’t edge instances. They’re anticipated friends. Understanding learn how to deal with them is much less about being defensive and extra about constructing methods that assume chaos by default.
What Race Circumstances Truly Look Like in Multi-Agent Techniques
A race situation occurs when two or extra brokers attempt to learn, modify, or write shared state on the identical time, and the ultimate consequence is determined by which one will get there first. In a single-agent pipeline, that’s manageable. In a system with 5 brokers operating concurrently, it’s a genuinely totally different drawback.
The tough half is that race circumstances aren’t at all times apparent crashes. Typically they’re silent. Agent A reads a doc, Agent B updates it half a second later, and Agent A writes again a stale model with no error thrown anyplace. The system appears to be like high quality. The information is compromised.
What makes this worse in machine studying pipelines particularly is that brokers typically work on mutable shared objects, whether or not that’s a shared reminiscence retailer, a vector database, a device output cache, or a easy process queue. Any of those can turn into a competition level when a number of brokers begin pulling from them concurrently.
Why Multi-Agent Pipelines Are Particularly Weak
Conventional concurrent programming has many years of tooling round race circumstances: threads, mutexes, semaphores, and atomic operations. Multi-agent massive language mannequin (LLM) methods are newer, and they’re typically constructed on high of async frameworks, message brokers, and orchestration layers that don’t at all times provide you with fine-grained management over execution order.
There’s additionally the issue of non-determinism. LLM brokers don’t at all times take the identical period of time to finish a process. One agent may end in 200ms, whereas one other takes 2 seconds, and the orchestrator has to deal with that gracefully. When it doesn’t, brokers begin stepping on one another, and you find yourself with a corrupted state or conflicting writes that the system silently accepts.
Agent communication patterns matter quite a bit right here, too. If brokers are sharing state by a central object or a shared database row moderately than passing messages, they’re virtually assured to run into write conflicts at scale. That is as a lot a design sample concern as it’s a concurrency concern, and fixing it often begins on the structure degree earlier than you even contact the code.
Locking, Queuing, and Occasion-Pushed Design
Essentially the most direct method to deal with shared useful resource competition is thru locking. Optimistic locking works properly when conflicts are uncommon: every agent reads a model tag alongside the info, and if the model has modified by the point it tries to write down, the write fails and retries. Pessimistic locking is extra aggressive and reserves the useful resource earlier than studying. Each approaches have trade-offs, and which one matches is determined by how typically your brokers are literally colliding.
Queuing is one other strong method, particularly for process task. As an alternative of a number of brokers polling a shared process record straight, you push duties right into a queue and let brokers devour them separately. Techniques like Redis Streams, RabbitMQ, or perhaps a primary Postgres advisory lock can deal with this properly. The queue turns into your serialization level, which takes the race out of the equation for that specific entry sample.
Occasion-driven architectures go additional. Relatively than brokers studying from shared state, they react to occasions. Agent A completes its work and emits an occasion. Agent B listens for that occasion and picks up from there. This creates looser coupling and naturally reduces the overlap window the place two brokers is likely to be modifying the identical factor without delay.
Idempotency Is Your Greatest Good friend
Even with strong locking and queuing in place, issues nonetheless go unsuitable. Networks hiccup, timeouts occur, and brokers retry failed operations. If these retries should not idempotent, you’ll find yourself with duplicate writes, double-processed duties, or compounding errors which are painful to debug after the very fact.
Idempotency implies that operating the identical operation a number of occasions produces the identical consequence as operating it as soon as. For brokers, that usually means together with a novel operation ID with each write. If the operation has already been utilized, the system acknowledges the ID and skips the duplicate. It’s a small design alternative with a big impression on reliability.
It’s price constructing idempotency in from the beginning on the agent degree. Retrofitting it later is painful. Brokers that write to databases, replace data, or set off downstream workflows ought to all carry some type of deduplication logic, as a result of it makes the entire system extra resilient to the messiness of real-world execution.
Testing for Race Circumstances Earlier than They Take a look at You
The onerous half about race circumstances is reproducing them. They’re timing-dependent, which suggests they typically solely seem below load or in particular execution sequences which are troublesome to breed in a managed take a look at surroundings.
One helpful method is stress testing with intentional concurrency. Spin up a number of brokers in opposition to a shared useful resource concurrently and observe what breaks. Instruments like Locust, pytest-asyncio with concurrent duties, or perhaps a easy ThreadPoolExecutor may also help simulate the form of overlapping execution that exposes competition bugs in staging moderately than manufacturing.
Property-based testing is underused on this context. If you happen to can outline invariants that ought to at all times maintain no matter execution order, you may run randomized exams that try to violate them. It gained’t catch all the things, however it can floor lots of the refined consistency points that deterministic exams miss totally.
A Concrete Race Situation Instance
It helps to make this concrete. Take into account a easy shared counter that a number of brokers replace. This might characterize one thing actual, like monitoring what number of occasions a doc has been processed or what number of duties have been accomplished.
Right here’s a minimal model of the issue in pseudocode:
|
# Shared state counter = 0
# Agent process def increment_counter(): world counter worth = counter # Step 1: learn worth = worth + 1 # Step 2: modify counter = worth # Step 3: write |
Now think about two brokers operating this on the identical time:
- Agent A reads
counter = 0 - Agent B reads
counter = 0 - Agent A writes
counter = 1 - Agent B writes
counter = 1
You anticipated the ultimate worth to be 2. As an alternative, it’s 1. No errors, no warnings—simply silently incorrect state. That’s a race situation in its easiest type.
There are a number of methods to mitigate this, relying in your system design.
Possibility 1: Locking the Crucial Part
Essentially the most direct repair is to make sure that just one agent can modify the shared useful resource at a time, proven right here in pseudocode:
|
lock.purchase()
worth = counter worth = worth + 1 counter = worth
lock.launch() |
This ensures correctness, but it surely comes at the price of lowered parallelism. If many brokers are competing for a similar lock, throughput can drop shortly.
Possibility 2: Atomic Operations
In case your infrastructure helps it, atomic updates are a cleaner resolution. As an alternative of breaking the operation into read-modify-write steps, you delegate it to the underlying system:
|
counter = atomic_increment(counter) |
Databases, key-value shops, and a few in-memory methods present this out of the field. It removes the race totally by making the replace indivisible.
Possibility 3: Idempotent Writes with Versioning
One other method is to detect and reject conflicting updates utilizing versioning:
|
# Learn with model worth, model = read_counter()
# Try write success = write_counter(worth + 1, expected_version=model)
if not success: retry() |
That is optimistic locking in follow. If one other agent updates the counter first, your write fails and retries with contemporary state.
In actual multi-agent methods, the “counter” is never this easy. It is likely to be a doc, a reminiscence retailer, or a workflow state object. However the sample is similar: any time you break up a learn and a write throughout a number of steps, you introduce a window the place one other agent can intrude.
Closing that window by locks, atomic operations, or battle detection is the core of dealing with race circumstances in follow.
Ultimate Ideas
Race circumstances in multi-agent methods are manageable, however they demand intentional design. The methods that deal with them properly should not those that received fortunate with timing; they’re those that assumed concurrency would trigger issues and deliberate accordingly.
Idempotent operations, event-driven communication, good locking, and correct queue administration should not over-engineering. They’re the baseline for any pipeline the place brokers are anticipated to work in parallel with out stepping on one another. Get these fundamentals proper, and the remainder turns into way more predictable.











{kind=link}